
eBay Elasticsearch 效能優化實戰-中文篇
Elasticsearch是基於Apache Lucene並具有近實時儲存、搜尋、分析資料的開源搜尋和分析引擎。雖然Elasticsearch是為快速查詢而設計,但其效能主要取決於應用場景、索引資料量和使用者查詢資料的頻率。本文總結了Pronto團隊應對的挑戰的策略。並展示了不同配置的基準測試結果。
Elasticsearch是基於Apache Lucene並具有近實時儲存、搜尋、分析資料的開源搜尋和分析引擎。Pronto是eBay託管的Elasticsearch叢集平臺,使eBay內部客戶能夠輕鬆部署、操作和擴充套件Elasticsearch以進行全文搜尋、實時分析和日誌/事件監控。
Pronto如今管理了60+叢集和2000+節點。日採集量達到180億,日均搜尋請求達35億。 Pronto平臺支援搭建、修復、安全到監控、警報和診斷全部功能。雖然Elasticsearch是為了快速查詢而設計的,但其效能主要取決於應用場景、索引資料量和使用者查詢資料的頻率。本文總結了Pronto團隊應對的挑戰的策略。並展示了不同配置的基準測試結果。
挑戰
迄今為止Pronto/Elasticsearch遇到的挑戰如下:
- 高吞吐量:有些叢集每日索引量達5TB,而有的叢集每日搜尋請求可達4億。如果Elasticsearch無法實時處理則請求將會在上游堆積。
- 低延時:叢集效能至關重要,尤其是面向站點的系統,低搜尋延遲是必須的,否則將影響使用者體驗。
- 由於資料或查詢是變化的所以最佳設定也是可變的。沒有最優設定試用於所有場景。例如,將索引分片有利於減少查詢耗時,但這可能會損害一些其他查詢效能。
解決方案
為了幫助使用者客服以上挑戰,Pronto團隊構建了用於效能測試、調優和監視的策略,從使用者提出需求開始一直存在於整個叢集生命週期。
- 分級:在一個新使用者案例接入之前,收集類似吞吐量、文件大小、文件數、搜尋型別等資訊以評估叢集初始大小。
- 優化索引設計:為使用者審查索引設計合理性
- 優化索引效能:結合場景優化索引效能和搜尋效能
- 優化搜尋效能:使用真實資料或搜尋執行效能測試,結合Elasticsearch配置引數比較和分析測試結果。
- 執行效能測試:業務上線後,叢集是被監控的,並且在資料或查詢改變、流量爆增等情況時使用者可隨時執行效能測試。
分級
Pronto團隊為每類機器和每個支援的Elasticsearch版本都執行基準測試來收集效能資料,然後使用客戶提供的資訊來評估叢集初始大小,包括:
- 索引吞吐量
- 文件數
- 搜尋吞吐量
- 查詢型別
- 熱索引文件數
- 保留策略
- 需要的響應時間
- SLA 級別
優化索引設計
在索引資料和執行查詢前請思考以下幾個問題:索引代表什麼?Elastic官方回答是“具有相似特徵的一類文件集合”。所以下個問題是“我應該使用哪個特徵對我的資料分類?將所有文件放入一個還是多個索引?答案是這取決於你的查詢。
下面是一些關於如何根據頻繁使用的查詢來組織索引的建議。
- 如果查詢有一個篩選欄位,並且其值是可列舉的,則將資料分割為多個索引。例如,你有海量全球商品資訊需要索引,而大多數查詢是都有一個“region”過濾子句,同時幾乎沒有幾乎執行跨region查詢。則查詢體可以優化:
{
"query": {
"bool": {
"must": {
"match": {
"title": "${title}"
}
},
"filter": {
"term": {
"region": "US"
}
}
}
}
}在這種場景下,我們可以根據region拆分為多個小索引以獲得更好的效能,例如US、Euro等。然後filter子句可以從查詢中刪除。如果需要跨region查詢,則可以使用多索引或者萬用字元查詢。
- 如果查詢有一個filter欄位同時該欄位不是列舉型別則可以使用路由。我們可以使用filter欄位作為路由key並移除查詢中的filter子句,這樣就可以將索引拆成多個分片。
舉個例子,現在Elasticsearch中有百萬訂單資料,同時大多數查詢是以使用者ID去排序的。因為不可能為每個使用者建立一個索引,所有我們以 使用者ID將資料劃分到多個分片中。一個合理的解決方法是將同一使用者ID的所有訂單路由到同一個分片,之後幾乎所有的查詢都可以在匹配 路由key的分片內完成。
如果查詢中有日期範圍filter則組織一下資料。這適用於大多數日誌或者監控場景。我們以日、周、月組織索引,然後可以獲得指定時間範圍內的索引列表。Elasticsearch只需要查詢一個小資料集替代索引資料。同時,當資料過期時收縮/刪除舊索引也十分方便。
顯式設定mapping。 Elasticsearch可以動態建立mapping,但這並不適用於所有場景。例如,在Elasticsearch5.x中預設string欄位同時是”keyword”和”text”型別。這在很多場景下是不需要的。
如果文件是以使用者自定義ID或者路由方式索引的請避免不平衡的分片。 Elasticsearch使用隨機生成DI和hash演算法以確保文件均勻的分配到各個分配。當你使用使用者自定義ID或者路由,ID或者可能可能不夠隨機,這樣某些索引可能會比其他索引大很多。在這種場景下,在大分片上進行讀/寫操作可能會比較慢。我們可以使用index.routing_partition_size 優化ID/路由key(5.3及以上版本)
使分片均分的分佈在節點上。 如果一個節點分片數大於其他節點,這個將比其他節點承擔更多的負載,並可能成為整個系統的瓶頸。
索引效能調優
對於類似日誌和監控的重場景索引效能是關鍵指標,以下是一些建議:
- 使用bulk請求。
- 使用多執行緒/工作傳送請求。
- 增加refresh間隔。每當refresh發生時,Elasticsearch都會建立一個新Lucene段並在之後進行合併。增加refresh間隔將減少建立/合併段的成本。 需要注意的是,文件只有在refresh之後才能被搜尋到。
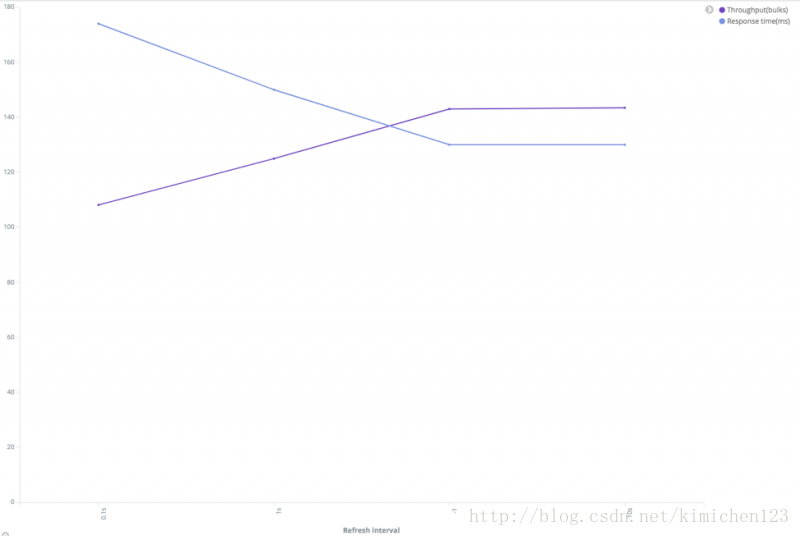
效能和refresh間隔關係
從上圖可知,隨著refresh間隔變長,叢集吞吐量增加同時響應時間變快了。可以使用以下請求來檢查段的數量以及refresh和merge花費了多少時間。
Index/_stats?filter_path= indices.**.refresh,indices.**.segments,indices.**.merges- 減少副本數。需要為每個索引請求將在文件寫入主分片和副本。顯然,大副本會降低索引速度。但定一方面,增加副本也將提高搜尋效能。我們將在之後討論這個問題。
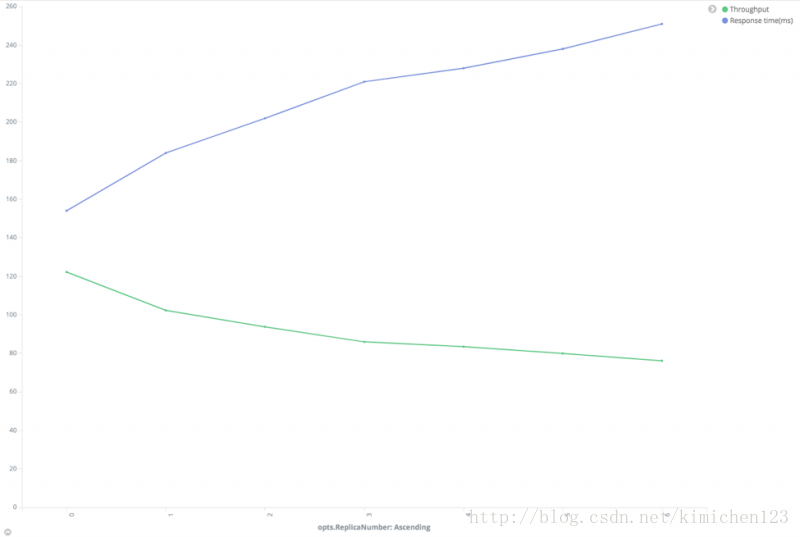
效能和副本數關係
上圖可知,隨著副本數量增加吞吐量降低,同時響應時間變長。
- 儘量使用自生成ID。 Elasticsearch自生成ID是可用保證唯一的以避免版本查詢。如果客戶真的需要自定義ID,建議選一個對Lucene友好的ID,例如 zero-padded順序ID、UUID-1和Nano時間。這些ID是一致和順序的這樣很容易壓縮。相反,類似UUID-4本質上隨機的,較差的壓縮比會降低Lucene速度。
優化搜尋效能
支援資料的搜尋是使用的Elasticsearch的一個主要原因。使用者應該能更快的定位到查詢的內容,搜尋效能取決於很多因素:
- 儘量使用filter而不是query。一個query子句可以理解成“這個文件是如何與子句匹配的”,一個filter子句可以理解成“這個文件是否匹配該子句”。Elasticsearch僅僅需要回答“yes”和“no”。它不需要計算filter子句的相關性得分,並且filter結果可以被快取。詳見Query and filter context。
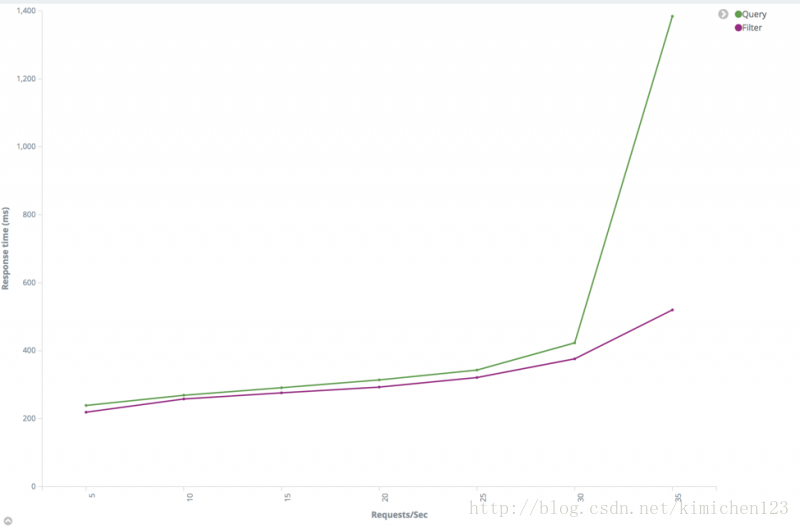
query和filter 比較
增加refresh間隔。 正如 tune indexing performance 提到的,Elasticsearch每次重新整理都會建立一個新的段。增加refresh間隔將有助於減少段的數量並降低搜尋IO。而且一旦發生refresh並且資料改變,快取將無效。增加refresh間隔將使得Elasticsearch高效的利用快取。
增加副本數。 Elasticsearch Elasticsearch 可以在主或副本上執行搜尋。副本越多,可搜尋的節點就越多。
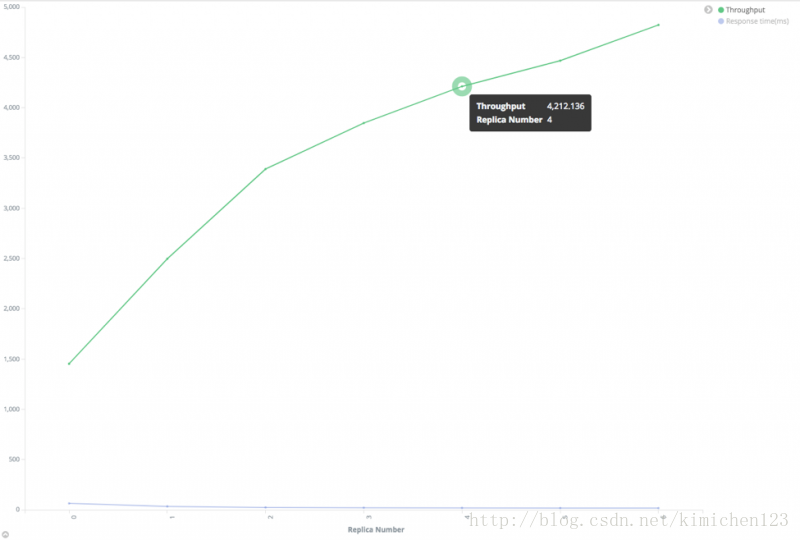
效能和副本關係
上圖可知,搜尋吞吐量與副本數幾乎是線性相關的。注意到在這個測試中,測試叢集有足夠的資料節點來確保每個分片都有一個獨佔節點,如果這個條件不能滿足,搜尋吞吐量就不會很好。
- 嘗試不同的分片數。 “應該為索引設定多少分片?”這可能是最長討論的問題。不幸的是,所有場景都沒有標準,而這完全取決於實際情況。
太少的分片數不利於搜尋擴充套件。例如,如果分片資料為1,則索引中所有文件都將儲存在一個分片中,這樣每次搜尋都在同一個節點。如果有很多文件則十分耗時。同時,索引分配太多對效能有危害,因為Elasticsearch需要在所有分片上執行查詢,除非指定了路由鍵,然後抓取和合並將返回所有資料。
根據經驗,如果索引小於1G,將分片設為1沒什麼問題。在大多數場景下我們可以保留預設為5的分片數量,但是當分片大小超過30GB,應該增加分片數以將索引拆分到更多的分片。建立索引後分片數不能改變,但是可以建立新索引並使用redinexAPI來遷移資料。
我們對一個擁有大約一億個文件的150G左右大小的索引進行測試,使用100個執行緒以傳送搜尋請求。
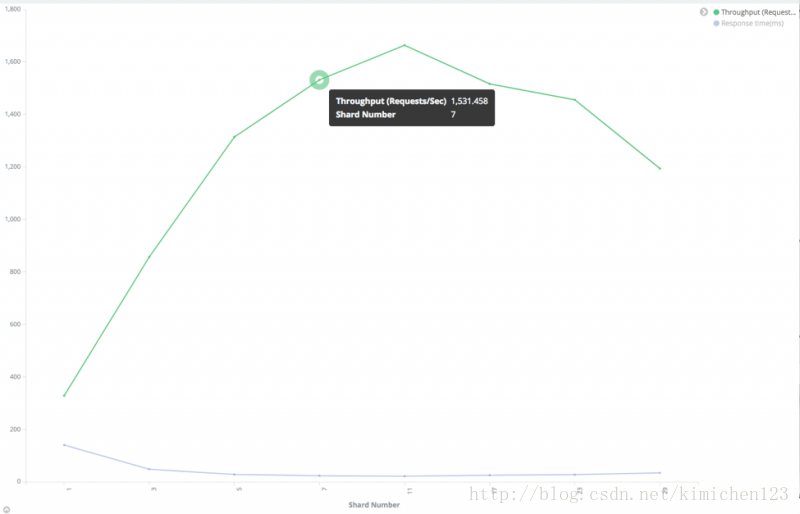
效能與分片數的關係
從上圖可知,我們發現最優的分片數是11。開始搜尋吞吐量是在上升(響應時間變快),但是隨著分片數持續增加搜尋吞吐量便開始下降。
需要注意的是,正如副本數測試一樣,每個分片獨佔一個節點。如果這種條件不能滿足,搜尋吞吐量就不會得到上圖那樣好的效果。
在這種情況下,建議嘗試一個小於優化值得分片數,因為每個分片獨佔一個節點時意味著更多的分片需要更多的節點。
- 結點query快取。Node query cache 只快取filter情景下的查詢。與query子句不同的是,一個filter子句僅僅是“yes”和“no”的問題。Elasticsearch使用bit位機制來快取filter結果,使得在之後的查詢使用相同的filter時可以快速命中。需要注意的是一個段的文件數超過10000(或者文件總數的3%,以較大的值為準)才能啟用query快取。更多細節詳見All about caching。
可以使用以下請求檢驗節點查詢快取是否有效。
GET index_name/_stats?filter_path=indices.**.query_cache
{
"indices": {
"index_name": {
"primaries": {
"query_cache": {
"memory_size_in_bytes": 46004616,
"total_count": 1588886,
"hit_count": 515001,
"miss_count": 1073885,
"cache_size": 630,
"cache_count": 630,
"evictions": 0
}
},
"total": {
"query_cache": {
"memory_size_in_bytes": 46004616,
"total_count": 1588886,
"hit_count": 515001,
"miss_count": 1073885,
"cache_size": 630,
"cache_count": 630,
"evictions": 0
}
}
}
}
}分片query快取。 如果大多數查詢是聚合查詢,我們應該看一下 shard query cache, 它可以快取聚合結果以便Elasticsearch以更小的成本處理請求。不過以下幾件事情需要注意:
– 設定”size”:0。分片query快取只快取聚合結合和建議。他不會快取命中結果,所以如果你將size設為非0則無法從快取中受益。
– Payload JSON 必須一致。分片query快取使用JSON體作為快取鍵,所以需要保證JSON體不變且JSON中的鍵順序一致。
– Round 日期時間。不要使用類似Date.now這種變數,Round它否則每個請求都會有一個不同的payload 體,從而使得快取無效。我們建議round日期時間為小時或天以有效利用快取。
我們可以使用以下請求來建議分片query快取是否有效。
GET index_name/_stats?filter_path=indices.**.request_cache
{
"indices": {
"index_name": {
"primaries": {
"request_cache": {
"memory_size_in_bytes": 0,
"evictions": 0,
"hit_count": 541,
"miss_count": 514098
}
},
"total": {
"request_cache": {
"memory_size_in_bytes": 0,
"evictions": 0,
"hit_count": 982,
"miss_count": 947321
}
}
}
}
}只返回需要的欄位。如果穩定很大而只需要少數幾個欄位,使用 stored_fields 獲得需要的欄位而不是所有欄位。
避免搜尋停用詞。 類似“a” 和“the” 可能會導致結果爆炸。假設你有一百萬穩定,搜尋“fox”可能返回幾十個結果,但是搜尋“the fox”可能會返回所有的文件,因為“the”幾乎在所有文件中都有出現。Elasticsearch需要對所有的結果集進行評分排序,像”the fox”這種查詢可能會降低整體系統的效能。可以使用停用詞庫移除停用詞,或者使用“and”將“the fox“查詢改寫成“ the AND fox”以獲得更準確的結果。
如果某些詞在在索引中經常使用但不在停用詞列表中,可以使用cutoff-frequency 來動態處理。如果不關心文件返回順序則按_doc排序。 Elasticsearch預設使用“_score” 欄位排序。如果你不關心順序,可以使用 “sort”: “_doc” 讓Elasticsearch按索引順序排序。
避免在返回中使用script query計算,最好是索引時將計算結果儲存。 例如,有一個索引儲存大量使用者資訊,我們想查詢一“1234”開頭的所有使用者,我們可以使用script query執行”source”: “doc[‘num’].value.startsWith(‘1234’).” 這個查詢十分耗資源並會降低整個叢集的速度。可以考慮在索引時加一個”num_prefix” 欄位。這樣我們在查詢時只需要 “name_prefix”: “1234.”
避免萬用字元查詢。
執行效能測試
對於每次變化,都需要執行效能測試來驗證是否合適。因為Elasticsearch是一個restful服務,所以可以使用類似Rally,Apache Jmeter和Gatling等工具來執行效能測試。因為Pronto團隊需要在每類機器和Elasticsearch版本上進行大量基準測試,而且需要在大量叢集上配置Elasticsearch引數執行效能測試,因此這些工具並不難滿足我們的需求。
Pronto團隊構建了基於 Gatling 的線上效能分析服務以幫助客戶執行效能測試和迴歸。該服務支援一下功能:
- 輕鬆新增/編輯實驗。使用者可以根據自己的輸入查詢或文件結構生成測試,同時不需要Gatling或Scala知識。
- 無需人工干預順序執行多個測試。它會檢查狀態並在每次測試前後更高Elasticsearch設定。
- 幫助使用者比較和分析測試結果。實驗期間的結果和叢集資訊會持久化並可通過Kibana分析。
- 使用命令列或web UI執行測試。Rest API也提供了與其他系統的整合功能。
架構圖如下:
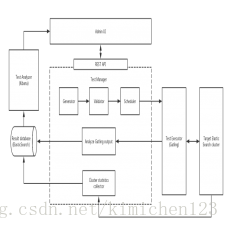
效能測試服務架構 (click to enlarge diagram)
使用者可以查詢每個測試的Gatling報告,也可以檢視Kibana預定義的視覺化結果以進行分析比較,介面如下:
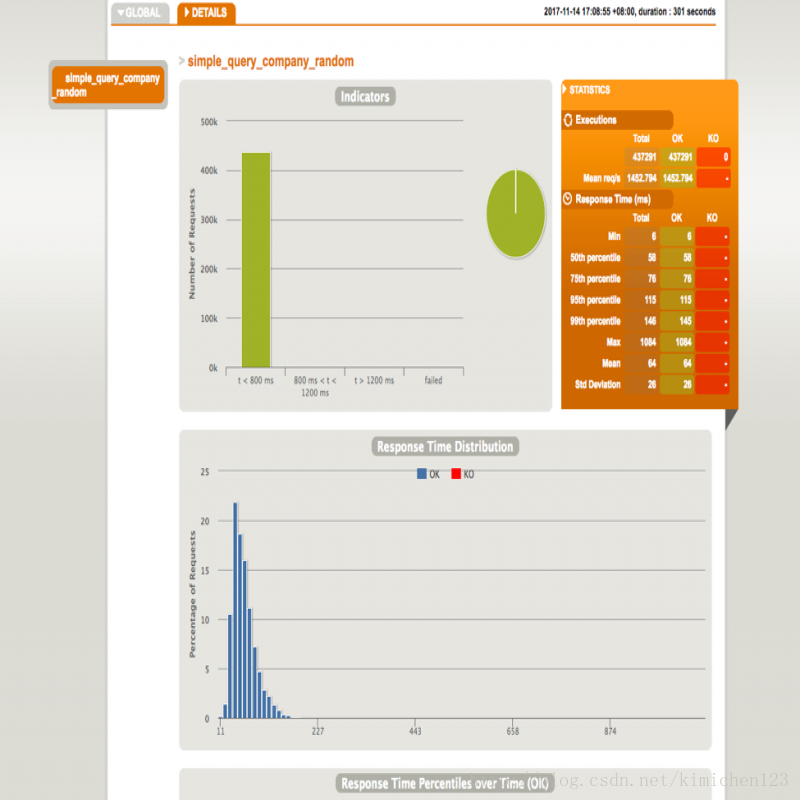
Gatling 報告
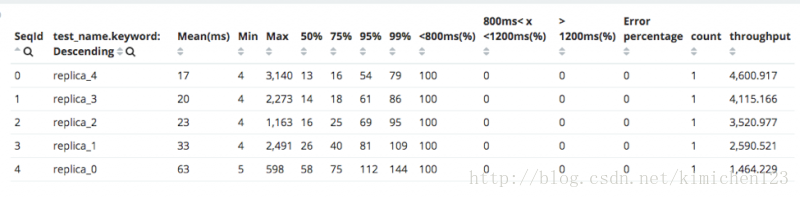
Gatling 報告
總結
本文總結了在設計高攝取和搜尋效能Elasticsearch叢集時索引/分片/副本設計和一些其他配置。同時還指出Pronto團隊如何幫助客戶初始化大小,索引設計和效能調優。截止到現在,Pronto團隊已經幫助包括訂單管理系統(OMS)和搜尋引擎優化(SEO)等大量客戶的壓合要求,從而為eBay的核心業務貢獻出力。
Elasticsearch效能取決於很多因素,包括文件結構,文件大小,索引設定/mappingt,請求率,資料集大小,查詢命中率等。一個場景的效能優化並不一定適用另一場景。全面的效能測試,蒐集資料,根據負載優化配置,優化叢集以滿足效能要求則十分重要。
TOPICS: Performance Engineering, Search Science
Previous Post:Beyond HTTPS