Python: sklearn庫中資料預處理函式fit_transform()和transform()的區別
阿新 • • 發佈:2019-01-10
敲《Python機器學習及實踐》上的code的時候,對於資料預處理中涉及到的fit_transform()函式和transform()函式之間的區別很模糊,查閱了很多資料,這裡整理一下:
涉及到這兩個函式的程式碼如下:
# 從sklearn.preprocessing匯入StandardScaler from sklearn.preprocessing import StandardScaler # 標準化資料,保證每個維度的特徵資料方差為1,均值為0,使得預測結果不會被某些維度過大的特徵值而主導 ss = StandardScaler() # fit_transform()先擬合數據,再標準化 X_train = ss.fit_transform(X_train) # transform()資料標準化 X_test = ss.transform(X_test)
我們先來看一下這兩個函式的API以及引數含義:
1、fit_transform()函式
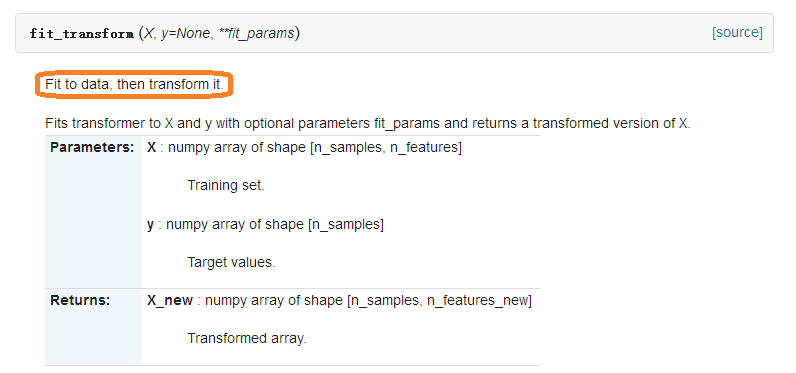
即fit_transform()的作用就是先擬合數據,然後轉化它將其轉化為標準形式
2、transform()函式
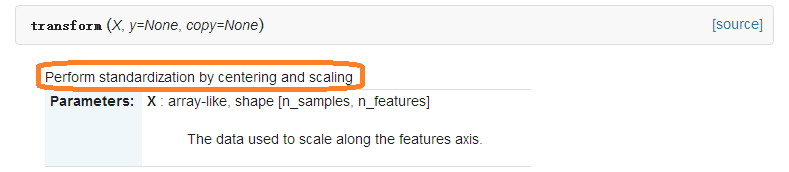
即tranform()的作用是通過找中心和縮放等實現標準化
到了這裡,我們似乎知道了兩者的一些差別,就像名字上的不同,前者多了一個fit資料的步驟,那為什麼在標準化資料的時候不使用fit_transform()函式呢?
原因如下:
為了資料歸一化(使特徵資料方差為1,均值為0),我們需要計算特徵資料的均值μ和方差σ^2,再使用下面的公式進行歸一化:

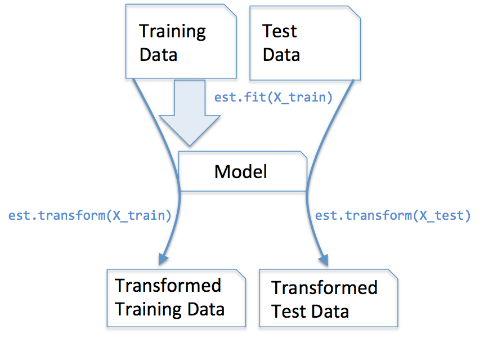
我們在訓練集上呼叫fit_transform(),其實找到了均值 μ和方差σ^2,即我們已經找到了轉換規則,我們把這個規則利用在訓練集上,同樣,我們可以直接將其運用到測試集上(甚至交叉驗證集),所以在測試集上的處理,我們只需要標準化資料而不需要再次擬合數據。用一幅圖展示如下: