
ROC曲線與AUC--模型評價指標
阿新 • • 發佈:2019-01-08
ROC(Receiver Operating Characteristic)
主要分析工具是一個畫在二維平面上的曲線——ROC curve。
平面的橫座標是 false positive rate(FPR),縱座標是 true positive rate(TPR)。
相關概念
True Positive Rate(真正率 , TPR)或靈敏度(sensitivity)
TPR=正樣本預測結果數正樣本實際數TPR=TPTP+FN
False Positive Rate (假正率, FPR)
FPR=被預測為正的負樣本結果數負樣本實際數 FPR=FPFP+TNFalse Negative Rate(假負率 , FNR)
FNR=FNTP+FN
True Negative Rate(真負率 , TNR)或特指度(specificity)
TNR=負樣本預測結果數負樣本實際數TNR=TNTN+FP
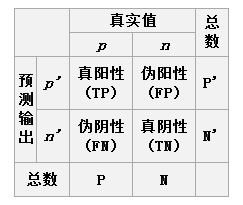
提出ROC的原因
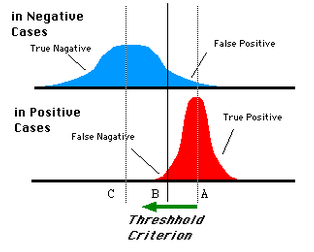
由分類器決定的統計的影象是固定的,但是由於閾值不同,我們可以得到不同的,TPR,FPR,TNR,FNR值。因此我們需要找到一個獨立於閾值,只和分類器有關的衡量分類器的標準。還有是在樣本正負樣本不平衡的情況下更好的評估分類器的效能。
AUC (Area Under roc Curve)
AUC是一種用來度量分類模型好壞的一個標準,Auc作為數值可以直觀的評價分類器的好壞,值越大越好。
幾何意義:
R OC
影象下方的面積
物理意義:
取出一個正樣本與一個負樣本,正樣本的Score大於負樣本的Score的概率,Score表示置信度
計算AUC
方法一:直接計算下方的面積,比較麻煩,需要計算若干個梯形的面積的和。
方法二:計算正樣本score大於負樣本的score的概率,時間複雜度為O(N∗M)
方法三:將所有的樣本按照score升序排序,依次用rank表示他們,如最大score的樣本,rank=n(n=N+M),其次為n-1。那麼對於正樣本中rank最大的樣本,rank_max,有M-1個其他正樣本比他score小,那麼就有(rank_max-1)-(M-1)個負樣本比他score小。其次為(rank_second-1)-(M-2)。
Code
#-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.metrics import roc_auc_score
def calc_auc(df):
Score = sorted(df.values, key=lambda a_entry: a_entry[1])
N = 0;M = 0
for item in Score:
if item[0] == 0:
N += 1
else:
M += 1
Sigma = 0
for i in range(N+M-1,-1,-1):
if Score[i][0] == 1:
Sigma += i+1
return float((Sigma-M*(M+1)/2.0)/(N*M))
def main():
df = pd.read_csv('./data.csv',header=None)
Ports = list(enumerate(np.unique(df[0])))
Ports_dict ={label : i for i,label in Ports}
df[0]=df[0].map(lambda x : Ports_dict[x]).astype(int)
print roc_auc_score(df[0].values,df[1].values)
print calc_auc(df)
if __name__ == '__main__':
main()data
p,0.9
p,0.8
p,0.6
n,0.7
p,0.54
p,0.55
n,0.53
n,0.52
p,0.51
n,0.505
p,0.4
n,0.39
p,0.38
n,0.37
n,0.36
n,0.35
p,0.34
n,0.33
p,0.3
n,0.1