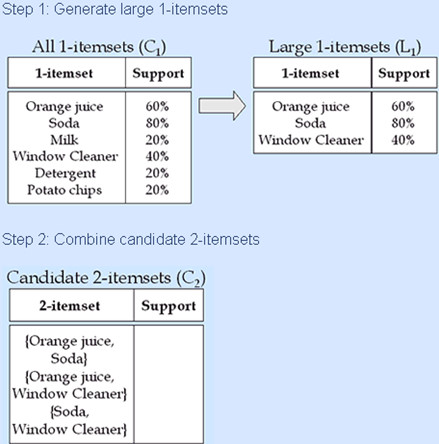
關聯分析(二)--Apriori演算法
Apriori演算法
其名字是因為演算法基於先驗知識(prior knowledge).根據前一次找到的頻繁項來生成本次的頻繁項。Apriori是關聯分析中核心的演算法。
Apriori演算法的特點
只能處理分類變數,無法處理數值型變數;
資料儲存可以是交易資料格式(事務表),或者是事實表方式(表格資料);
演算法核心在於提升關聯規則產生的效率而設計的。
Apriori的思想
正如我們之前所提到的,我們希望置信度和支援度要滿足我們的閾值範圍才算是有效的規則,實際過程中我們往往會面臨大量的資料,如果只是簡單的搜尋,會出現很多的規則,相當大的一部分是無效的規則,效率很低,那麼Apriori就是通過產生頻繁項集,然後再依據頻繁項集產生規則,進而提升效率。
以上所說的代表了Apriori演算法的兩個步驟:產生頻繁項集和依據頻繁項集產生規則。
那麼什麼是頻繁項集?
頻繁項集就是對包含專案A的專案集C,其支援度大於等於指定的支援度,則C(A)為頻繁項集,包含一個專案的頻繁項集稱為頻繁1-項集,即L1。
為什麼確定頻繁項集?
剛才說了,必須支援度大於我們指定的支援度,這也就是說能夠確定後面生成的規則是在普遍代表性上的專案集生成的,因為支援度本身的高低就代表了我們關聯分析結果是否具有普遍性。
怎麼尋找頻繁項集?
這裡不再講述,直接說一個例子大家就都明白了。例子來源於Fast Algorithms for Mining Association Rules
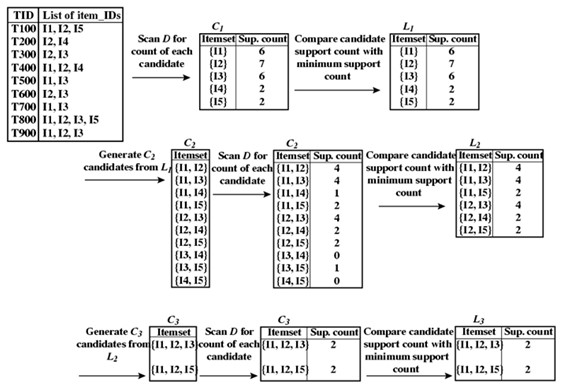
Apriori尋找頻繁項集的過程是一個不斷迭代的過程,每次都是兩個步驟,產生候選集Ck(可能成為頻繁項集的專案組合);基於候選集Ck計算支援度,確定Lk。
Apriori的尋找策略就是從包含少量的專案開始逐漸向多個專案的專案集搜尋。
資料如下:
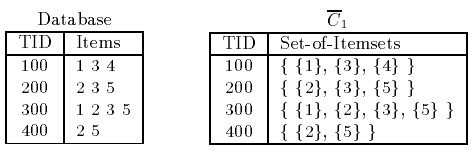
我們看到,資料庫儲存的資料格式,會員100購買了 1 3 4三種商品,那麼對應的集合形式如右邊的圖所示。那麼基於候選集C1,我們得到頻繁項集L1,如下圖所示,在此表格中{4}的支援度為1,而我們設定的支援度為2。支援度大於或者等於指定的支援度的最小閾值就成為L1了,這裡{4}沒有成為L1的一員。因此,我們認定包含4的其他項集都不可能是頻繁項集,後續就不再對其進行判斷了。
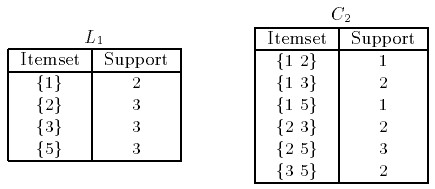
此時我們看到L1是符合最低支援度的標準的,那麼下一次迭代我們依據L1產生C2(4就不再被考慮了),此時的候選集如右圖所示C2(依據L1*L1的組合方式)確立。C2的每個集合得到的支援度對應在我們原始資料組合的計數,如下圖左所示。

此時,第二次迭代發現了{1 2} {1 5}的支援度只有1,低於閾值,故而捨棄,那麼在隨後的迭代中,如果出現{1 2} {1 5}的組合形式將不被考慮。
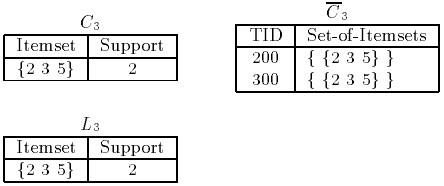
如上圖,由L2得到候選集C3,那麼這次迭代中的{1 2 3} { 1 3 5}哪去了?如剛才所言,{1 2} {1 5}的組合形式將不被考慮,因為這兩個項集不可能成為頻繁項集L3,此時L4不能構成候選集L4,即停止。
如果用一句化解釋上述的過程,就是不斷通過Lk的自身連線,形成候選集,然後在進行剪枝,除掉無用的部分。
根據頻繁項集產生簡單關聯規則
Apriori的關聯規則是在頻繁項集基礎上產生的,進而這可以保證這些規則的支援度達到指定的水平,具有普遍性和令人信服的水平。
以上就是Apriori的演算法基本原理,留了兩個例子,可以加深理解。
例子1:
例子2: