
吳恩達機器學習筆記_第三週
Logistic Regression邏輯迴歸(分類):
0:Negative Class
1:Positive Class
二元分類問題講起,雖然有迴歸二字,其實為分類演算法,處理離散y值。
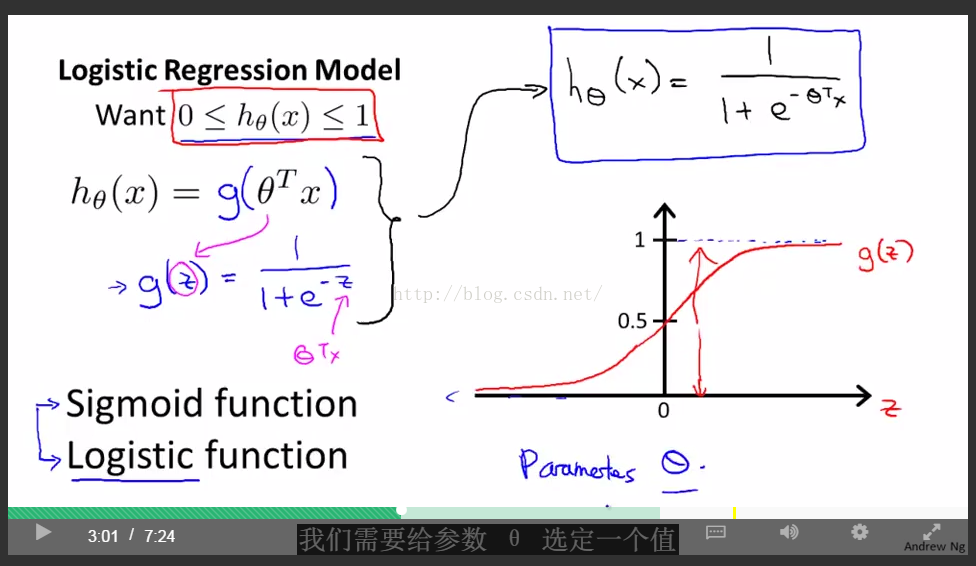
輸出以以條件概率表示,若P(y=1|x;theta)= 0.7,表示有70%的概率y=1.那麼有30%的概率y=0
決策邊界(DecisionBoundary):當z=0,即thetaT*X的值等於零時,此時假設函式為0.5。

下面是另一個邊界的例子:

只要得到theta值,就能得到決策邊界
邏輯迴歸的代價函式很可能是一個非凸函式(non-convex),有很多區域性最優點,所以如果用梯度下降法,不能保證會收斂到全域性最小值。
單次的代價函式如下:
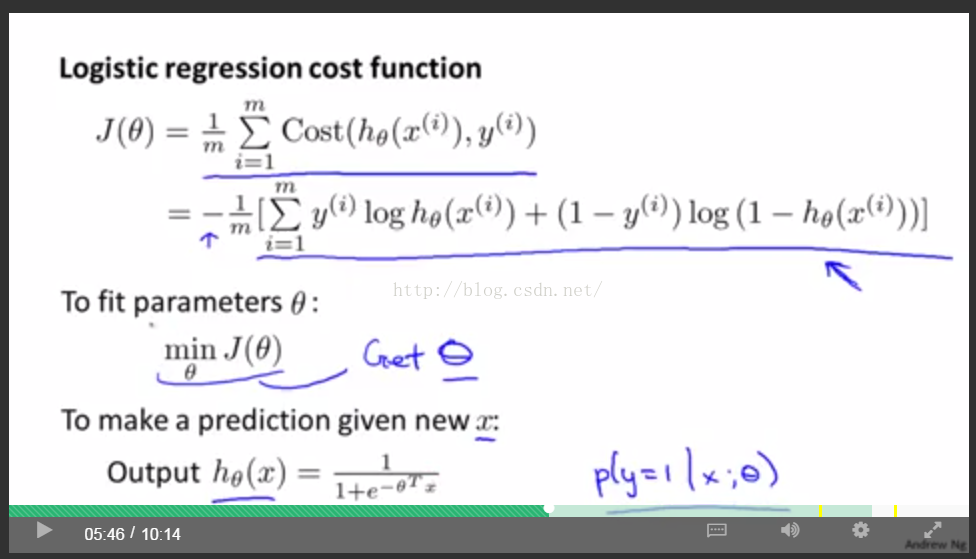
最終多樣本的代價函式以及我們要做的工作:

根據前面的方法,同時地進行梯度下降法求出theta向量。
優化方法:共軛梯度、BFGS等等,無需選學習率,自動的,比梯度下降快,但是複雜。建議直接呼叫庫。
多元分類:
1對多方法

h函式其實就對應著條件概率,所以就是訓練三個分類器,選條件概率最高的。
過擬合問題overfitting——正則化Regulation
對訓練資料效果很好,但無法對新資料進行很好的預測,泛化能力弱,就是一般性不好
引數過多,高階項多等。
解決方法:
1、減少特徵數量(找主要的,或者用演算法找)
2、正則化(保留所有引數,但較少維度或數量級)
正則化項:加入引數過多的懲罰,其中lamda是控制正則化引數
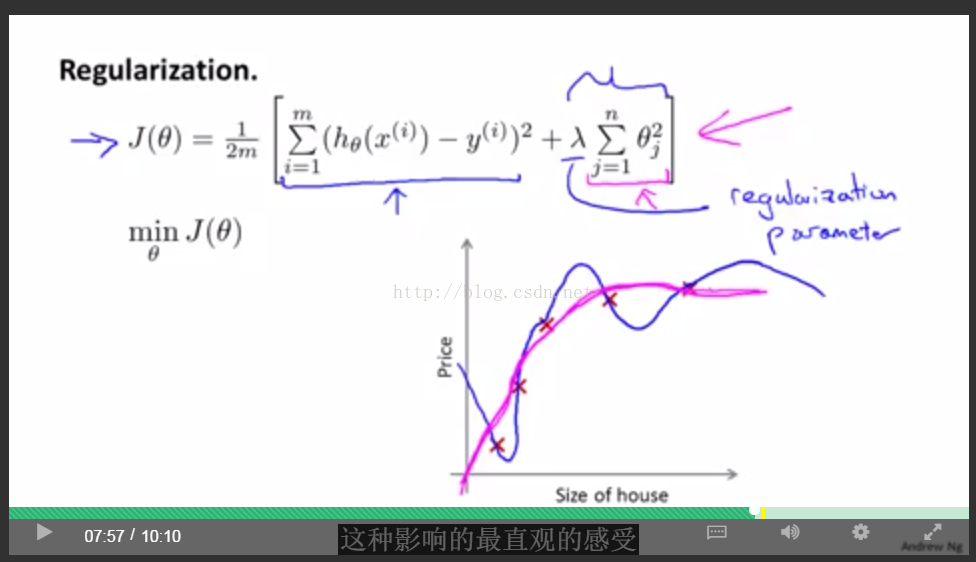
lamda過大,容易造成欠擬合underfitting,相當於所有theta都約等於0,只剩第一項。
正則化線性迴歸:正則化+梯度下降結合:

不懲罰theta0,所以分開寫
正規化方法加上正則化項後的求法:

正則化邏輯迴歸:
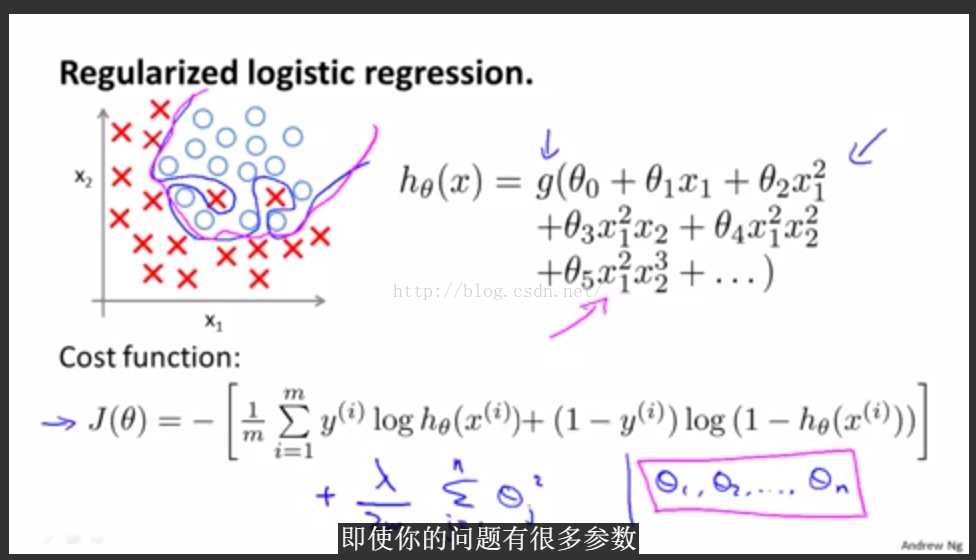
用梯度下降法的修改和線性迴歸形式一樣,只是h函式不一樣