
Kmeans聚類與層次聚類
聚類
聚類就是對大量未知標註的資料集,按資料的內在相似性將資料集劃分為多個類別,使類別內的資料相似度較大而類別間的資料相似度較小.
資料聚類演算法可以分為結構性或者分散性,許多聚類演算法在執行之前,需要指定從輸入資料集中產生的分類個數。
1.分散式聚類演算法,是一次性確定要產生的類別,這種演算法也已應用於從下至上聚類演算法。
2.結構性演算法利用以前成功使用過的聚類器進行分類,而分散型演算法則是一次確定所有分類。
結構性演算法可以從上至下或者從下至上雙向進行計算。從下至上演算法從每個物件作為單獨分類開始,不斷融合其中相近的物件。而從上至下演算法則是把所有物件作為一個整體分類,然後逐漸分小。
3.基於密度的聚類演算法,是為了挖掘有任意形狀特性的類別而發明的。此演算法把一個類別視為資料集中大於某閾值的一個區域。DBSCAN和OPTICS是兩個典型的演算法。
相似度/距離計算:
1.歐氏距離相似度
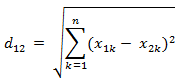
2.Jaccard相似度

3.餘弦相似度

4.Pearson相似度
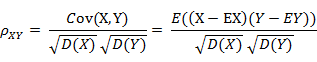
5.相對熵(K-L距離)

一.分散性聚類(kmeans)
K-均值演算法表示以空間中k個點為中心進行聚類,對最靠近他們的物件歸類。
例如:資料集合為三維,聚類以兩點:X =(x1, x2, x3),Y =(y1, y2, y3)。中心點Z變為Z =(z1, z2, z3),其中z1 = (x1 + y1)/2,z2 = (x2 + y2)/2,z3 = (x3 + y3)/2。
演算法流程:
1.選擇聚類的個數k.
2.任意產生k個聚類,然後確定聚類中心,或者直接生成k箇中心。
3.對每個點確定其聚類中心點。
4.再計算其聚類新中心。
5.重複以上步驟直到滿足收斂要求。(通常就是確定的中心點不再改變。)
K-means是初值敏感的

優點:
1.是解決聚類問題的一種經典演算法,簡單、快速
2.對處理大資料集,該演算法保持可伸縮性和高效率
3.當結果簇是密集的,它的效果較好
缺點
1.在簇的平均值可被定義的情況下才能使用,可能不適用於某些應用
2.必須事先給出k(要生成的簇的數目),而且對初值敏感,對於不同的初始值,可能會導致不同結果。
3.不適合於發現非凸形狀的簇或者大小差別很大的簇
4.對躁聲和孤立點資料敏感
二.結構性聚類(層次聚類)
層次聚類方法對給定的資料集進行層次的分解,直到某種條件滿足為止。
在已經得到距離值之後,元素間可以被聯絡起來。通過分離和融合可以構建一個結構。傳統上,表示的方法是樹形資料結構,層次聚類演算法,要麼是自底向上聚集型的,即從葉子節點開始,最終匯聚到根節點;要麼是自頂向下分裂型的,即從根節點開始,遞迴的向下分裂。
源資料:
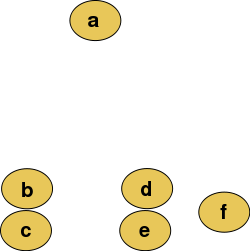
層次聚類:
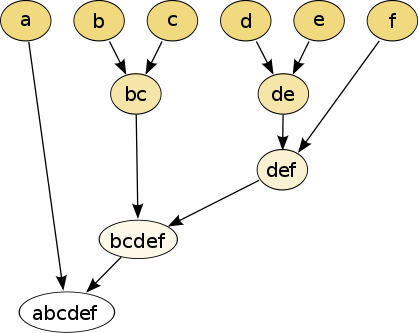
1.凝聚層次聚類:AGNES演算法(自底向上)
首先將每個物件作為一個簇,然後合併這些原子簇為越來越大的簇,直到某個終結條件被滿足
2.分裂層次聚類:DIANA演算法(自頂向下)
首先將所有物件置於一個簇中,然後逐漸細分為越來越小的簇,直到達到了某個終結條件。
k-means++演算法選擇初始seeds的基本思想就是:初始的聚類中心之間的相互距離要儘可能的遠。
相關推薦
Kmeans聚類與層次聚類
聚類 聚類就是對大量未知標註的資料集,按資料的內在相似性將資料集劃分為多個類別,使類別內的資料相似度較大而類別間的資料相似度較小. 資料聚類演算法可以分為結構性或者分散性,許多聚類演算法在執行之前,需要指定從輸入資料集中產生的分類個數。 1.分散式聚類演算法,是一次性確定要產生的類別,這種演算法也已應用於從下
聚類分析(一):K均值聚類與層次聚類
介紹三類聚類分析演算法,本篇介紹K均值聚類、層次聚類,下篇介紹圖團體(graph community)聚類。 聚類分析又稱群分析,它是研究樣本分類問題的一種統計分析方法,同時也是資料探勘的一個重要演算法。聚類分析以相似性為基礎,在一個聚類(cluster)中的
機器學習總結(十):常用聚類演算法(Kmeans、密度聚類、層次聚類)及常見問題
任務:將資料集中的樣本劃分成若干個通常不相交的子集。 效能度量:類內相似度高,類間相似度低。兩大類:1.有參考標籤,外部指標;2.無參照,內部指標。 距離計算:非負性,同一性(與自身距離為0),對稱性
模式識別設計(Python程式設計):IRIS資料集的Kmeans聚類與分解聚類法
題目:本次作業的實驗需求是使用分解聚類法與c-means聚類法對IRIS資料集進行聚類,Kmeans聚類程式碼網上摘錄,分解聚類法純原創,PS:因為時間緊,分解聚類法進行第二次分解時,偷懶了~~有緣人改改吧~~ 資料格式: kmeans程式碼: import mat
聚類分析——層次聚類
logs 較高的 bsp 分析 類對象 定義 .com blog image 聚類的定義:聚類分析將分類對象分成若幹類,相似的歸為同一類,不相似的歸為不同的類,在同一類內對象之間具有較高的相似度,不同類之間的對象差別較大。 層次聚類法: 聚類分析——層次聚類
聚類:層次聚類、基於劃分的聚類(k-means)、基於密度的聚類、基於模型的聚類
oca 基本思想 初始化 methods 根據 範圍 下使用 對象 適用於 一、層次聚類 1、層次聚類的原理及分類 1)層次法(Hierarchicalmethods)先計算樣本之間的距離。每次將距離最近的點合並到同一個類。然後,再計算類與類之間的距離,將距離最近的類合
機器學習--聚類系列--層次聚類
eight 尺度 borde 簡單 公司 span 一是 相似度 和數 層次聚類 層次聚類(Hierarchical Clustering)是聚類算法的一種,通過計算不同類別數據點間的相似度來創建一棵有層次的嵌套聚類樹。在聚類樹中,不同類別的原始數據點是樹的最低層,樹的
聚類模型-層次聚類
聚類模型 1、層次聚類 2、原型聚類-K-means 3、模型聚類-GMM 4、EM演算法-LDA主題模型 5、密度聚類-DBSCAN 6、圖聚類-譜聚類 一、層次聚類 一、聚類理論 一般來說,聚類是在訓
聚類分析層次聚類及k-means演算法
參考文獻: [1]Jure Leskovec,Anand Rajaraman,Jeffrey David Ullman.大資料網際網路大規模資料探勘與分散式處理(第二版) [M]北京:人民郵電出版社,2015.,190-199; [2]蔣盛益,李霞,鄭琪.資料探勘原理與實踐 [M]北京:電子工業出版社,20
密度聚類和層次聚類
密度聚類 K-Means演算法、K-Means++ 演算法和Mean Shift 演算法都是基於距離的聚類演算法,基於距離的聚類演算法的聚類結果都是球狀的簇 當資料集中的聚類結果是非球狀結構是,基於距離的聚類效果並不好 基於密度的聚類演算法能夠很好的處理非球狀結構的資料,與基於距離的
聚類系列-層次聚類(Hierarchical Clustering)
上篇k-means演算法卻是一種方便好用的聚類演算法,但是始終有K值選擇和初始聚類中心點選擇的問題,而這些問題也會影響聚類的效果。為了避免這些問題,我們可以選擇另外一種比較實用的聚類演算法-層次聚類演算法。顧名思義,層次聚類就是一層一層的進行聚類,可以由上向下把大的
機器學習筆記六:K-Means聚類,層次聚類,譜聚類
前面的筆記搞了那麼多的數學,這篇來一點輕鬆的,提前適應一下除了監督問題以外的非監督學習。這篇筆記有沒有前面那麼多的數學了,要講的聚類算是無監督的學習方式。 一.一般問題 聚類分析的目標是,建立滿足於同一組內的物件相似,不同組的物件相異的物件分組.它作為一種無
機器學習sklearn19.0聚類演算法——層次聚類(AGNES/DIANA)、密度聚類(DBSCAN/MDCA)、譜聚類
一、層次聚類 BIRCH演算法詳細介紹以及sklearn中的應用如下面部落格連結: http://www.cnblogs.com/pinard/p/6179132.html http://www.cnblogs.com/pinard/p/62
聚類演算法---層次聚類
假設有N個待聚類的樣本,對於層次聚類來說,步驟: 1.(初始化)把每個樣本歸為一類,計算每兩個類之間的距離,也就是樣本與樣本之間的相似度; 2.尋找各個類之間最近的兩個類,把他們歸為一類(這樣類的總數就少了一個); 3.重新計算新生成的這個類和各個舊類之間的相似度; 4.重複2和3直到所
5.2、聚類之層次聚類例項
例項二、各省消費資料 #1、載入資料 X<-data.frame( x1=c(2959.19, 2459.77, 1495.63, 1046.33, 1303.97, 1730.84, 1561.86, 1410.11, 3712.31, 2207.58, 2629.16, 184
聚類及相關演算法二(原型聚類、密度聚類、層次聚類)
原型聚類 描述:對原型進行初始化,然後對原型進行迭代更新求解。 1.k均值演算法 給定樣本集D={x1,x2,...,xm},D={x1,x2,...,xm},“k-均值”(k-means)演算法針對聚類所得簇劃分C={C1,C2,C3,...,Ck}
【機器學習】筆記之聚類Cluster—— 層次聚類 Hierarchical clustering
什麼是層次聚類Hierarchical clustering? 平面聚類是高效且概念上簡單的,但它有許多缺點。 演算法返回平坦的非結構化簇集合,需要預先指定的簇數目作為輸入並且這個數目是不確定的。 分層聚類(或分層聚類)輸出層次結構,這種結構比平面聚類返回的非結構化聚類
python(七):元類與抽象基類
imp 匿名 exec int 上下文 增加 abstract 分割 als 一、實例創建 在創建實例時,調用__new__方法和__init__方法,這兩個方法在沒有定義時,是自動調用了object來實現的。python3默認創建的類是繼承了object。 c
C++中 類與物件,類的定義,類的作用域,類中成員,this指標
概要 這篇文章主要內容是關於類與物件,類的定義,類的作用域,類中成員,this指標。寫的比較粗,後期有時間再改。 什麼是類? 對於類,我認為最早的發言人還是亞里士多德。他歸納事物的方法就是這是什麼(屬性)、能幹什麼(方式)、 起個名字(物件名) 、歸類(抽象)