
深度學習——DNN反向傳播
理解鏈式求導
網站連結:https://www.bilibili.com/video/av10435213?from=search&seid=5523894613383510820
膜拜大神,我就知道,這位大神不會讓我失望,這視訊弄得我無話可說,想理清楚的思路全都有,最關鍵的是要學習大神的思考方法——那驚為天人的視覺化。
為什麼寫這篇文章:
看到了一篇很具有邏輯性的證明部落格,自己又有很多東西想記一下,不然忘了也不知道去哪兒找。
DNN反向傳播
1.導論
以前寫過一篇總結性的文章,照著《深度學習與神經網路》這本書以及別人的筆記邊學邊寫,結果發現自己處於半懂半不懂的狀態,那時候把程式碼看的差不多,並碼了一遍以後,就沒有放在心上。直到自己看到卷積,再次面向CNN的反向傳播演算法,才突然醒悟,自己應該去幹什麼。
我或者很多人,在學習數學時都有一個誤區,很多數學的定理都是推導證明出來的,但是我們習慣拿來直接用,忘掉了怎麼去證明。當我去看程式碼時,反向傳播體現的僅僅是基於鏈式法則得出的結論,可是他到底是什麼,一個模糊的概念讓我心頭很是不爽,所以,在看卷積的方向傳播前,我必須將全連線的反向傳播(DNN)看懂。
2.誤區
對於我個人而言,沒有人系統帶著學習,全靠自己,所以很容易去想錯一些事兒。比如說,在學習反向傳播以前,很多人一定學到了梯度下降這個演算法,它很簡單,但是當我把他和反向傳播演算法聯絡到一起時,我懵了,梯度下降體現在哪裡?其實只要研究下這個演算法的程式碼,思路會很清晰,但是我看完後依舊有這麼一個誤區——總是想當然以為因變數是X,那我求導不應該對X嗎?然後全亂了....現在想想是真的傻。變數是誰?很明顯,這裡應該是權重和偏置(w和b),隨機給他們一個值,然後朝著谷底的方向更新他們,使得誤差函式最小。這才是他們結合的本來面目。
如果看完《深度學習和神經網路》這本書,你會很清晰的知道,隨機初始化這個說法太不嚴謹,服從標準正太分佈的初始化不一定是最好的,當然,這裡我們的重點應該放在更新上面。(我想試著用於語言描述這個過程,因為我發現我看過的資料裡並沒有人這麼做,但是對於當時的我,需要這麼一篇有邏輯性的文章,而不是僅僅有證明的,缺乏思考的資料)
3.輕鬆閱讀
首先,求導或者求偏導意味著什麼,個人認為聯絡到變化率三個字是最為完美的,因為無論是學習求導時還是推導基本函式的導數時,都是在圍繞變化率這三個字。變化率越大,求導結果越大,也可以變相理解為,重要程度也越大,那我為了使損失函式誤差最小,需要更新自變數——權重和偏置(w和b),我要怎麼更新?當然是越重要的更新的越多,不重要的更新的越少。
上面那句話可以從這個角度理解:
(1).越重要為什麼更新的越多?

首先你必須要有這個意識,越重要更新越多是我在寫這個演算法時就考慮好的,即這個重要程度可不是我每次都人為去篩選的,是程式碼基於資料自己選擇的。通俗來講,少年,深度學習基於什麼?Machine learning,機器學習,機器學習最大的好處是什麼,最最通俗來說,機器自己去學習。機器為什麼可以做到這樣?因為他從資料裡面學習到了“經驗”。那,這個重要程度基於什麼確定?我上面已經論述過了,把(變化率越大,求導結果越大,也可以變相理解為,重要程度也越大)這句話倒過來,難道不成立?結合上圖,我為了讓損失函式更快的接近最小值,一定沿著變化率最快的方向改變。
(2)不重要更新的少
上面懂了,這個就很容易了。
4.數學之美
長篇大論只是為了將抽象的數學平民化,但是卻忽略了它本身簡介、巧妙的特性。個人對數學理論鑽研不夠深刻,所以下文是基於大佬們的推導自己瞎琢磨的。
4.1 目標函式
做過優化的同學應該知道目標函式這個概念,在這裡我們的損失函式就是目標函式(原諒我懶不想手打公式,所以此處...截圖)。建議:本著嚴謹的態度,希望真的在看的同學看完以後,再去找另外的部落格或書籍拜讀,因為證明是沒問題的,但是證明過程中形式會有一點問題,會導致理解出現一點疑惑。(但是這個證明形式我最喜歡,很有邏輯性,不像我以前看的....如果你看我以前的部落格,寫的簡直...但是為了記住這些經歷,我還是留著吧)
舉一個不太好看(截圖原因)的例子:
(1)

(2)
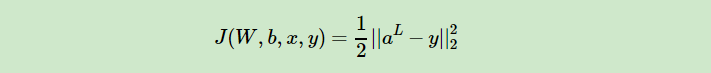
兩個代價函式都選擇的平方和代價函式,但是表現形式是不同的,一個基於實際情況按照累加的方式,一個就是單純的函式,但是在證明時你不能說誰對誰錯,自己把握就好。
(繼續)我們的目的是將這個損失函式最小化,怎麼最小化?按照上文,要改變自變數——權值和偏置(w和b)。怎麼改變?求偏導啊,按照偏導改變。所以,首先我們分別對這兩個自變數求偏導。

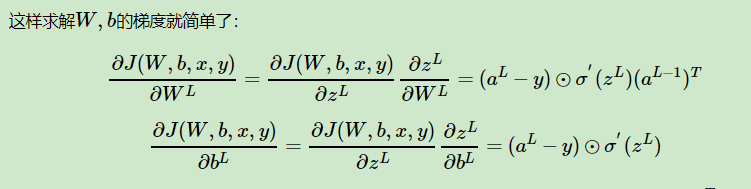
鏈式求導法則,如果看過上面大佬視訊的應該不難理解。
為了方便,做了如下替換:
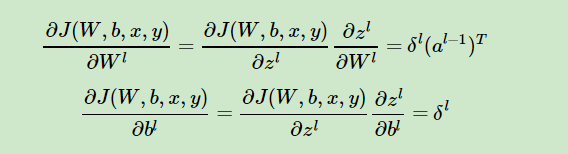
很顯然,為了求偏導,我必須知道(額,自己看圖應該看出來了吧...),那我怎麼求,當然是巧妙地利用數學原理啊。
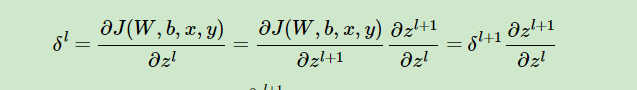
這個公式不僅告訴了我們怎麼求,還將整個神經網路連線了起來。接著求誰?(應該看得出來....)
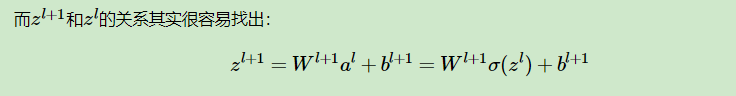
上式求偏導後帶入上上式得:
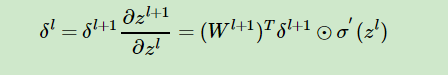
至此,我最最想說得已經論述完了,這就是反向傳播的精髓,至於程式碼怎麼實現?一定不僅僅於此。最難的懂了其他就很好說了,推薦去看看 (http://neuralnetworksanddeeplearning.com/about.html)
裡面有程式碼,也有反向傳播的講解,但是沒有邏輯性,很散亂,不然我以前早融會貫通了.......也就不會寫出以前那麼爛的部落格了。
(此處,重點)
參考大神部落格:https://www.cnblogs.com/pinard/p/6422831.html,證明過程是整理這裡的,很具有邏輯性,裡面也有程式碼怎麼實現得語言敘述,建議沒有打過程式碼的同學看看。