
密度聚類和層次聚類
密度聚類
K-Means演算法、K-Means++ 演算法和Mean Shift 演算法都是基於距離的聚類演算法,基於距離的聚類演算法的聚類結果都是球狀的簇
當資料集中的聚類結果是非球狀結構是,基於距離的聚類效果並不好
基於密度的聚類演算法能夠很好的處理非球狀結構的資料,與基於距離的聚類演算法不同的是,基於密度的聚類演算法可以發現任意形狀的簇類。
在基於密度的聚類演算法中,通過在資料集中尋找別低密度區域分離的高密度區域,將分離出來的高密度區域作為一個獨立的類別。
密度聚類演算法假設聚類結構能通過樣本分佈的緊密程度確定。通常情形下,密度聚類演算法從樣本密度的角度來考察樣本之間的可連線性,並基於可連線樣本不斷擴充套件聚類簇以獲得最終的聚類結果。
DBSCAN是一種典型的基於密度的聚類演算法。,它基於一組“鄰域引數(ε,MinPts)來刻畫樣本分佈的緊密程度。
給定資料集
,定義下面幾個概念:
1)ε鄰域:對
,其ε鄰域包含資料集D中與
的距離不大於ε的樣本,即
2) 核心物件:若
的ε鄰域至少包含MinPts個樣本,即
,則
是一個核心物件
3)邊界物件:若
的ε鄰域內的樣本個數少於MinPts,但是
落在其他核心物件的ε鄰域內,則
為邊界物件
4)噪音物件:既不是核心物件也不是邊界物件的樣本點稱作噪音物件
5)密度直達:若
位於
的ε鄰域中,且
是核心物件,則稱
由
密度直達。
6)密度可達:對
,若存在樣本序列
,其中
7)密度相連:對
,若存在
使得
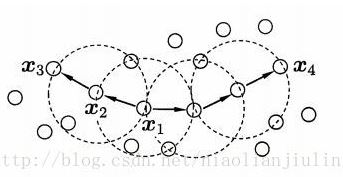
MinPts=3:虛線顯示出ε鄰域,
是核心物件,
基於這些概念,DBSCAN將簇定義為:由密度可達關係匯出的最大的密度相連樣本集合。
形式化的說,給定鄰域引數(ε,MinPts),簇C時滿足下列性質的非空樣本集:
1)連線性:
2)最大性: