
hadoop環境搭建筆記
目錄
一、安裝準備
1、下載jdk和hadoop包
2、虛擬機器單機環境
二、環境安裝&配置
1、修改linux主機名
2、安裝jdk
3、設定免密碼登入 SSH
三、hadoop配置
1、配置hadoop_home環境變數
2、配置hadoop配置檔案
2.1 配置core-site.xml檔案
2.2 配置hdfs-site.xml檔案
2.3 配置yarn-site.xml
2.4 配置mapred-site.xml
2.5 配置檔案 mapred-site.xml
2.6 配置slaves
2.7 配置hadoop-env.sh
3、格式化分散式檔案系統(HDFS)
4、啟動HADOOP叢集
5、驗證HADOOP叢集
6、關閉防火牆
一、安裝準備
1、下載jdk和hadoop包
2、虛擬機器單機環境
32位的linux [www.19cr.com][紅帽企業Linux.6.5.伺服器版].rhel-server-6.5-i386-dvd.iso
32位的jdk jdk-8u111-linux-i586.tar.gz
二、JDK\SSH安裝&配置
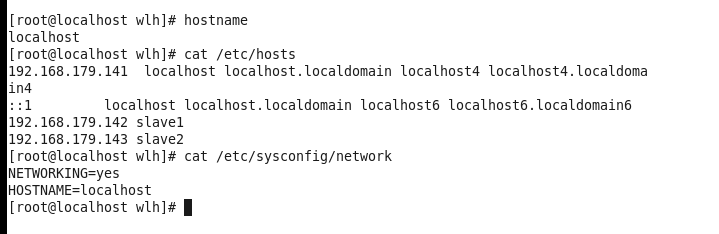
1、修改linux主機名
- 修改這兩個檔案,修改後reboot命令,重新啟動伺服器
vi /etc/sysconfig/network
vi /etc/hosts 將第一行的localhost改為想要設定的主機名 第二行不要動 #需要去掉例如,這裡的截圖是配置了完全分散式之後擷取的 所以包含了兩臺slaves的資訊
2、安裝jdk
/*給jdk 檔案賦許可權,使其可以被當前使用者操作 sudo chmod u+x 檔名*/
rpm包自動安裝到系統目錄/usr/java/,tar包解壓後,需指定路徑 安裝路徑在哪裡都可以,只要在profile檔案中寫好即可。
- 安裝jdk
#tar -xzvf jdk-8u111-linux-i586.tar.gz --tar包
#rpm -ivh xxx.rpm --rpm包- jdk的安裝目錄
/usr/java/jdk1.8.0_111/- 編輯 profile檔案
#vi /etc/profile 新增 JAVA_HOME=/usr/java/jdk1.8.0_111/
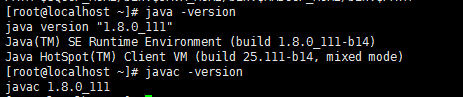
#source /etc/profile --使修改生效#echo $JAVA_HOME --列印java路徑 分別執行 java/javac -version --檢查jdk是否正確安裝 兩個顯示的版本要一樣的
3、設定免密碼登入 SSH
在Hadoop啟動以後,Namenode是通過SSH(Secure Shell)來啟動和停止各個datanode上的各種守護程序的,這就須要在節點之間執行指令的時候是不須要輸入密碼的形式,故我們須要配置SSH運用無密碼公鑰認證的形式。分散式環境中每臺機器上都安裝了ssh,並且datanode機器上sshd服務已經啟動
- 安裝SSH祕鑰
#ssh-keygen -t rsa - 執行這個命令後 會自動生成一個 .SSH的目錄 在這個目錄下 就是我們公鑰和私鑰,id_rsa.pub 是公鑰
[[email protected] ~]# cd .ssh/
[[email protected] .ssh]# cat id_rsa.pub >> authorized_keys
[[email protected] .ssh]# ll
total 12
-rw-r--r--. 1 root root 390 Nov 28 08:39 authorized_keys
-rw-------. 1 root root 1675 Nov 28 08:33 id_rsa
-rw-r--r--. 1 root root 390 Nov 28 08:33 id_rsa.pub- 驗證
[root@wlh ~]# ssh wlh --ssh後面跟的是 你要遠端的伺服器的主機名或地址注:如SSH報錯,不需要刪除檔案,修改後直接執行 ssh 主機名即可
三、hadoop配置
1、配置hadoop_home環境變數
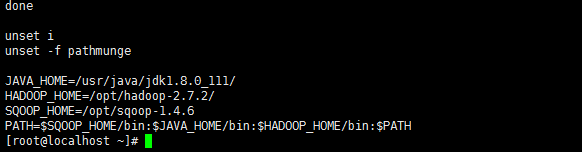
- 解壓 tar zxf hadoop-3.0.0-alpha1.tar.gz
- 解壓後執行 vi /etc/profile
新增 HADOOP_HOME=/opt/hadoop-3.0.0-alpha1
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
例(這個截圖時候來安裝2.7.2版本時的截圖)
- 執行 source /etc/profile 使修改生效
2、配置hadoop配置檔案
HADOOP 的配置檔案存放在/opt/hadoop-3.0.0-alpha1/etc/hadoop目錄下,需要配置以下六個檔案
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves
hadoop-env.sh
/*--在 <configuration> </configuration> 鍵值對中間寫*/
2.1 配置core-site.xml檔案
- 配置檔案系統,hdfs的埠
<property>
<name>fs.default.name</name>
<value>hdfs://wlh:9000</value> --<value>hdfs://linux主機名:埠</value>
</property>- 配置一個目錄
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.0.0-alpha1/current/tmp</value> --要手動建立這個目錄
</property>- 分散式檔案系統的垃圾箱(trash)
<property>
<name>fs.trash.interval</name>
<value>4320</value>--4320這個數是按分鐘算的,3分鐘,3分鐘會清理一次
</property>2.2 配置hdfs-site.xml檔案
- 配置分散式檔案系統
- 配置namenode位置
<property>
<name>dfs.namenode.dir</name>
<value>/opt/hadoop-3.0.0-alpha1/current/name</value> --要手動建立這個目錄
</property>- 配置datanode的資訊
/*這個實際上是要在datanode上配置的不用再namenode上配置,但現在配置的是偽分散式環境namenode和datanode在同一臺機器上。*/
<property>
<name>dfs.datanode.dir</name>
<value>/opt/hadoop-3.0.0-alpha1/current/data</value> --要手動建立這個目錄
</property>- 配置副本的數量,每個塊有幾個副本,偽分散式只有一個節點 ,value是1
<property>
<name>dfs.replication</name>
<value>1</value>
</property>- 配置hdfs是否啟用web
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>- 配置HDFS的使用者組和許可權
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value> --staff是hdfsd的使用者組
</property>- 不開啟許可權
<property>
<name>dfs.permissions.senabled</name>
<value>false</value>
</property>2.3 配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>wlh</value>--執行resourcemanager的機器的主機名
</property>
<property>
<name>yarn.nodemanager.aux.services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux.services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>- resourcemanager的埠
<property>
<name>yarn.resourcemanager.address</name>
<value>wlh:18040</value> --主機名+埠號 或者 IP地址+埠號
</property>- resourcemanager的排程器埠
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>wlh:18030</value> --所有的埠號都可以任意指定,但是不能重複
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>wlh:18025</value> --主機名+埠號 或者 IP地址+埠號
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>wlh:18141</value> --主機名+埠號 或者 IP地址+埠號
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>wlh:18888</value> --主機名+埠號 或者 IP地址+埠號
</property>- yarn中的日誌是否啟用
<property>
<name>yarn.log.aggregation.retain.seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log.aggregation.retain.check.interval.seconds</name>
<value>86400</value>
</property>- nodemanager
<property>
<name>yarn.nodemanager.remote.app.log.dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote.app.log.dir.suffix</name>
<value>logs</value>
</property>2.4 配置mapred-site.xml
目錄中沒有mapred-site.xml.檔案 只有mapred-site.xml.template 所以複製mapred-site.xml.template 檔案重新命名
cp mapred-site.xml.template mapred-site.xml2.5 配置檔案 mapred-site.xml
- mapreduce基於哪個框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>- 通訊的埠
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>wlh:5030</value>
</property>- job history
<property>
<name>mapreduce.jobhistory.address</name>
<value>wlh:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>wlh:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done.dir</name>--已完成的日誌目錄
<value>/jobhistroy/done</value>
</property>
<property>
<name>mapreduce.intermediate.done.dir</name>--中間情況日誌目錄
<value>/jobhistroy/done_intermediate</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>--中間情況日誌目錄
<value>true</value>
</property>2.6 配置slaves
datanode nodemanager在哪個機器上執行,在檔案中寫主機名即可
[root@wlh hadoop]# vi slaves
wlh2.7 配置hadoop-env.sh
新增 JAVA_HOME=/usr/java/jdk1.8.0_111/
[root@wlh hadoop]# vi hadoop-env.sh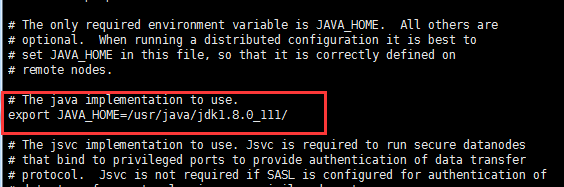
3、格式化分散式檔案系統(HDFS)
[root@wlh hadoop]# hdfs namenode -format執行這個命令後出現的語句中有這一行為成功2016-11-30 00:44:56,889 INFO common.Storage: Storage directory /opt/hadoop-3.0.0-alpha1/current/tmp/dfs/name has been successfully formatted.
4、啟動HADOOP叢集
- 在 /opt/hadoop-3.0.0-alpha1/sbin目錄下執行star-all.sh檔案
[[email protected] sbin]# /opt/hadoop-3.0.0-alpha1/sbin/start-all.sh
This script is deprecated. Use start-dfs.sh and start-yarn.sh instead.- 分別啟動即可
[[email protected] sbin]# /opt/hadoop-3.0