深度學習——RNN初識
資料
1.快速瞭解視訊(bilibili莫凡視訊)
https://www.bilibili.com/video/av15998703?from=search&seid=4200091979965196821
2. 詳細介紹:
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
源起
沒有十全十美的神經網路,每一個都有對應的特色。So,產生了各種各樣的 Neural Network,來處理對應的各種各樣的問題。從最基礎的basic neural network(全連結),不考慮空間結構,且假設所有元素點或資料點獨立,只是按照一定層次的結構組合成網路結構,就能實現常人感到不可思議的事情,如人工智慧的Hello World——手寫字識別。再看CNN,當人們開始思考,全連結神經網路雖然好,但卻忽略了空間結構這一重要概念,全連線構造時,僅僅將所有畫素點排成一列,而忽略了其他,這怎麼可以,所以,CNN來了。思考並未停止,等到某一天,人們不在基於圖片,開始圍繞時間二字,開始衝擊資料點獨立二字,RNN的是時代來臨了。
什麼是RRN
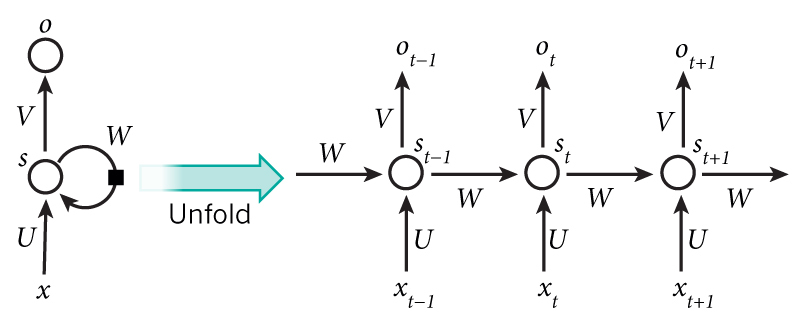
正如每種Neural Network都有一種結構,RNN的結構是這個樣子。僅僅這個結構就有很多資訊。此文為記錄文(僅僅記錄自己的所得和重要的東西),所以(http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/)
Note:
1.As briefly mentioned above, it’s a bit more complicated in practice because

2.Unlike a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters (
沒有嘗試去翻譯兩句話,因為英文描述的很清楚裡。RNN框架的特性,權重相同,不能記憶太多代。
RNN能幹什麼
1.語言建模與生成文字
在語言建模中,我們的輸入通常是一系列單詞(例如編碼為單熱向量),我們的輸出是預測單詞的序列。在訓練我們設定的網路時,

2.機器翻譯
機器翻譯類似於語言建模,因為我們的輸入是源語言中的一系列單詞(例如德語)。我們希望以目標語言輸出一系列單詞(例如英語)。一個關鍵的區別是我們的輸出僅在我們看到完整輸入後才開始,因為我們翻譯的句子的第一個單詞可能需要從完整的輸入序列中捕獲的資訊。
3.語音識別
給定來自聲波的聲學訊號的輸入序列,我們可以預測一系列語音片段及其概率。
4.生成影象描述
與卷積神經網路一起,RNN已被用作模型的一部分,以生成未標記影象的描述。令人驚訝的是,這看起來有多好。組合模型甚至將生成的單詞與影象中找到的特徵對齊。
5.Training RNNs
in order to calculate the gradient at 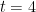
6.RNN擴充套件
雙向RNN基於以下思想:時間上的輸出
深度(雙向)RNN類似於雙向RNN,只是我們現在每個時間步長有多個層。在實踐中,這為我們提供了更高的學習能力(但我們還需要大量的培訓資料)。
LSTM網路 現在非常流行,我們在上面簡要討論了它們。LSTM與RNN沒有根本不同的架構,但它們使用不同的函式來計算隱藏狀態。LSTM中的記憶體稱為單元格,您可以將它們視為黑框,將以前的狀態