
機器學習sklearn19.0——Logistic迴歸演算法
一、Logistic迴歸的認知與應用場景
Logistic迴歸為概率型非線性迴歸模型,是研究二分類觀察結果
一種多變量分析方法。通常的問題是,研究某些因素條件下某個結果是否發生,比如醫學中根據病人的一些症狀
來判斷它是否患有某種病。
二、LR分類器
LR分類器,即Logistic Regression Classifier。
在分類情形下,經過學習後的LR分類器是一組權值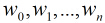
照線性加和得到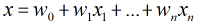
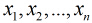
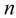
按照sigmoid函式的形式求出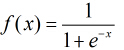
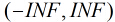
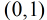
所以Logistic迴歸最關鍵的問題就是研究如何求得
三、Logistic迴歸模型
考慮具有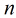
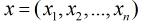
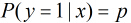
根據觀測量相對於某事件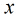
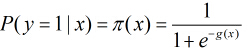
這裡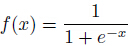
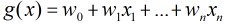
那麼在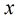
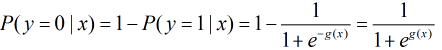
所以事件發生與不發生的概率之比為:
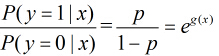
這個比值稱為事件的發生比(the odds of experiencing an event),簡記為odds。
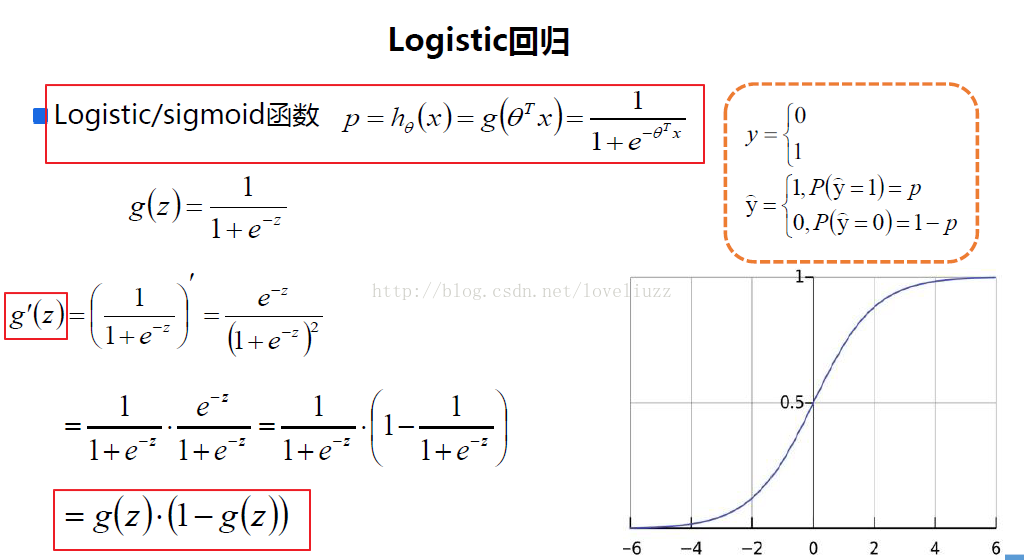
小結:
一般來說,迴歸不用在分類問題上,因為迴歸是連續型模型,而且受噪聲影響比較大。
如果非要應用在分類問題
logistic迴歸本質上是線性迴歸,只是在特徵到結果的對映中加入了一層函式對映,
即先把特徵線性求和,然後使用函式g(z)將做為假設函式來預測。g(z)可以將連續值對映到0和1上。
logistic迴歸的假設函式如下所示,線性迴歸假設函式只是![]() 。
。
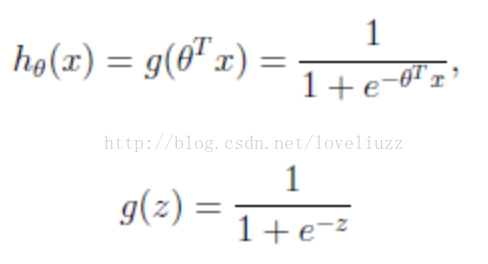
logistic迴歸用來分類0/1問題,也就是預測結果屬於0或者1的二值分類問題。
這裡假設了二值滿足伯努利分佈(0/1分佈或兩點分佈),也就是




四、logistic迴歸應用案例
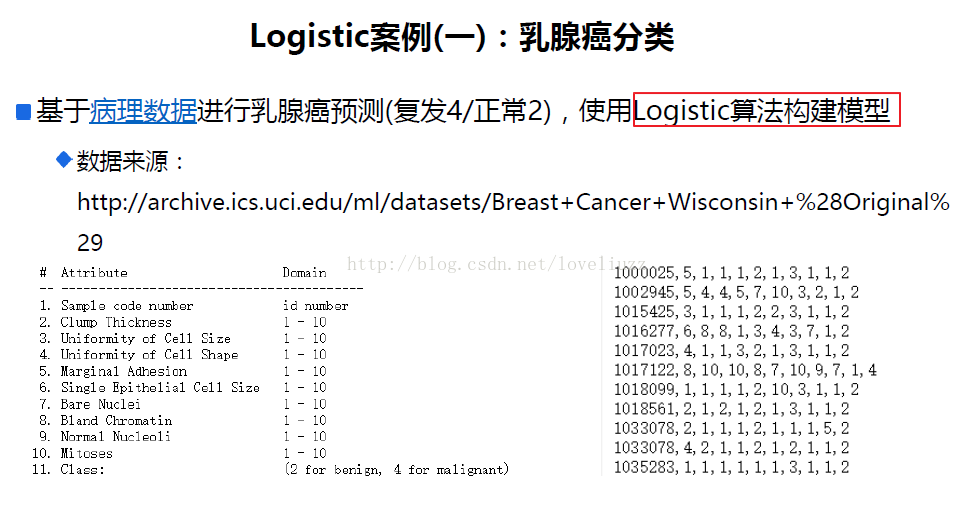
(1)sklearn中對LogisticRegressionCV函式的解析








(2)程式碼如下:
檔案連結如下:連結:https://pan.baidu.com/s/1dEWUEhb 密碼:bm1p
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#乳腺癌分類案例
import sklearn
from sklearn.linear_model import LogisticRegressionCV,LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
#解決中文顯示問題
mpl.rcParams["font.sans-serif"] = [u"SimHei"]
mpl.rcParams["axes.unicode_minus"] = False
#攔截異常
warnings.filterwarnings(action='ignore',category=ConvergenceWarning)
#匯入資料並對異常資料進行清除
path = "datas/breast-cancer-wisconsin.data"
names = ["id","Clump Thickness","Uniformity of Cell Size","Uniformity of Cell Shape"
,"Marginal Adhesion","Single Epithelial Cell Size","Bare Nuclei","Bland Chromatin"
,"Normal Nucleoli","Mitoses","Class"]
df = pd.read_csv(path,header=None,names=names)
datas = df.replace("?",np.nan).dropna(how="any") #只要列中有nan值,進行行刪除操作
#print(datas.head()) #預設顯示前五行
#資料提取與資料分割
X = datas[names[1:10]]
Y = datas[names[10]]
#劃分訓練集與測試集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.1,random_state=0)
#對資料的訓練集進行標準化
ss = StandardScaler()
X_train = ss.fit_transform(X_train) #先擬合數據在進行標準化
#構建並訓練模型
## multi_class:分類方式選擇引數,有"ovr(預設)"和"multinomial"兩個值可選擇,在二元邏輯迴歸中無區別
## cv:幾折交叉驗證
## solver:優化演算法選擇引數,當penalty為"l1"時,引數只能是"liblinear(座標軸下降法)"
## "lbfgs"和"cg"都是關於目標函式的二階泰勒展開
## 當penalty為"l2"時,引數可以是"lbfgs(擬牛頓法)","newton_cg(牛頓法變種)","seg(minibactch隨機平均梯度下降)"
## 維度<10000時,選擇"lbfgs"法,維度>10000時,選擇"cs"法比較好,顯示卡計算的時候,lbfgs"和"cs"都比"seg"快
## penalty:正則化選擇引數,用於解決過擬合,可選"l1","l2"
## tol:當目標函式下降到該值是就停止,叫:容忍度,防止計算的過多
lr = LogisticRegressionCV(multi_class="ovr",fit_intercept=True,Cs=np.logspace(-2,2,20),cv=2,penalty="l2",solver="lbfgs",tol=0.01)
re = lr.fit(X_train,Y_train)
#模型效果獲取
r = re.score(X_train,Y_train)
print("R值(準確率):",r)
print("引數:",re.coef_)
print("截距:",re.intercept_)
print("稀疏化特徵比率:%.2f%%" %(np.mean(lr.coef_.ravel()==0)*100))
print("=========sigmoid函式轉化的值,即:概率p=========")
print(re.predict_proba(X_test)) #sigmoid函式轉化的值,即:概率p
#模型的儲存與持久化
from sklearn.externals import joblib
joblib.dump(ss,"logistic_ss.model") #將標準化模型儲存
joblib.dump(lr,"logistic_lr.model") #將訓練後的線性模型儲存
joblib.load("logistic_ss.model") #載入模型,會儲存該model檔案
joblib.load("logistic_lr.model")
#預測
X_test = ss.transform(X_test) #資料標準化
Y_predict = lr.predict(X_test) #預測
#畫圖對預測值和實際值進行比較
x = range(len(X_test))
plt.figure(figsize=(14,7),facecolor="w")
plt.ylim(0,6)
plt.plot(x,Y_test,"ro",markersize=8,zorder=3,label=u"真實值")
plt.plot(x,Y_predict,"go",markersize=14,zorder=2,label=u"預測值,$R^2$=%.3f" %lr.score(X_test,Y_test))
plt.legend(loc="upper left")
plt.xlabel(u"資料編號",fontsize=18)
plt.ylabel(u"乳癌型別",fontsize=18)
plt.title(u"Logistic演算法對資料進行分類",fontsize=20)
plt.savefig("Logistic演算法對資料進行分類.png")
plt.show()
print("=============Y_test==============")
print(Y_test.ravel())
print("============Y_predict============")
print(Y_predict)
#執行結果:
R值(準確率): 0.970684039088
引數: [[ 1.3926311 0.17397478 0.65749877 0.8929026 0.36507062 1.36092964
0.91444624 0.63198866 0.75459326]]
截距: [-1.02717163]
稀疏化特徵比率:0.00%
=========sigmoid函式轉化的值,即:概率p=========
[[ 6.61838068e-06 9.99993382e-01]
[ 3.78575185e-05 9.99962142e-01]
[ 2.44249065e-15 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 1.52850624e-03 9.98471494e-01]
[ 6.67061684e-05 9.99933294e-01]
[ 6.75536843e-07 9.99999324e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 2.43117004e-05 9.99975688e-01]
[ 6.13092842e-04 9.99386907e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 2.00330728e-06 9.99997997e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 3.78575185e-05 9.99962142e-01]
[ 4.65824155e-08 9.99999953e-01]
[ 5.47788703e-10 9.99999999e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 6.27260778e-07 9.99999373e-01]
[ 3.78575185e-05 9.99962142e-01]
[ 3.85098865e-06 9.99996149e-01]
[ 1.80189197e-12 1.00000000e+00]
[ 9.44640398e-05 9.99905536e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 4.11688915e-06 9.99995883e-01]
[ 1.85886872e-05 9.99981411e-01]
[ 5.83016713e-06 9.99994170e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 1.52850624e-03 9.98471494e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 1.51713085e-05 9.99984829e-01]
[ 2.34685008e-05 9.99976531e-01]
[ 1.51713085e-05 9.99984829e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 0.00000000e+00 1.00000000e+00]
[ 2.34685008e-05 9.99976531e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 9.97563915e-07 9.99999002e-01]
[ 1.70686321e-07 9.99999829e-01]
[ 1.38382134e-04 9.99861618e-01]
[ 1.36080718e-04 9.99863919e-01]
[ 1.52850624e-03 9.98471494e-01]
[ 1.68154251e-05 9.99983185e-01]
[ 6.66097483e-04 9.99333903e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 9.77502258e-07 9.99999022e-01]
[ 5.83016713e-06 9.99994170e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 4.09496721e-06 9.99995905e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 1.37819117e-06 9.99998622e-01]
[ 6.27260778e-07 9.99999373e-01]
[ 4.52734741e-07 9.99999547e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 8.88178420e-16 1.00000000e+00]
[ 1.06976766e-08 9.99999989e-01]
[ 0.00000000e+00 1.00000000e+00]
[ 2.45780192e-04 9.99754220e-01]
[ 3.92389040e-04 9.99607611e-01]
[ 6.10681985e-05 9.99938932e-01]
[ 9.44640398e-05 9.99905536e-01]
[ 1.51713085e-05 9.99984829e-01]
[ 2.45780192e-04 9.99754220e-01]
[ 2.45780192e-04 9.99754220e-01]
[ 1.51713085e-05 9.99984829e-01]
[ 0.00000000e+00 1.00000000e+00]]
=============Y_test==============
[2 2 4 4 2 2 2 4 2 2 4 2 4 2 2 2 4 4 4 2 2 2 4 2 4 4 2 2 2 4 2 4 4 2 2 2 4
4 2 4 2 2 2 2 2 2 2 4 2 2 4 2 4 2 2 2 4 2 2 4 2 2 2 2 2 2 2 2 4]
============Y_predict============
[2 2 4 4 2 2 2 4 2 2 4 2 4 2 2 2 4 4 4 2 2 2 4 2 4 4 2 2 2 4 2 4 4 2 2 2 4
4 2 4 2 2 2 2 2 2 2 4 2 2 4 2 4 2 2 2 4 4 2 4 2 2 2 2 2 2 2 2 4]五、softmax迴歸——多分類問題
(1)softmax迴歸定義與概述


(2)softmax迴歸案例分析——葡萄酒質量預測模型
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#葡萄酒質量預測模型
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import sklearn
from sklearn.linear_model import LogisticRegressionCV
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import label_binarize
from sklearn import metrics
#解決中文顯示問題
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#攔截異常
warnings.filterwarnings(action = 'ignore', category=ConvergenceWarning)
#匯入資料
path1 = "datas/winequality-red.csv"
df1 = pd.read_csv(path1, sep=";")
df1['type'] = 1
path2 = "datas/winequality-white.csv"
df2 = pd.read_csv(path2, sep=";")
df2['type'] = 2
df = pd.concat([df1,df2], axis=0)
names = ["fixed acidity","volatile acidity","citric acid",
"residual sugar","chlorides","free sulfur dioxide",
"total sulfur dioxide","density","pH","sulphates",
"alcohol", "type"]
quality = "quality"
#print(df.head(5))
#對異常資料進行清除
new_df = df.replace('?', np.nan)
datas = new_df.dropna(how = 'any')
print ("原始資料條數:%d;異常資料處理後資料條數:%d;異常資料條數:%d" % (len(df), len(datas), len(df) - len(datas)))
#資料提取與資料分割
X = datas[names]
Y = datas[quality]
#劃分訓練集與測試集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
print ("訓練資料條數:%d;資料特徵個數:%d;測試資料條數:%d" % (X_train.shape[0], X_train.shape[1], X_test.shape[0]))
#對資料的訓練集進行標準化
mms = MinMaxScaler()
X_train = mms.fit_transform(X_train)
#構建並訓練模型
lr = LogisticRegressionCV(fit_intercept=True, Cs=np.logspace(-5, 1, 100),
multi_class='multinomial', penalty='l2', solver='lbfgs')
lr.fit(X_train, Y_train)
##模型效果獲取
r = lr.score(X_train, Y_train)
print ("R值:", r)
print ("特徵稀疏化比率:%.2f%%" % (np.mean(lr.coef_.ravel() == 0) * 100))
print ("引數:",lr.coef_)
print ("截距:",lr.intercept_)
#預測
X_test = mms.transform(X_test)
Y_predict = lr.predict(X_test)
#畫圖對預測值和實際值進行比較
x_len = range(len(X_test))
plt.figure(figsize=(14,7), facecolor='w')
plt.ylim(-1,11)
plt.plot(x_len, Y_test, 'ro',markersize = 8, zorder=3, label=u'真實值')
plt.plot(x_len, Y_predict, 'go', markersize = 12, zorder=2, label=u'預測值,$R^2$=%.3f' % lr.score(X_train, Y_train))
plt.legend(loc = 'upper left')
plt.xlabel(u'資料編號', fontsize=18)
plt.ylabel(u'葡萄酒質量', fontsize=18)
plt.title(u'葡萄酒質量預測統計', fontsize=20)
plt.savefig("葡萄酒質量預測統計.png")
plt.show()
#執行結果:
原始資料條數:6497;異常資料處理後資料條數:6497;異常資料條數:0
訓練資料條數:4872;資料特徵個數:12;測試資料條數:1625
R值: 0.549466338259
特徵稀疏化比率:0.00%
引數: [[ 0.97934119 2.16608604 -0.41710039 -0.49330657 0.90621136 1.44813439
0.75463562 0.2311527 0.01015772 -0.69598672 -0.71473577 -0.2907567 ]
[ 0.62487587 5.11612885 -0.38168837 -2.16145905 1.21149753 -3.71928146
-1.45623362 1.34125165 0.33725355 -0.86655787 -2.7469681 2.02850838]
[-1.73828753 1.96024965 0.48775556 -1.91223567 0.64365084 -1.67821019
2.20322661 1.49086179 -1.36192671 -2.2337436 -5.01452059 -0.75501299]
[-1.19975858 -2.60860814 -0.34557812 0.17579494 -0.04388969 0.81453743
-0.28250319 0.51716692 -0.67756552 0.18480087 0.01838834 -0.71392084]
[ 1.15641271 -4.6636028 -0.30902483 2.21225522 -2.00298042 1.66691445
-1.02831849 -2.15017982 0.80529532 2.68270545 3.36326129 -0.73635195]
[-0.07892353 -1.82724304 0.69405191 2.07681409 -0.6247279 1.49244742
-0.16115782 -1.3671237 0.72694885 1.06878382 4.68718155 0.04669067]
[ 0.25633987 -0.14301056 0.27158425 0.10213705 -0.08976172 -0.02454203
-0.02964911 -0.06312954 0.15983679 -0.14000195 0.40739327 0.42084343]]
截距: [-2.34176729 -1.1649153 4.91027564 4.3206539 1.30164164 -2.25841567
-4.76747291]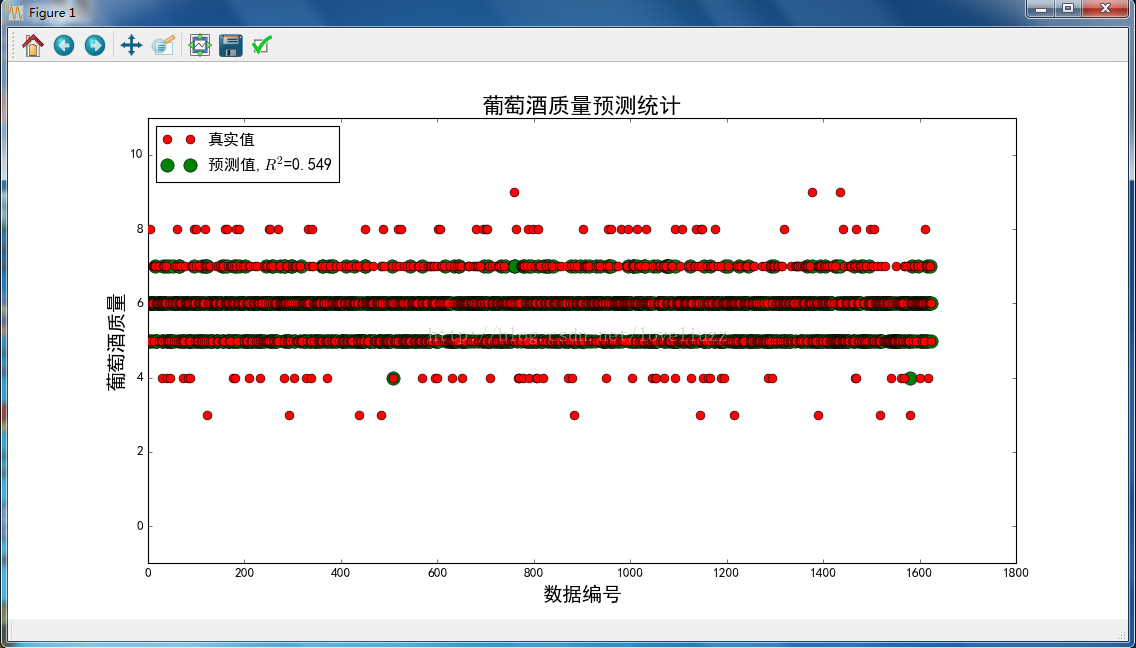
六、分類問題綜合案例——鳶尾花分類問題、ROC/AUC
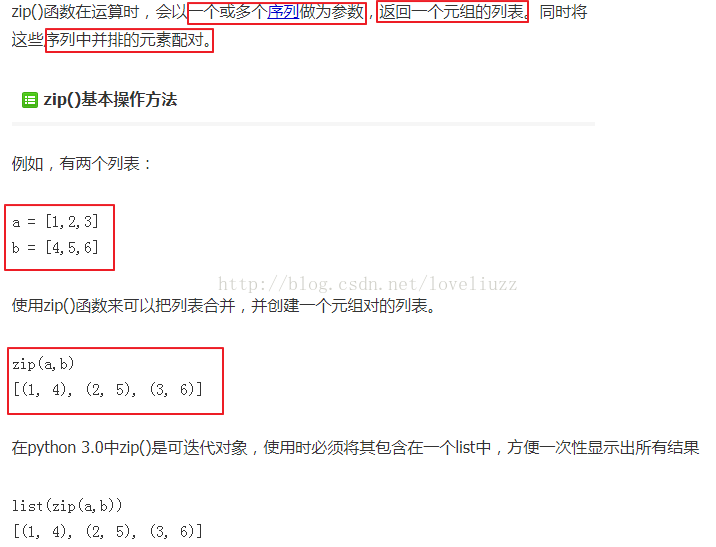
(1)知識點——python自帶內建函式zip()函式


(2)知識點——sklearn.model_selection.train_test_split——隨機劃分訓練集與測試集

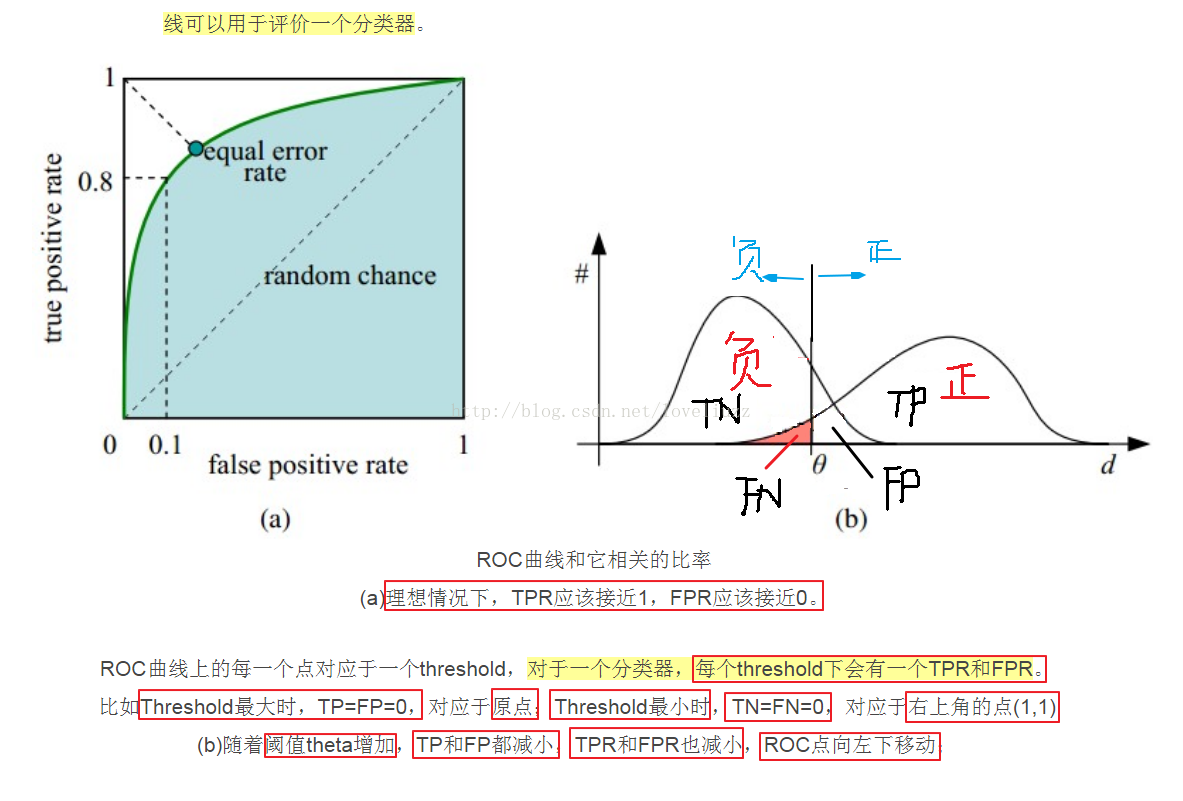
(3)知識點——ROC曲線
詳細連結地址:http://blog.csdn.net/abcjennifer/article/details/7359370


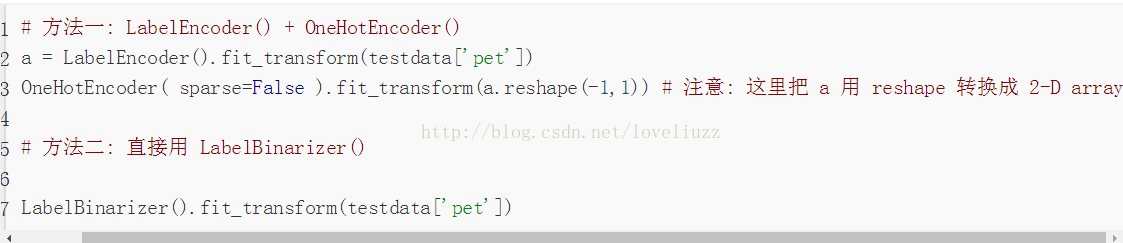
(4)知識點——所涉及到的幾種 sklearn 的二值化編碼函式:
OneHotEncoder(), LabelEncoder(), LabelBinarizer(), MultiLabelBinarizer()
詳細連結地址為:http://blog.csdn.net/gao1440156051/article/details/55096630

案例程式碼:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#分類綜合問題——鳶尾花分類案例(ROC/AUC)
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import sklearn
from sklearn.linear_model import LogisticRegressionCV
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import label_binarize
from sklearn import metrics
#解決中文顯示問題
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#攔截異常
warnings.filterwarnings(action = 'ignore', category=ConvergenceWarning)
#匯入資料
path = "datas/iris.data"
names = ['sepal length', 'sepal width', 'petal length', 'petal width', 'cla']
df = pd.read_csv(path,header=None,names=names)
print(df['cla'].value_counts())
print(df.head())
#編碼函式
def parseRecord(record): #record是資料集
result = []
# zip() 函式接受一系列可迭代的物件作為引數,將物件中對應的元素按順序組合成一個tuple,
# 每個tuple中包含的是原有序列中對應序號位置的元素,然後返回由這些tuples組成的list。
r = zip(names,record)
for name,v in r:
if name == "cla":
if v == "Iris-setosa":
result.append(1)
elif v == "Iris-versicolor":
result.append(2)
elif v == "Iris-virginica":
result.append(3)
else:
result.append(np.nan)
else:
result.append(float(v))
return result
#資料轉換為數字以及分割
#資料轉換
datas = df.apply(lambda r:parseRecord(r),axis=1)
print(datas.head())
#異常資料刪除
datas = datas.dropna(how="any")
#資料分割
X = datas[names[0:-1]]
Y = datas[names[-1]]
#劃分訓練集與測試集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.4,random_state=0)
print("原始資料條數:%d;訓練資料條數:%d;特徵個數:%d;測試樣本條數:%d" %(len(X),len(X_train),X_train.shape[1],len(X_test)))
#對資料集進行標準化
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
#構建並訓練模型
lr = LogisticRegressionCV(Cs=np.logspace(-4,1,50),cv=3,fit_intercept=True,penalty="l2",
solver="lbfgs",tol=0.01,multi_class="multinomial")
lr.fit(X_train,Y_train)
#模型效果獲取
#將測試集標籤資料用二值化編碼的方式轉換為矩陣
y_test_hot = label_binarize(Y_test,classes=(1,2,3))
#得到預測的損失值
lr_y_score = lr.decision_function(X_test)
#計算ROC的值,lr_threasholds為閾值
lr_fpr,lr_tpr,lr_threasholds = metrics.roc_curve(y_test_hot.ravel(),lr_y_score.ravel())
#計算AUC值
lr_auc = metrics.auc(lr_fpr,lr_tpr)
print("Logistic演算法R值:",lr.score(X_train,Y_train))
print("Logistic演算法AUC值:",lr_auc)
#模型預測
lr_y_predict = lr.predict(X_test)
#畫圖對預測值和實際值進行比較
plt.figure(figsize=(8,6),facecolor="w")
plt.plot(lr_fpr,lr_tpr,c="r",lw=2,label=u"Logistic演算法,AUC=%.3f" %lr_auc)
plt.plot((0,1),(0,1),c='#a0a0a0',lw=2,ls='--')
plt.xlim(-0.01,1.02)
plt.ylim(-0.01,1.02)
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate(FPR)', fontsize=16)
plt.ylabel('True Positive Rate(TPR)', fontsize=16)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'鳶尾花資料Logistic演算法的ROC/AUC', fontsize=18)
plt.savefig("鳶尾花資料Logistic演算法的ROC和AUC.png")
plt.show()
len_x_test = range(len(X_test))
plt.figure(figsize=(12,9),facecolor="w")
plt.ylim(0.5,3.5)
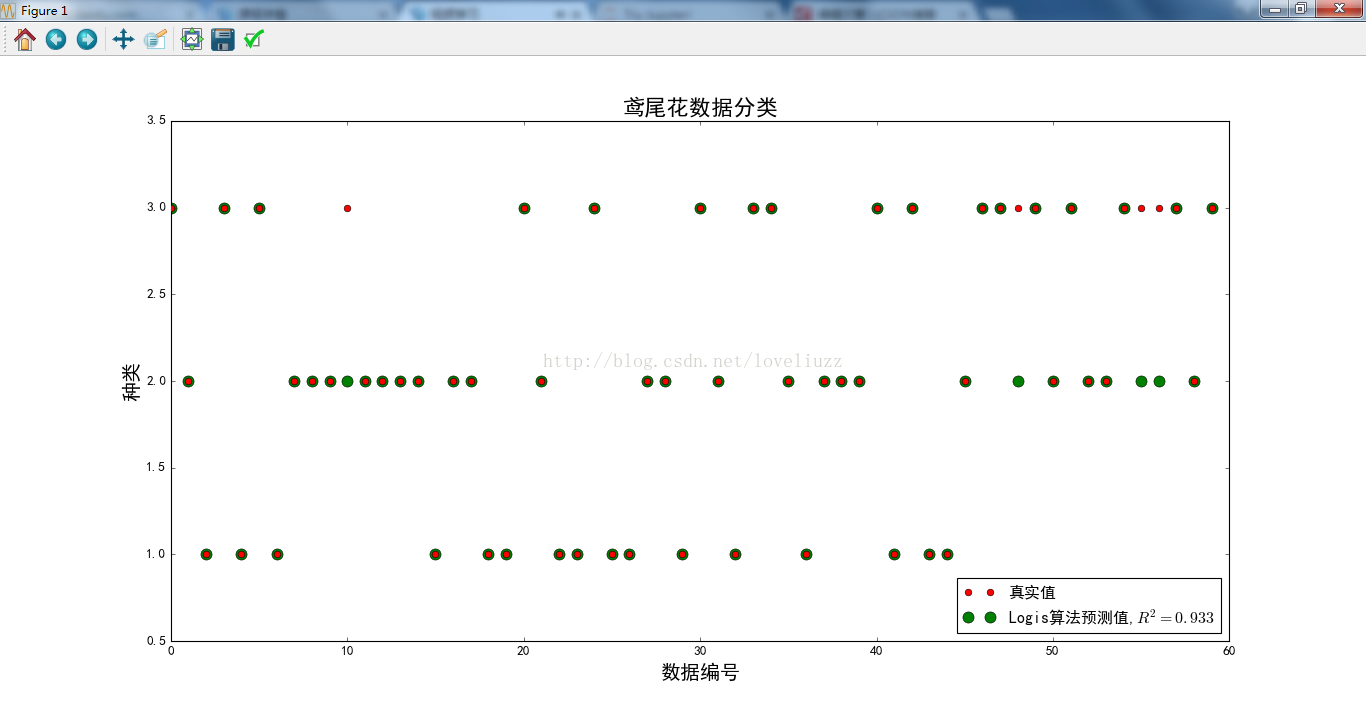
plt.plot(len_x_test,Y_test,"ro",markersize=6,zorder=3,label=u"真實值")
plt.plot(len_x_test,lr_y_predict,"go",markersize=10,zorder=2,label=u"Logis演算法預測值,$R^2=%.3f$" %lr.score(X_test,Y_test))
plt.legend(loc = 'lower right')
plt.xlabel(u'資料編號', fontsize=18)
plt.ylabel(u'種類', fontsize=18)
plt.title(u'鳶尾花資料分類', fontsize=20)
plt.savefig("鳶尾花資料分類.png")
plt.show()
#執行結果:
Iris-versicolor 50
Iris-setosa 50
Iris-virginica 50
Name: cla, dtype: int64
sepal length sepal width petal length petal width cla
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
sepal length sepal width petal length petal width cla
0 5.1 3.5 1.4 0.2 1.0
1 4.9 3.0 1.4 0.2 1.0
2 4.7 3.2 1.3 0.2 1.0
3 4.6 3.1 1.5 0.2 1.0
4 5.0 3.6 1.4 0.2 1.0
原始資料條數:150;訓練資料條數:90;特徵個數:4;測試樣本條數:60
Logistic演算法R值: 0.977777777778
Logistic演算法AUC值: 0.926944444444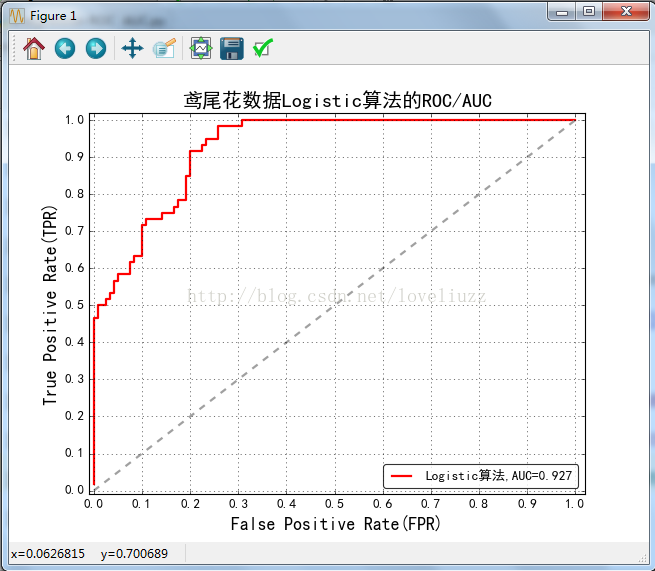
相關推薦
機器學習sklearn19.0——Logistic迴歸演算法
一、Logistic迴歸的認知與應用場景 Logistic迴歸為概率型非線性迴歸模型,是研究二分類觀察結果與一些影響因素之間關係的 一種多變量分析方法。通常的問題是,研究某些因素條件下某個結果是否發生,比如醫學中根據病人的一些症狀 來判斷它是否患有某種病。 二
機器學習sklearn19.0——線性迴歸演算法(應用案例)
一、sklearn中的線性迴歸的使用 二、線性迴歸——家庭用電預測 (1)時間與功率之間的關係 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #線性迴歸——家庭用電預
《機器學習實戰》Logistic迴歸演算法(1)
-0.017612 14.053064 0 -1.395634 4.662541 1 -0.752157 6.5386200 -1.322371 7.152853 0 0.42336311.054677 0 0.406704 7.067335 1 0
機器學習sklearn19.0聚類演算法——Kmeans演算法
一、關於聚類及相似度、距離的知識點 二、k-means演算法思想與流程 三、sklearn中對於kmeans演算法的引數 四、程式碼示例以及應用的知識點簡介 (1)make_blobs:聚類資料生成器 sklearn.datasets.m
機器學習sklearn19.0聚類演算法——層次聚類(AGNES/DIANA)、密度聚類(DBSCAN/MDCA)、譜聚類
一、層次聚類 BIRCH演算法詳細介紹以及sklearn中的應用如下面部落格連結: http://www.cnblogs.com/pinard/p/6179132.html http://www.cnblogs.com/pinard/p/62
機器學習sklearn19.0——整合學習——boosting與梯度提升演算法(GBDT)、Adaboost演算法
一、boosting演算法原理 二、梯度提升演算法 關於提升梯度演算法的詳細介紹,參照部落格:http://www.cnblogs.com/pinard/p/6140514.html 對該演算法的sklearn的類庫介紹和調參,參照網址:http://
《機器學習實戰》Logistic迴歸python3原始碼
邏輯迴歸: 1 梯度上升優化演算法 2 隨機梯度上升演算法 3 改進的隨機梯度上升法 開啟pycharm建立一個logRegression.py檔案,輸入如下程式碼: #coding:utf-8 from numpy import * ""
《機器學習實戰》logistic迴歸:關於’此處略去了一個簡單的數學推導‘的個人理解
正在看《機器學習實戰》這本書的朋友,在看到logistic迴歸的地方,可能會對P78頁的梯度上升演算法程式碼以及P79這裡的這句話弄的一頭霧水:“此處略去了一個簡單的數學推導,我把它留給有興趣的讀者”。這句話就是針對下面這段我貼出來的程式碼中的gradAscen
機器學習實戰:logistic迴歸--學習筆記
一、工作原理 1.每個迴歸係數初始化為 1 2.重複 R 次: 1. 計算整個資料集的梯度 2. 使用 步長 x 梯度 更新迴歸係數的向量 5.返回迴歸係數 二、實現程式碼 1.基於梯度上升尋找邏輯迴歸引數
機器學習入門之線性迴歸演算法推導
心血來潮,想將所學到的知識寫篇部落格,筆者所研究的方向為機器學習,剛學習的時候,走了很多彎路,看的書不少,在推導機器學習一些演算法時候遇到了不少困難,查了不少資料,在剛才學的時候,有很多公式推導起來很困難,或者說大多數人都會遇到這樣的問題,本部落格目的就是解決在機器學習公式推導過程中遇到的問
吳恩達機器學習練習2——Logistic迴歸
Logistic迴歸 代價函式 Logistic迴歸是分類演算法,它的輸出值在0和1之間。 h(x)的作用是,對於給定的輸入變數,根據選擇的引數計算輸出變數等於1的可能性(estimated probablity)即h(x)=P(y=1|x;
機器學習4/100-Logistic迴歸
Day4 Logistic迴歸 github: 100DaysOfMLCode Logistic迴歸用於分類問題,可以直接用於二分類問題,也可以設計應用於多分類問題。 原理 傳統的感知機將wx+b>0和wx+b<0實現二分類(0、1),Logistics迴歸更進一步,
【機器學習實戰】Logistic迴歸 總結與思考
【機器學習實戰】Logistic迴歸 全部程式均是依照《機器學習實戰》書寫,然後進行了一些修改(順便鞏固python) Logistic原理簡單解釋 作者在書中這樣描述Logistic迴歸 根據現有資料對分類邊界線建立迴歸公式,以此進行分類 --《機器學習實戰》P73 這本書對於理論的東
【十】機器學習之路——logistic迴歸python實現
前面一個部落格機器學習之路——logistic迴歸講了logistic迴歸的理論知識,現在咱們來看一下logistic迴歸如何用python來實現,程式碼、資料參考《機器學習實戰》。 首先看下我們要處理的資料, 我們要做的就是通過logistic
吳恩達機器學習筆記 —— 7 Logistic迴歸
本章主要講解了邏輯迴歸相關的問題,比如什麼是分類?邏輯迴歸如何定義損失函式?邏輯迴歸如何求最優解?如何理解決策邊界?如何解決多分類的問題? 有的時候我們遇到的問題並不是線性的問題,而是分類的問題。比如判斷郵件是否是垃圾郵件,信用卡交易是否正常,腫瘤是良性還是惡性的。他們有一個共同點就是Y只有兩個值{0,
牛頓法解機器學習中的Logistic迴歸
引言 這仍然是近期系列文章中的一篇。在這一個系列中,我打算把機器學習中的Logistic迴歸從原理到應用詳細串起來。最初我們介紹了在Python中利用Scikit-Learn來建立Logistic迴歸分類器的方法 此後,我們對上述文章進行了更深一層的探討
《機器學習實戰》——logistic迴歸
說明:對書中程式碼錯誤部分做了修正,可運行於python3.4 基本原理:現在有一些資料點,用一條直線對這些資料進行擬合,將它們分為兩類。這條直線叫做最佳擬合直線,這個擬合過程叫做迴歸。logistic迴歸的思想是,利用一個階躍函式(在某一點突然由0變1),實現分類器
【機器學習實戰】-Logistic 迴歸
一、邏輯迴歸介紹 Logistic 迴歸,雖然名字叫邏輯迴歸,但是它並不是一個迴歸模型,而是分類模型。利用邏輯迴歸進行分類的主要思想是: 根據現有資料對分類邊界線建立迴歸公式。介紹它的真正原理之前,我們要介紹一下回歸的概念,那麼什麼是迴歸呢?假設我們現在有一堆
機器學習實戰——利用Logistic迴歸預測疝氣病症的病馬的死亡率
資料來源 處理過程 由於該資料集存在30%的缺失,那麼首先必須對資料集進行預處理,這裡我把缺失值用每列的平均值來代替,同時把資料集沒用的幾列資料捨棄。之後利用sklearn庫進行Logistic迴歸。 結果: 由於有30%的資料缺失,
機器學習之logistic迴歸演算法與程式碼實現
Logistic迴歸演算法與程式