
Step by Step 改進樸素貝葉斯演算法
引言
如果你對naive bayes認識還處於初級階段,只瞭解基本的原理和假設,還沒有實現過產品級的程式碼,那麼這篇文章能夠幫助你一步步對原始的樸素貝葉斯演算法進行改進。在這個過程中你將會看到樸素貝葉斯假設的一些不合理處以及侷限性,從而瞭解為什麼這些假設在簡化你的演算法的同時,使最終分類結果變得糟糕,並針對這些問題提出了改進的方法。
樸素貝葉斯(Naive Bayes)
出處: 《機器學習》(Machine Learning by Tom M.Mitchell)
符號和術語
假設待分類的例項 X 可由屬性值的集合來進行描述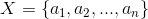
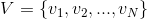
演算法推導
貝葉斯的目標是在給定例項的屬性值
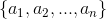
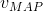 ,表示式如下
,表示式如下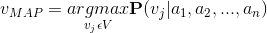
可使用貝葉斯公式將此表示式重寫為
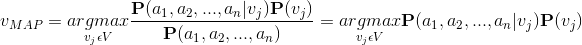
樸素貝葉斯假設
樸素貝葉斯假設: 例項 X 的各屬性之間相互獨立
根據概率的乘法定理,可得
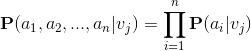
那麼樸素貝葉斯表示式就為
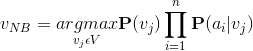
多項式樸素貝葉斯(multinomial Naive Bayes)
符號和術語
多項式貝葉斯是將某個文件看成許多單片語成的一個序列,並以文件中的單詞來建立多項式模型。即把文件中出現的單詞看作數學多項式中的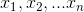
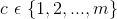
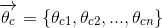
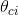
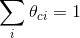
公式推導
文件屬於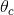
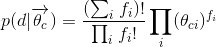
這裡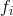
貝葉斯公式:
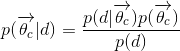
MAP假設以及將值取log:
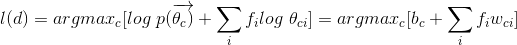
在上面的公式中,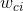
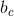
依據該論文,給出了一個簡單的公式
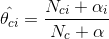
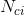
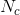
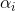
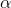
就等於字典的大小N。
將上面的公式代入之前的MAP假設可以得到
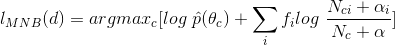
在這裡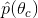
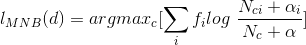
這個就是最終的多項式貝葉斯(MNB)的計算公式。
Complementary Naive Bayes
Complementary Naive Bayes, 也可以叫做互補樸素貝葉斯。
考慮這樣一個問題,假設有一個類別有偏的訓練資料集,即訓練資料集中屬於各個類別的文件數量各不相同, 問對比於類別均勻分佈的訓練資料集,分類結果有何不同?
假設類別c的數量較少,那麼單詞i屬於類別c的權重
相對於MNB的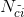
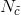
因此CNB的引數估計為
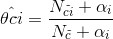
因此CNB的計算公式為
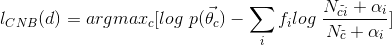
其中負號是由於單詞i屬於類別c與其補集的權重值正好是相反的,因此我們需要選取其補集權重小的作為分類結果,即前面加上一個負號。
Weight-normalized Complementary Naive Bayes
Weight-normalized Complementary Naive Bayes, 也可以叫做權重歸一化互補樸素貝葉斯。
Naive Bayes假設單詞之間相互獨立,雖然這簡化了計算, 但實際情況中該假設並不能很好滿足。
考慮這樣一個情形,我們假定有一些單詞很少分開出現,比如地名 San Francisco, 由於San和Francisco都是一起出現,那麼其對權重的貢獻將是單一的San或者Francisco的兩倍, 也就是說 San Francisco 的權重被Double-Counting了, 這樣將導致分類器不準確。例如,在一個文件中Boston出現了5次而San Francisco只出現了3次,那麼MNB更加傾向於將文件歸於San Francisco(6次)而不是Boston(5次)。有一種解決問題的辦法就是將權重歸一化,即將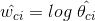
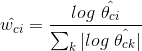
到目前為止我們在演算法公式方面做了一些改進,以減弱一些不合理假設的影響,使得結果更加接近實際情況。現在我們可以更進一步,從另外一個方面來改進演算法,那就是文字建模。
1.TFIDF
如果你有使用過Lucene的經歷,可能會接觸到一個概念,那就是TFIDF。因為該模型考慮到了包含字詞的文件站整個資料集的比例,因此可以比TF更加準確地評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。因此將文字模型中的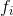
這裡建議選用lucene中TFIDF的計算方式
1.
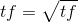
2.idf = 1 + log(numDocs / (1 + docFreq)
3.tfidf = tf * idf
2.Length norm
由於在大部分文件中單詞出現有其內在的聯絡,即如果一個單詞在某文件中出現,則該單詞就有較大的概率再次出現。而MNB簡單的假定單詞出現的概率相互獨立,因此在越長的文件中這種依賴關係造成的影響就越大,因此類似上面的Weighted-normalized,我們可以對長度進行歸一化來減弱這種依賴造成的影響。公式為
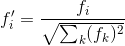
總結
綜上所述, naive bayes可以從根據考慮的角度以及側重點不同,從多個方面進行改進。在實際選取模型的時候,可以先對文字資料集的規模,文件的長度,類別的數量以及分佈情況等情況綜合考慮,選取適合的演算法。具體產品級的程式碼可以看Apache mahout專案的樸素貝葉斯部分,其實現了CNB以及TFIDF。
參考論文: