
Python實現邏輯迴歸
阿新 • • 發佈:2019-01-09
預備資源
Python的幾個包:
- numpy: Python的語言擴充套件,定義了數字的陣列和矩陣
- pandas: 直接處理和操作資料的主要package
- statsmodels: 統計和計量經濟學的package,包含了用於引數評估和統計測試的實用工具
- pylab: 用於生成統計圖
安裝參考:傳送門
例項
實驗目標
通過分析不同的因素對研究生錄取的影響來預測一個人是否會被錄取。
資料
資料來源
資料的格式如下:
| row_num | admit | gre | gpa | rank |
|---|---|---|---|---|
| 0 | 0 | 380 | 3.61 | 3 |
| 1 | 1 | 660 | 3.67 | 3 |
- admit :表示是否被錄取(目標變數)
- gre: 預測變數
- gpa:預測變數
- rank:母校排名(預測變數)
讀取資料
通過pandas.read_csv(“檔案路徑”)讀取資料
import pandas as pd
import statsmodels.api as sm
import pylab as pl
import numpy as np
df = pd.read_csv("./binary.csv")
print df.head()
# 重新命名'rank'列,因為dataframe中有個方法名也為'rank'
df.columns = ["admit" 結果:
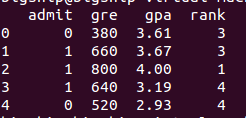
統計摘要繪圖
pandas庫提供函式describe來對資料進行統計,其中包括最值,均值,標準差等,計算標準差我們也可以用padans.dataframe.std()來求標準差,我們可以通過padans.dataframe.hist()來畫柱狀圖,通過pylab.show來展示
print df.describe()
print df.std()
print pd.crosstab(df['admit' 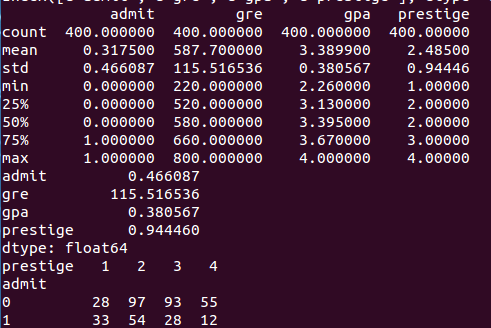
虛擬變數
虛擬變數,也叫啞變數,可用來表示分類變數、非數量因素可能產生的影響。在計量經濟學模型,需要經常考慮屬性因素的影響。例如,職業、文化程度、季節等屬性因素往往很難直接度量它們的大小。只能給出它們的“Yes—D=1”或”No—D=0”,或者它們的程度或等級。為了反映屬性因素和提高模型的精度,必須將屬性因素“量化”。通過構造0-1型的人工變數來量化屬性因素。
pandas提供一個一個分類變數的控制功能,我們可以通過get_dummies來對一列進行虛擬化。本例中將prestige虛擬化實現,以實現量化
#將prestige虛擬化實現,量化
dummy_ranks = pd.get_dummies(df['prestige'],prefix='prestige')
print dummy_ranks.head()
clos_to_keep=['admit','gre','gpa']
#合併虛擬項與原資料得到完成LR的dataframe
data = df[clos_to_keep].join(dummy_ranks.ix[:,'prestige_2':])
print data.head()
#自行新增邏輯迴歸需要的intercept變數(常數項)
data['intercept']=1.0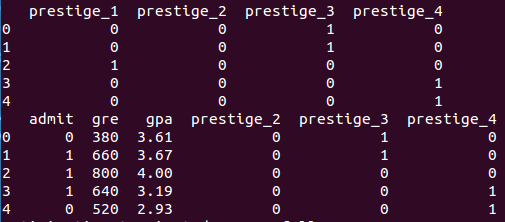
將新的虛擬變數加入到原始的資料集中就不需要原來的prestige列了,生成m個虛擬變數只需要引入m-1個虛擬變數到資料集中,未引入的一個是作為基準對比的。將虛擬變數與”admit,gre,gpa”合併後就得到了實現邏輯的dataframe。除此之外。我們還需要顯示的加上常數intercept
執行邏輯迴歸
在之前我們已經將準備工作做就緒,那麼接下來就可以執行邏輯迴歸了。
- 首先要指定預測變數的列和模型用於做預測的列。
- 呼叫演算法包執行演算法。
在本例中預測admit,使用gre,gpa,以及虛擬變數p2,p3,p4做預測變數。
#指定作為訓練變數的列,不含目標列‘admit’
train_cols=data.columns[1:]
#執行邏輯迴歸
logit = sm.Logit(data['admit'],data[train_cols])
#擬合引數
result = logit.fit()statasmodels庫中提供了許多的機器學習的演算法,詳情參見:傳送門
使用模型進行預測
- 構造預測集,讀入方式與訓練集相同pandas.read_csv()讀入,這裡為了方便直接取了訓練集(剔除admit列)。
- 通過result.predict(“引數的值”)進行預測
- 分析結果,求得命中率等相關值。
#拷貝訓練集資料
combos = copy.deepcopy(data)
predict_cols = combos.columns[1:]
#設定引數的常量
combos['intercept']=1.0
#進行預測
combos['predict']=result.predict(combos[predict_cols])
tot = 0
hit = 0;
for value in combos.values:
predict = value[-1]
admit = int(value[0])
if predict >=0.5:
tot+=1
if admit == 1:
hit+=1
print 'Total: %d ,Hit: %d ,Precision: %.2f'%(tot,hit,100.0*hit/tot)結果分析
通過result.summary()方法檢視相關資訊。
print result.summary()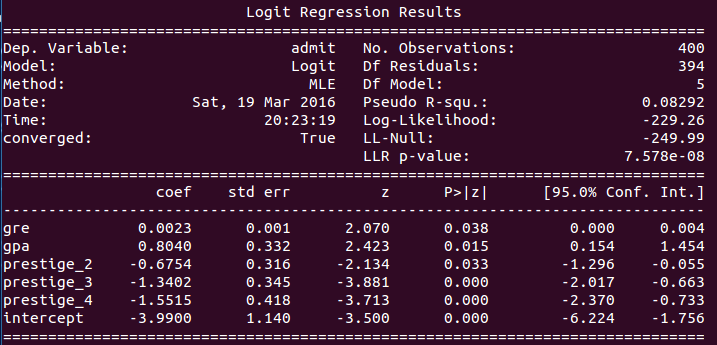
通過這個表我們可以看到模型的引數的值,以及總的擬合質量
檢視每個引數的置信區間
# 檢視每個係數的置信區間
print result.conf_int()
# 0 1
# gre 0.000120 0.004409
# gpa 0.153684 1.454391
# prestige_2 -1.295751 -0.055135
# prestige_3 -2.016992 -0.663416
# prestige_4 -2.370399 -0.732529
# intercept -6.224242 -1.755716Summary
Python庫中幾乎包含了常見機器學習中我們需要做的所有操作,在訓練機器學習模型的時候我們只用學會如何使用它就好。