
R-CNN、Fast-R-CNN和Faster-R-CNN
R-CNN:針對區域提取做CNN的object detction。
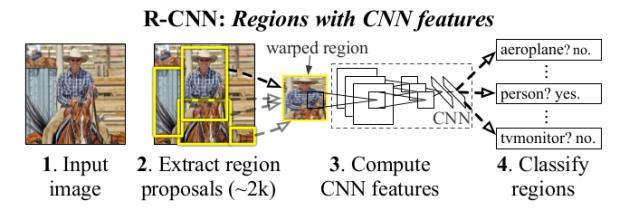 -----------------
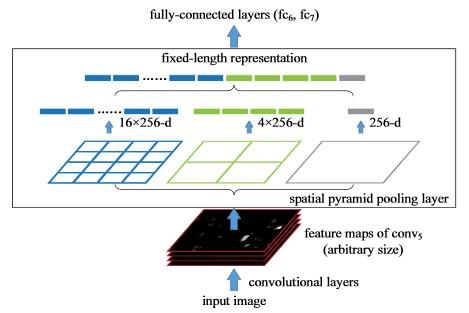
-----------------SPPNet:針對不同尺寸輸入圖片,在CNN之後的Feature Map上進行相同維度的區域分割並Pooling,轉化成相同尺度的向量。但是分類用的是SVM。
 -------------------------
-------------------------Fast R-CNN:區域提取轉移到Feature Map之後做,這樣不用對所有的區域進行單獨的CNN Forward步驟。同時最終一起迴歸bounding box和類別。
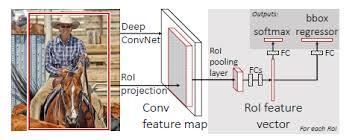 ------------------------
------------------------1.為什麼做Faster-rcnn
a. SPPnet 和 Fast R-CNN 已經減少了detection步驟的執行時間,只剩下region proposal成為瓶頸
b. 因此提出了 Region Proposal Network(RPN) 用來提取檢測區域,並且和整個檢測網路共享卷積部分的特徵。RPN同時訓練區域的邊界和objectness score(理解為是否可信存在oject)。
c. 最終把RPN和Fast-RCNN合併在一起,用了“attention” mechanisms(其實就是說共享這事)。在VOC資料集上可以做到每張圖只提300個proposals(Fast-RCNN用selective search是2000個)。
2.繼續闡述現存問題
Fast-RCNN已經做到了Region Proposal在卷積以後,這樣大大減少了卷積作用的次數,全圖的Feature Map提取同樣只是做一次。目前最大的問題就是 Selective Search是耗時的瓶頸(CPU上大概2s一張)。尤其是這個方法沒有應用在GPU上,優化比較難。RPN共享網路,可以做到每張10ms,並且一起在GPU上進行了。
3.具體網路構建
在前面全圖Feature Map的基礎上, RPN又增加了幾個卷積層和FC層。是一種可以END-to-END訓練的FullyConvNet(其實就說單獨訓練RPN自己的這些層)。為了統一RPN和Fast R-CNN的網路,具體實現就是在RPN和Fast-RCNN之間選擇性切換,實際各訓練了兩次。最終結果,即使選擇了VGG裡最複雜的網路,仍然可以做到5fps的速度。
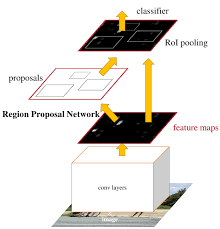
實現的時候,前面feature map之前的網路是shareable convolutional layers(VGG有13層,ZF有5層,不同的模型不一樣)。RPN的具體實現就不說了,3x3尺寸的filter,卷積一層,後面幾個FC,假如每個點上proposal k種不同的尺度和比例(論文裡定義k=9),輸出就有4*k的尺度資訊(位置2維,長寬各一維)和2*k的判斷資訊(是否是object)。RPN的一個重大優點在於translation invariant,因為是針對各個點周圍3X3進行獨立卷積的,後面的 RPN整個網路的權重又是共享的。而如果MultiBox方法的話,核心k-means很難保有這種獨立性,畢竟object的位置在圖上都是隨機的。另外現有的Region Proposal方法基本上是構建image pyramid或者是filter pyramid的基礎上,這裡就是真的實現了Single filter,Single scale。
4.LOSS定義和訓練過程
Loss Function定義包括幾個部分,RPN訓練的尺度資訊的邊框(bounding box)部分,每個點對應的k個anchors裡和ground truth IoU的overlap最大的標記為正,或者與任何IoU的overlap超過0.7也標記為正。每一個ground truth的box可能會標記給多個anchor。如果anchor與IoU的overlap小於0.3將被標記為負。本身傳統方法,IoU在處理bounding的時候,就是所有RP出來的區域類似於先scale到相同尺寸進行預測,共享預測部分的網路的權重,但是在這裡反而是每個feature map點周圍的3X3區域各進行k個不同權重的scale和size的訓練。 RPN訓練用的是每個batch來自單張圖的proposal。但是各個圖佔主要部分的negative samples會產生很大的bias。於是每次每張圖選擇256個隨機的anchors,並且保證postive和negative的anchors比例為1:1。RPN本身的部分高斯隨機初始化而來,共享部分來自ImageNet之前的訓練結果。後面decay,learning rate什麼的就不詳細說了。訓練過程就是固定一部分,訓練一部分,RPN和Fast-RCNN交叉著來,定義了很多種,Caffe裡實現的,也不具體說了。
----------------------------------------------------------------------------------------------------
首先膜拜RBG大神,這周以前我是不知道這個人的,之前我一直想用移動機器人帶攝像頭做一些實時object detection的任務,其實自動駕駛上很多人在做了,行人檢測什麼的。但是我對CNN的作用還一直停留在全圖做image classification上。萬萬沒想到,RBG一個人把DPM,以及後來整個object detection的所有任務鏈全部用CNN實現了(也不能說一個人,還有MSRA的幾個華人大牛)。
同時之前我對Caffe的認識也一直停留在C++和命令列介面呼叫上,今天看了一下py-faster-rcnn的原始碼,簡直對Caffe有了全新的認識(RBG畢竟也參與了Caffe的開發)。希望早日把原始碼搞透,然後試著把Faster-RCNN用在檢測其他特定物體的任務上。(原始碼學習,個人Blog緩慢更新中Faster R-CNN · Tai Lei Home Page,坑太大,一時半會填不滿)。