
RCNN學習筆記(7):Faster R-CNN 英文論文翻譯筆記
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
reference link:http://blog.csdn.net/liumaolincycle/article/details/48804687摘要
目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet[7]和Fast R-CNN[5]這些網路已經減少了檢測網路的執行時間,這時計算區域建議就成了瓶頸問題。本文中,我們介紹一種區域建議網路(Region Proposal Network, RPN)
1.引言
最近在目標檢測中取得的進步都是由區域建議方法(例如[22])和基於區域的卷積神經網路(R-CNN)[6]取得的成功來推動的。基於區域的CNN在[6]中剛提出時在計算上消耗很大,幸好後來這個消耗通過建議框之間共享卷積[7,5]大大降低了。最近的Fast R-CNN[5]用非常深的網路[19]實現了近實時檢測的速率,注意它忽略了生成區域建議框的時間。現在,建議框是最先進的檢測系統中的計算瓶頸
區域建議方法典型地依賴於消耗小的特徵和經濟的獲取方案。選擇性搜尋(Selective Search, SS)[22]是最流行的方法之一,它基於設計好的低階特徵貪心地融合超級畫素。與高效檢測網路[5]相比,SS要慢一個數量級,CPU應用中大約每個影象2s。EdgeBoxes[24]在建議框質量和速度之間做出了目前最好的權衡,大約每個影象0.2s。但無論如何,區域建議步驟花費了和檢測網路差不多的時間。
Fast R-CNN利用了GPU,而區域建議方法是在CPU上實現的,這個執行時間的比較是不公平的。一種明顯提速生成建議框的方法是在GPU上實現它,這是一種工程上很有效的解決方案,但這個方法忽略了其後的檢測網路,因而也錯失了共享計算的重要機會
本文中,我們改變了演算法——用深度網路計算建議框——這是一種簡潔有效的解決方案,建議框計算幾乎不會給檢測網路的計算帶來消耗。為了這個目的,我們介紹新穎的區域建議網路(Region Proposal Networks, RPN),它與最先進的目標檢測網路[7,5]共享卷積層。在測試時,通過共享卷積,計算建議框的邊際成本是很小的(例如每個影象10ms)。
我們觀察發現,基於區域的檢測器例如Fast R-CNN使用的卷積(conv)特徵對映,同樣可以用於生成區域建議。我們緊接著這些卷積特徵增加兩個額外的卷積層,構造RPN:第一個層把每個卷積對映位置編碼為一個短的(例如256-d)特徵向量,第二個層在每個卷積對映位置,輸出這個位置上多種尺度和長寬比的k個區域建議的objectness得分和迴歸邊界(k=9是典型值)。
我們的RPN是一種全卷積網路(fully-convolutional network, FCN)[14],可以針對生成檢測建議框的任務端到端地訓練。為了統一RPN和Fast R-CNN[5]目標檢測網路,我們提出一種簡單的訓練方案,即保持建議框固定,微調區域建議和微調目標檢測之間交替進行。這個方案收斂很快,最後形成可讓兩個任務共享卷積特徵的標準網路。
我們在PASCAL VOC檢測標準集[4]上評估我們的方法, fast R-CNN結合RPN的檢測準確率超過了作為強大基準的fast R-CNN結合SS的方法。同時,我們的方法沒有了SS測試時的計算負擔,對於生成建議框的有效執行時間只有10毫秒。利用[19]中網路非常深的深度模型,我們的檢測方法在GPU上依然有5fps的幀率(包括所有步驟),因此就速度和準確率(PASCAL VOC 2007上是73.2%mAP,PASCAL VOC 2012上是70.4%)而言,這是一個實用的目標檢測系統。程式碼已公開。
2.相關工作
最近幾篇文章中提出了用深度網路定位類確定或類不確定的包圍盒[21, 18, 3, 20] 的方法。在OverFeat方法[18]中,訓練全連線(fc)層,對假定只有一個目標的定位任務預測包圍盒座標。fc層再轉入卷積層來檢測多個類確定的目標。MultiBox方法[3, 20]從最後一個fc層同時預測多個(如800)包圍盒的網路中生成區域建議,R-CNN[6]就是用的這個。他們的建議框網路應用於單個影象或多個大影象的切割部分(如224x224)[20]。我們在後文中講我們的方法時會更深層次地討論OverFeat和MultiBox。
卷積的共享計算[18, 7, 2, 5]高效、精確,已經在視覺識別方面吸引了越來越多的注意。OverFeat論文[18]從影象金字塔計算卷積特徵,用於分類、定位、檢測。在共享的卷積特徵對映上自適應大小的pooling(SPP)[7]能有效用於基於區域的目標檢測[7, 16]和語義分割[2]。Fast R-CNN[5]實現了在共享卷積特徵上訓練的端到端檢測器,顯示出令人驚歎的準確率和速度。
3.區域建議網路
區域建議網路(RPN)將一個影象(任意大小)作為輸入,輸出矩形目標建議框的集合,每個框有一個objectness得分。我們用全卷積網路[14]對這個過程構建模型,本章會詳細描述。因為我們的最終目標是和Fast R-CNN目標檢測網路[15]共享計算,所以假設這兩個網路共享一系列卷積層。在實驗中,我們詳細研究Zeiler和Fergus的模型[23](ZF),它有5個可共享的卷積層,以及Simonyan和Zisserman的模型[19](VGG),它有13個可共享的卷積層。
為了生成區域建議框,我們在最後一個共享的卷積層輸出的卷積特徵對映上滑動小網路,這個網路全連線到輸入卷積特徵對映的nxn的空間視窗上。每個滑動視窗對映到一個低維向量上(對於ZF是256-d,對於VGG是512-d,每個特徵對映的一個滑動視窗對應一個數值)。這個向量輸出給兩個同級的全連線的層——包圍盒迴歸層(reg)和包圍盒分類層(cls)。本文中n=3,注意影象的有效感受野很大(ZF是171畫素,VGG是228畫素)。圖1(左)以這個小網路在某個位置的情況舉了個例子。注意,由於小網路是滑動視窗的形式,所以全連線的層(nxn的)被所有空間位置共享(指所有位置用來計算內積的nxn的層引數相同)。這種結構實現為nxn的卷積層,後接兩個同級的1x1的卷積層(分別對應reg和cls),ReLU[15]應用於nxn卷積層的輸出。
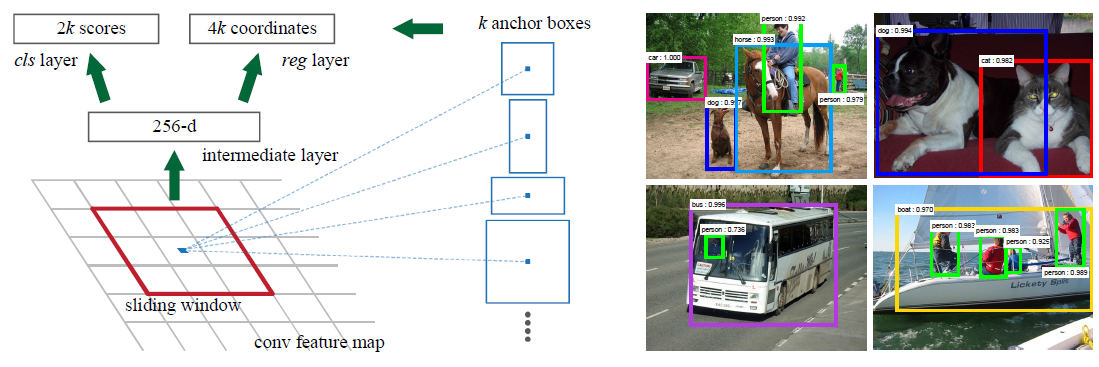
圖1:左:區域建議網路(RPN)。右:用RPN建議框在PASCAL VOC 2007測試集上的檢測例項。我們的方法可以在很大範圍的尺度和長寬比中檢測目標。
平移不變的anchor
在每一個滑動視窗的位置,我們同時預測k個區域建議,所以reg層有4k個輸出,即k個box的座標編碼。cls層輸出2k個得分,即對每個建議框是目標/非目標的估計概率(為簡單起見,是用二類的softmax層實現的cls層,還可以用logistic迴歸來生成k個得分)。k個建議框被相應的k個稱為anchor的box引數化。每個anchor以當前滑動視窗中心為中心,並對應一種尺度和長寬比,我們使用3種尺度和3種長寬比,這樣在每一個滑動位置就有k=9個anchor。對於大小為WxH(典型值約2,400)的卷積特徵對映,總共有WHk個anchor。我們的方法有一個重要特性,就是平移不變性,對anchor和對計算anchor相應的建議框的函式而言都是這樣。
作為比較,MultiBox方法[20]用k-means生成800個anchor,但不具有平移不變性。如果平移了影象中的目標,建議框也應該平移,也應該能用同樣的函式預測建議框。此外,因為MultiBox的anchor不具有平移不變性,所以它需要(4+1)x800-d的輸出層,而我們的方法只要(4+2)x9-d的輸出層。我們的建議框層少一個數量級的引數(MultiBox用GoogleLeNet[20]需要2700萬vs.RPN用VGG-16需要240萬),這樣在PASCAL
VOC這種小資料集上出現過擬合的風險較小。
學習區域建議的損失函式
為了訓練RPN,我們給每個anchor分配一個二進位制的標籤(是不是目標)。我們分配正標籤給兩類anchor:(i)與某個ground truth(GT)包圍盒有最高的IoU(Intersection-over-Union,交集並集之比)重疊的anchor(也許不到0.7),(ii)與任意GT包圍盒有大於0.7的IoU交疊的anchor。注意到一個GT包圍盒可能分配正標籤給多個anchor。我們分配負標籤給與所有GT包圍盒的IoU比率都低於0.3的anchor。非正非負的anchor對訓練目標沒有任何作用。
有了這些定義,我們遵循Fast R-CNN[5]中的多工損失,最小化目標函式。我們對一個影象的損失函式定義為 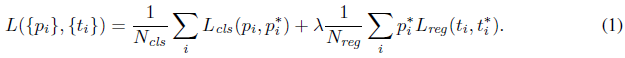
這裡,i是一個mini-batch中anchor的索引,Pi是anchor i是目標的預測概率。如果anchor為正,GT標籤Pi* 就是1,如果anchor為負,Pi* 就是0。ti是一個向量,表示預測的包圍盒的4個引數化座標,ti* 是與正anchor對應的GT包圍盒的座標向量。分類損失*Lcls是兩個類別(目標vs.非目標)的對數損失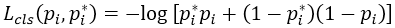
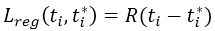
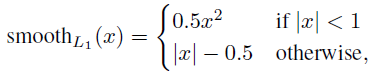
Pi* Lreg這一項意味著只有正anchor(Pi* =1)才有迴歸損失,其他情況就沒有(Pi* =0)。cls層和reg層的輸出分別由{pi}和{ti}組成,這兩項分別由Ncls和Nreg以及一個平衡權重λ歸一化(早期實現及公開的程式碼中,λ=10,cls項的歸一化值為mini-batch的大小,即Ncls=256,reg項的歸一化值為anchor位置的數量,即Nreg~2,400,這樣cls和reg項差不多是等權重的。
對於迴歸,我們學習[6]採用4個座標: 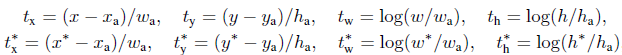
x,y,w,h指的是包圍盒中心的(x, y)座標、寬、高。變數x,xa,x*分別指預測的包圍盒、anchor的包圍盒、GT的包圍盒(對y,w,h也是一樣)的x座標。可以理解為從anchor包圍盒到附近的GT包圍盒的包圍盒迴歸。
無論如何,我們用了一種與之前的基於特徵對映的方法[7, 5]不同的方法實現了包圍盒演算法。在[7, 5]中,包圍盒迴歸在從任意大小的區域中pooling到的特徵上執行,迴歸權重是所有不同大小的區域共享的。在我們的方法中,用於迴歸的特徵在特徵對映中具有相同的空間大小(nxn)。考慮到各種不同的大小,需要學習一系列k個包圍盒迴歸量。每一個迴歸量對應於一個尺度和長寬比,k個迴歸量之間不共享權重。因此,即使特徵具有固定的尺寸/尺度,預測各種尺寸的包圍盒仍然是可能的。
優化
RPN很自然地實現為全卷積網路[14],通過反向傳播和隨機梯度下降(SGD)[12]端到端訓練。我們遵循[5]中的“image-centric”取樣策略訓練這個網路。每個mini-batch由包含了許多正負樣本的單個影象組成。我們可以優化所有anchor的損失函式,但是這會偏向於負樣本,因為它們是主要的。因此,我們隨機地在一個影象中取樣256個anchor,計算mini-batch的損失函式,其中取樣的正負anchor的比例是1:1。如果一個影象中的正樣本數小於128,我們就用負樣本填補這個mini-batch。
我們通過從零均值標準差為0.01的高斯分佈中獲取的權重來隨機初始化所有新層(最後一個卷積層其後的層),所有其他層(即共享的卷積層)是通過對ImageNet分類[17]預訓練的模型來初始化的,這也是標準慣例[6]。我們調整ZF網路的所有層,以及conv3_1,併為VGG網路做準備,以節約記憶體[5]。我們在PASCAL資料集上對於60k個mini-batch用的學習率為0.001,對於下一20k個mini-batch用的學習率是0.0001。動量是0.9,權重衰減為0.0005[11]。我們的實現使用了Caffe[10]。
區域建議與目標檢測共享卷積特徵
迄今為止,我們已經描述瞭如何為生成區域建議訓練網路,而沒有考慮基於區域的目標檢測CNN如何利用這些建議框。對於檢測網路,我們採用Fast R-CNN[5],現在描述一種演算法,學習由RPN和Fast R-CNN之間共享的卷積層。
RPN和Fast R-CNN都是獨立訓練的,要用不同方式修改它們的卷積層。因此我們需要開發一種允許兩個網路間共享卷積層的技術,而不是分別學習兩個網路。注意到這不是僅僅定義一個包含了RPN和Fast R-CNN的單獨網路,然後用反向傳播聯合優化它那麼簡單。原因是Fast R-CNN訓練依賴於固定的目標建議框,而且並不清楚當同時改變建議機制時,學習Fast R-CNN會不會收斂。雖然這種聯合優化在未來工作中是個有意思的問題,我們開發了一種實用的4步訓練演算法,通過交替優化來學習共享的特徵。
第一步,我們依上述訓練RPN,該網路用ImageNet預訓練的模型初始化,並端到端微調用於區域建議任務。第二步,我們利用第一步的RPN生成的建議框,由Fast R-CNN訓練一個單獨的檢測網路,這個檢測網路同樣是由ImageNet預訓練的模型初始化的,這時候兩個網路還沒有共享卷積層。第三步,我們用檢測網路初始化RPN訓練,但我們固定共享的卷積層,並且只微調RPN獨有的層,現在兩個網路共享卷積層了。第四步,保持共享的卷積層固定,微調Fast
R-CNN的fc層。這樣,兩個網路共享相同的卷積層,構成一個統一的網路。
實現細節
我們訓練、測試區域建議和目標檢測網路都是在單一尺度的影象上[7, 5]。我們縮放影象,讓它們的短邊s=600畫素[5]。多尺度特徵提取可能提高準確率但是不利於速度與準確率之間的權衡[5]。我們也注意到ZF和VGG網路,對縮放後的影象在最後一個卷積層的總步長為16畫素,這樣相當於一個典型的PASCAL影象(~500x375)上大約10個畫素(600/16=375/10)。即使是這樣大的步長也取得了好結果,儘管若步長小點準確率可能得到進一步提高。
對於anchor,我們用3個簡單的尺度,包圍盒面積為128x128,256x256,512x512,和3個簡單的長寬比,1:1,1:2,2:1。注意到,在預測大建議框時,我們的演算法考慮了使用大於基本感受野的anchor包圍盒。這些預測不是不可能——只要看得見目標的中間部分,還是能大致推斷出這個目標的範圍。通過這個設計,我們的解決方案不需要多尺度特徵或者多尺度滑動視窗來預測大的區域,節省了相當多的執行時間。圖1(右)顯示了我們的演算法處理多種尺度和長寬比的能力。下表是用ZF網路對每個anchor學到的平均建議框大小(s=600)。

跨越影象邊界的anchor包圍盒要小心處理。在訓練中,我們忽略所有跨越影象邊界的anchor,這樣它們不會對損失有影響。對於一個典型的1000x600的影象,差不多總共有20k(~60x40x9)anchor。忽略了跨越邊界的anchor以後,每個影象只剩下6k個anchor需要訓練了。如果跨越邊界的異常值在訓練時不忽略,就會帶來又大又困難的修正誤差項,訓練也不會收斂。在測試時,我們還是應用全卷積的RPN到整個影象中,這可能生成跨越邊界的建議框,我們將其裁剪到影象邊緣位置。
有些RPN建議框和其他建議框大量重疊,為了減少冗餘,我們基於建議區域的cls得分,對其採用非極大值抑制(non-maximum suppression, NMS)。我們固定對NMS的IoU閾值為0.7,這樣每個影象只剩2k個建議區域。正如下面展示的,NMS不會影響最終的檢測準確率,但是大幅地減少了建議框的數量。NMS之後,我們用建議區域中的top-N個來檢測。在下文中,我們用2k個RPN建議框訓練Fast R-CNN,但是在測試時會對不同數量的建議框進行評價。
4.實驗
我們在PASCAL VOC2007檢測基準[4]上綜合評價我們的方法。此資料集包括20個目標類別,大約5k個trainval影象和5k個test影象。我們還對少數模型提供PASCAL VOC2012基準上的結果。對於ImageNet預訓練網路,我們用“fast”版本的ZF網路[23],有5個卷積層和3個 fc層,公開的VGG-16 模型[19],有13 個卷積層和3 個fc層。我們主要評估檢測的平均精度(mean Average Precision, mAP),因為這是對目標檢測的實際度量標準(而不是側重於目標建議框的代理度量)。
表1(上)顯示了使用各種區域建議的方法訓練和測試時Fast R-CNN的結果。這些結果使用的是ZF網路。對於選擇性搜尋(SS)[22],我們用“fast”模式生成了2k個左右的SS建議框。對於EdgeBoxes(EB)[24],我們把預設的EB設定調整為0.7IoU生成建議框。SS的mAP 為58.7%,EB的mAP 為58.6%。RPN與Fast R-CNN實現了有競爭力的結果,當使用300個建議框時的mAP就有59.9%(對於RPN,建議框數量,如300,是一個影象產生建議框的最大數量。RPN可能產生更少的建議框,這樣建議框的平均數量也更少了)。使用RPN實現了一個比用SS或EB更快的檢測系統,因為有共享的卷積計算;建議框較少,也減少了區域方面的fc消耗。接下來,我們考慮RPN的幾種消融,然後展示使用非常深的網路時,建議框質量的提高。
表1 PASCAL VOC2007年測試集的檢測結果(在VOC2007 trainval訓練)。該檢測器是Fast R-CNN與ZF,但使用各種建議框方法進行訓練和測試。
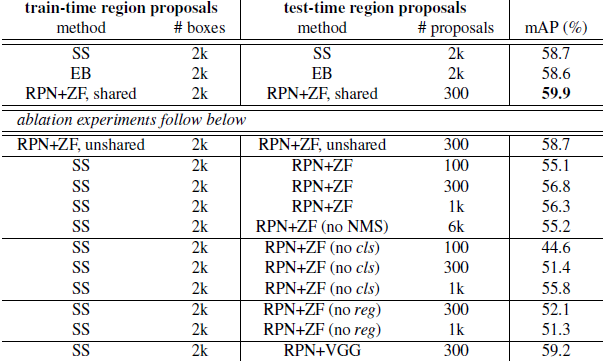
消融試驗。為了研究RPN作為建議框方法的表現,我們進行了多次消融研究。首先,我們展示了RPN和Fast R-CNN檢測網路之間共享卷積層的影響。要做到這一點,我們在4步訓練過程中的第二步後停下來。使用分離的網路時的結果稍微降低為58.7%(RPN+ ZF,非共享,表1)。我們觀察到,這是因為在第三步中,當調整過的檢測器特徵用於微調RPN時,建議框質量得到提高。
接下來,我們理清了RPN在訓練Fast R-CNN檢測網路上的影響。為此,我們用2k個SS建議框和ZF網路訓練了一個Fast R-CNN模型。我們固定這個檢測器,通過改變測試時使用的建議區域,評估檢測的mAP。在這些消融實驗中,RPN不與檢測器共享特徵。
在測試時用300個RPN建議框替換SS,mAP為56.8%。mAP的損失是訓練/測試建議框之間的不一致所致。該結果作為以下比較的基準。
有些奇怪的是,在測試時使用排名最高的100個建議框時,RPN仍然會取得有競爭力的結果(55.1%),表明這種高低排名的RPN建議框是準確的。另一種極端情況,使用排名最高的6k個RPN建議框(沒有NMS)取得具有可比性的mAP(55.2%),這表明NMS不會降低檢測mAP,反而可以減少誤報。
接下來,我們通過在測試時分別移除RPN的cls和reg中的一個,研究它們輸出的作用。當在測試時(因此沒有用NMS/排名)移除cls層,我們從沒有計算得分的區域隨機抽取N個建議框。N =1k 時mAP幾乎沒有變化(55.8%),但當N=100則大大降低為44.6%。這表明,cls得分是排名最高的建議框準確的原因。
另一方面,當在測試時移除reg層(這樣的建議框就直接是anchor框了),mAP下降到52.1%。這表明,高品質的建議框主要歸功於迴歸後的位置。單是anchor框不足以精確檢測。
我們還評估更強大的網路對RPN的建議框質量的作用。我們使用VGG-16訓練RPN,並仍然使用上述SS+ZF檢測器。mAP從56.8%(使用RPN+ZF)提高到59.2%(使用RPN+VGG)。這是一個滿意的結果,因為它表明,RPN+VGG的建議框質量比RPN+ZF的更好。由於RPN+ZF的建議框是可與SS競爭的(訓練和測試一致使用時都是58.7%),我們可以預期RPN+VGG比SS好。下面的實驗證明這一假說。
VGG-16的檢測準確率與執行時間。表2展示了VGG-16對建議框和檢測的結果。使用RPN+VGG,Fast R-CNN對不共享特徵的結果是68.5%,比SS基準略高。如上所示,這是因為由RPN+VGG產生的建議框比SS更準確。不像預先定義的SS,RPN是實時訓練的,能從更好的網路獲益。對特徵共享的變型,結果是69.9%——比強大的SS基準更好,建議框幾乎無損耗。我們跟隨[5],在PASCAL VOC2007 trainval和2012 trainval的並集上進一步訓練RPN,mAP是73.2%。跟[5]一樣在VOC
2007 trainval+test和VOC2012 trainval的並集上訓練時,我們的方法在PASCAL VOC 2012測試集上(表3)有70.4%的mAP。
表2:在PASCAL VOC 2007測試集上的檢測結果,檢測器是Fast R-CNN和VGG16。訓練資料:“07”:VOC2007 trainval,“07+12”:VOC 2007 trainval和VOC 2012 trainval的並集。對RPN,用於Fast R-CNN訓練時的建議框是2k。這在[5]中有報告;利用本文所提供的倉庫(repository),這個數字更高(68.0±0.3在6次執行中)。
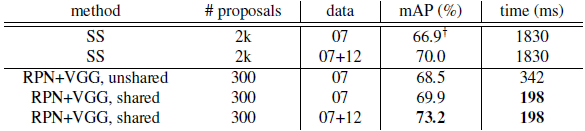
表3:PASCAL VOC 2012測試集檢測結果。檢測器是Fast R-CNN和VGG16。訓練資料:“07”:VOC 2007 trainval,“07++12”: VOC 2007 trainval+test和VOC 2012 trainval的並集。對RPN,用於Fast R-CNN訓練時的建議框是2k。
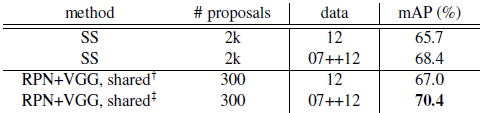
表4中我們總結整個目標檢測系統的執行時間。SS需要1~2秒,取決於影象內容(平均1.51s),採用VGG-16的Fast R-CNN在2k個SS建議框上需要320ms(若是用了SVD在fc層的話只用223ms[5])。我們採用VGG-16的系統生成建議框和檢測一共只需要198ms。卷積層共享時,RPN只用10ms來計算附加的幾層。由於建議框較少(300),我們的區域計算花費也很低。我們的系統採用ZF網路時的幀率為17fps。
表4: K40 GPU上的用時(ms),除了SS建議框是在CPU中進行評價的。“區域方面”包括NMS,pooling,fc和softmax。請參閱我們釋出的程式碼執行時間的分析。

IoU召回率的分析。接下來,我們計算建議框與GT框在不同的IoU比例時的召回率。值得注意的是,該IoU召回率度量標準與最終的檢測準確率只是鬆散[9, 8, 1]相關的。更適合用這個度量標準來診斷建議框方法,而不是對其進行評估。
在圖2中,我們展示使用300,1k,和2k個建議框的結果。我們將SS和EB作比較,並且這N個建議框是基於用這些方法生成的按置信度排名的前N個。該圖顯示,當建議框數量由2k下降到300時,RPN方法的表現很好。這就解釋了使用少到300個建議框時,為什麼RPN有良好的最終檢測mAP。正如我們前面分析的,這個屬性主要是歸因於RPN的cls項。當建議框變少時,SS和EB的召回率下降的速度快於RPN。
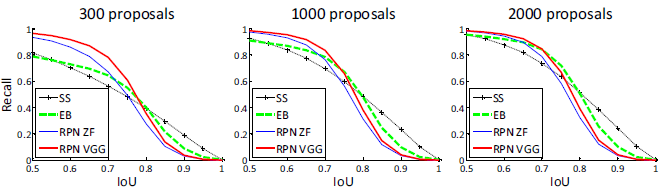
圖2:PASCAL VOC 2007測試集上的召回率 vs. IoU重疊率
**單級的檢測vs. 兩級的建議框+檢測。**OverFeat論文[18]提出在卷積特徵對映的滑動視窗上使用迴歸和分類的檢測方法。OverFeat是一個單級的,類特定的檢測流程,我們的是一個兩級的,由類無關的建議框方法和類特定的檢測組成的級聯方法。在OverFeat中,區域方面的特徵來自一個滑動視窗,對應一個尺度金字塔的一個長寬比。這些特徵被用於同時確定物體的位置和類別。在RPN中,特徵都來自相對於anchor的方形(3*3)滑動視窗和預測建議框,是不同的尺度和長寬比。雖然這兩種方法都使用滑動視窗,區域建議任務只是RPN
+ Fast R-CNN的第一級——檢測器致力於改進建議框。在我們級聯方法的第二級,區域一級的特徵自適應地從建議框進行pooling[7, 5],更如實地覆蓋區域的特徵。我們相信這些特徵帶來更準確的檢測。
為了比較單級和兩級系統,我們通過單級的Fast R-CNN模擬OverFeat系統(因而也規避實現細節的其他差異)。在這個系統中,“建議框”是稠密滑動的,有3個尺度(128,256,512)和3個長寬比(1:1,1:2,2:1)。Fast R-CNN被訓練來從這些滑動視窗預測特定類的得分和迴歸盒的位置。由於OverFeat系統採用多尺度的特徵,我們也用由5個尺度中提取的卷積特徵來評價。我們使用[7,5]中一樣的5個尺度。
表5比較了兩級系統和兩個單級系統的變體。使用ZF模型,單級系統具有53.9%的mAP。這比兩級系統(58.7%)低4.8%。這個實驗證明級聯區域建議方法和目標檢測的有效性。類似的觀察報告在[5,13]中,在兩篇論文中用滑動視窗取代SS區域建議都導致了約6%的下降。我們還注意到,單級系統比較慢,因為它有相當多的建議框要處理。
表5:單級檢測vs.兩級建議+檢測。檢測結果都是在PASCAL VOC2007測試集使用ZF模型和Fast R-CNN。RPN使用非共享的特徵。

5.總結
我們對高效和準確的區域建議的生成提出了區域建議建議網路(RPN)。通過與其後的檢測網路共享卷積特徵,區域建議的步驟幾乎是無損耗的。我們的方法使一個一致的,基於深度學習的目標檢測系統以5-17 fps的速度執行。學到的RPN也改善了區域建議的質量,進而改善整個目標檢測的準確性。
表6:Fast R-CNN檢測器和VGG16在PASCAL VOC 2007測試集的結果。對於RPN,Fast R-CNN訓練時的建議框是2k個。RPN*表示非共享特徵的版本。*

表7:Fast R-CNN檢測器和VGG16在PASCAL VOC 2012測試集的結果。對於RPN,Fast R-CNN訓練時的建議框是2k個。

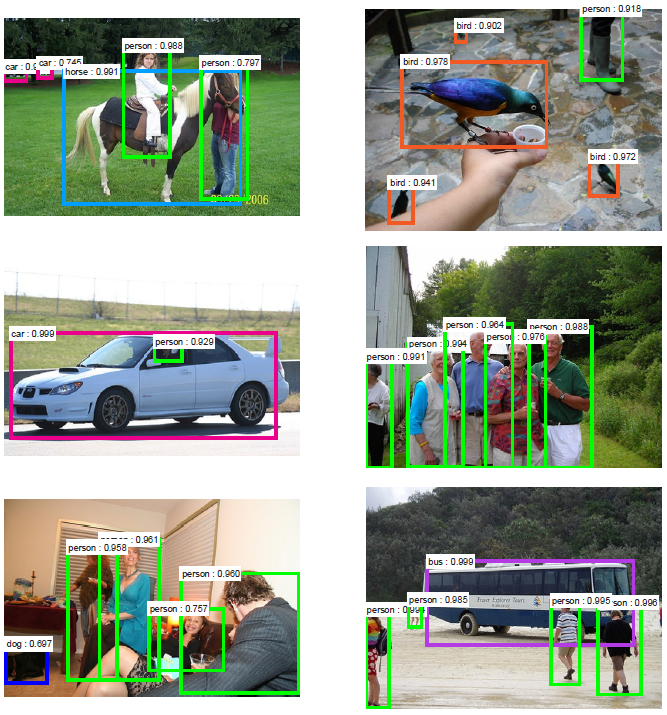




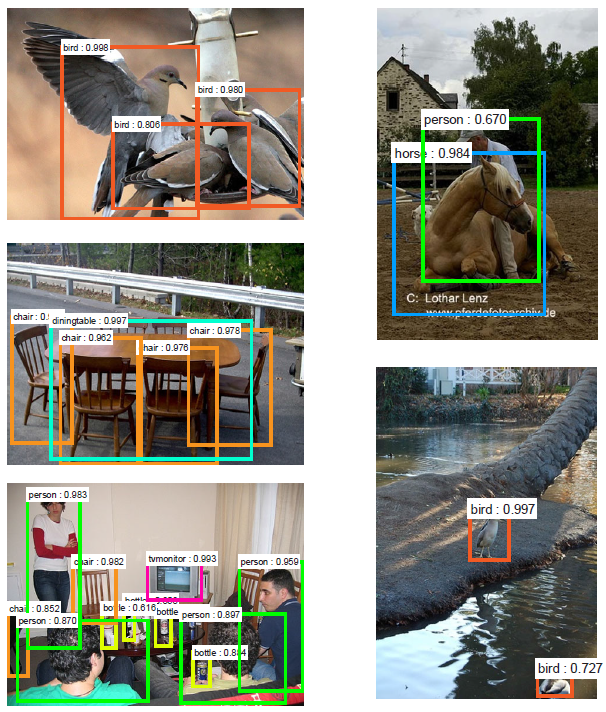
圖3:對最終的檢測結果使用具有共享特徵的RPN + FastR-CNN在PASCAL VOC 2007測試集上的例子。模型是VGG16,訓練資料是07 + 12trainval。我們的方法檢測的物件具有範圍廣泛的尺度和長寬比。每個輸出框與一個類別標籤和一個範圍在[0,1]的softmax得分相關聯。顯示這些影象的得分閾值是0.6。取得這些結果的執行時間是每幅影象198ms,包括所有步驟。
引用
[1] N. Chavali, H. Agrawal, A. Mahendru, and D. Batra. Object-Proposal Evaluation Protocol is ’Gameable’. arXiv: 1505.05836, 2015.
[2] J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. In CVPR, 2015.
[3] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.
[4] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results, 2007.
[5] R. Girshick. Fast R-CNN. arXiv:1504.08083, 2015.
[6] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[7] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
[8] J. Hosang, R. Benenson, P. Doll´ar, and B. Schiele. What makes for effective detection proposals? arXiv:1502.05082, 2015.
[9] J. Hosang, R. Benenson, and B. Schiele. How good are detection proposals, really? In BMVC, 2014.
[10] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093, 2014.
[11] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[12] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard,W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989.
[13] K. Lenc and A. Vedaldi. R-CNN minus R. arXiv:1506.06981, 2015.
[14] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[15] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
[16] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. arXiv:1504.06066, 2015.
[17] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. arXiv:1409.0575, 2014.
[18] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[19] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[20] C. Szegedy, S. Reed, D. Erhan, and D. Anguelov. Scalable, high-quality object detection. arXiv:1412.1441v2, 2015.
[21] C. Szegedy, A. Toshev, and D. Erhan. Deep neural networks for object detection. In NIPS, 2013.
[22] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A.W. Smeulders. Selective search for object recognition. IJCV, 2013.
[23] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional neural networks. In ECCV, 2014.
[24] C. L. Zitnick and P. Doll´ar. Edge boxes: Locating object proposals from edges. In ECCV, 2014.