強化學習--QLearning
阿新 • • 發佈:2019-01-08
1.概述:
QLearning基於值函式的方法,不同與policy gradient的方法,Qlearning是預測值函式,通過值函式來選擇
值函式最大的action,而policy gradient直接預測出action。
2一些定義
2.1值函式
Given an actor π, it evaluates how good the actor is
有2種值函式,V(S) 、Q(s,a).
2.1.1 V(S)

有2種衡量的方法:

MC方法只能等玩完一個episode才能進行統計評價,效率比較低。

TD方法可以每玩一步就更新一次。
mc與td對比,mc需要估計的是一個episode的值函式,方差比較大,而td是與時間相關的,只有r是需要估計的,方差比較小。
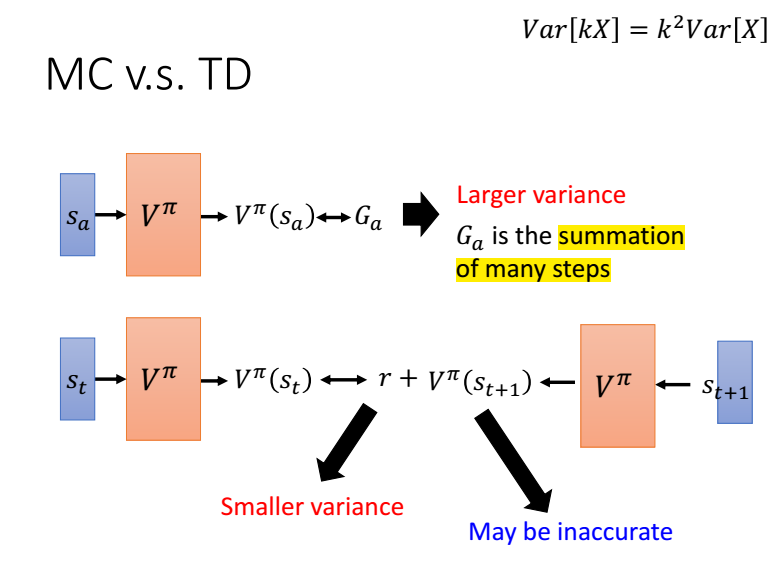
下面看一下例子:
V(Sb)=6/8=1
MC: V(Sa)=0/2=0
TD: V(Sa)=V(Sb)+0=3/4

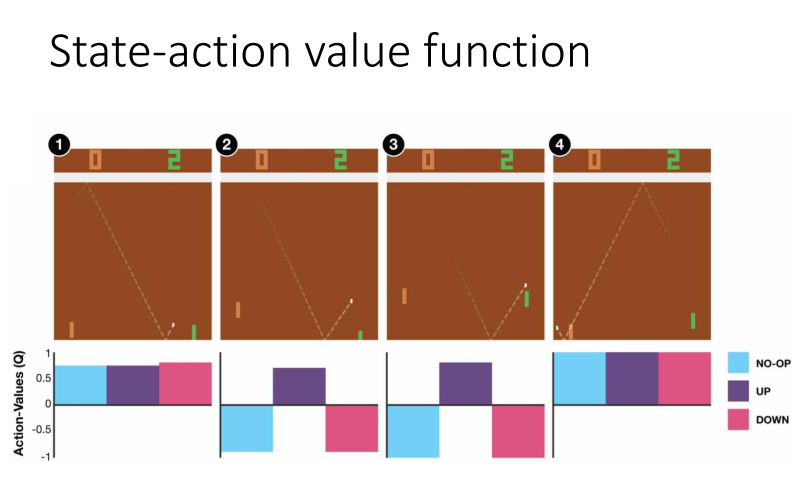
2.1.2 Q(s,a)
我們可以評估,在當前狀態s,採取行動a,在接下來的遊戲中獲得得獎勵累計和的期望為Q(s,a)。但在接下來的遊戲中,
不一定採取行動a,而是採取Q值最大的行動。

下圖中1,無論採取那個行動都無所謂,因為離球還很遠,而圖2離球比較近了,我們需要向上接到球,接下來遊戲才能獲得獎勵。