
矩陣特徵分解介紹及雅克比(Jacobi)方法實現特徵值和特徵向量的求解(C++/OpenCV/Eigen)
對角矩陣(diagonal matrix):只在主對角線上含有非零元素,其它位置都是零,對角線上的元素可以為0或其它值。形式上,矩陣D是對角矩陣,當且僅當對於所有的i≠j, Di,j= 0. 單位矩陣就是對角矩陣,對角元素全部是1。我們用diag(v)表示一個對角元素由向量v中元素給定的對角方陣。對角矩陣受到關注的部分原因是對角矩陣的乘法計算很高效。計算乘法diag(v)x,我們只需要將x中的每個元素xi放大vi倍。換言之,diag(v)x = v⊙x。計算對角方陣的逆矩陣也很高效。對角方陣的逆矩陣存在,當且僅當對角元素都是非零值,在這種情況下,diag(v)-1=diag([1/v1, …, 1/vn
不是所有的對角矩陣都是方陣。長方形的矩陣也有可能是對角矩陣。非方陣的對角矩陣沒有逆矩陣,但我們仍然可以高效地計算它們的乘法。對於一個長方形對角矩陣D而言,乘法Dx會涉及到x中每個元素的縮放,如果D是瘦長型矩陣,那麼在縮放後的末尾新增一些零;如果D是胖寬型矩陣,那麼在縮放後去掉最後一些元素。
對角矩陣性質:
(1)、對角矩陣都是對稱矩陣;
(2)、對角矩陣是上三角矩陣(對角線左下方的係數全部為零)及下三角矩陣(對角線右上方的係數全部為零);
(3)、單位矩陣In
(4)、一個對角線上元素皆相等的對角矩陣是數乘矩陣,可表示為單位矩陣及一個係數λ的乘積:λI;
(5)、一對角矩陣diag(a1,…,an)的特徵值為a1,…,an。而其特徵向量為單位向量e1,…,en;
(6)、一對角矩陣diag(a1,…,an)的行列式為a1,…,an的乘積。
對稱(symmetric)矩陣:線上性代數中,對稱矩陣是一個方形矩陣,其轉置矩陣和自身相等:A=AT。
對稱矩陣中的右上至左下方向元素以主對角線(左上至右下)為軸進行對稱。若將其寫作A=(aij),則:aij=aji.
當某些不依賴引數順序的雙引數函式生成元素時,對稱矩陣經常會出現。例如,如果A是一個距離度量矩陣,Ai,j
對稱矩陣特性:
(1)、對於任何方形矩陣X,X+XT是對稱矩陣;
(2)、A為方形矩陣是A為對稱矩陣的必要條件;
(3)、對角矩陣都是對稱矩陣;
(4)、兩個對稱矩陣的積是對稱矩陣,當且僅當兩者的乘法可交換。兩個實對稱矩陣乘法可交換當且僅當兩者的特徵空間相同;
(5)、如果X是對稱矩陣,那麼AXAT也是對稱矩陣。
單位向量(unit vector)是具有單位範數(unit norm)的向量:‖x‖2=1.
如果xTy=0,那麼向量x和向量y互相正交(orthogonal)。如果兩個向量都有非零範數,那麼這兩個向量之間的夾角是90度。在Rn中,至多有n個範數非零向量互相正交。如果這些向量不僅互相正交,並且範數都為1,那麼我們稱它們是標準正交(orthogonal)。
正交矩陣(orthogonal matrix)是指行向量和列向量是分別標準正交的方陣:ATA=AAT=I.這意味著A-1=AT.所以正交矩陣受到關注是因為求逆計算代價小。
正交是線性代數的概念,是垂直這一直觀概念的推廣。作為一個形容詞,只有在一個確定的內積空間(內積空間是數學中線性代數裡的基本概念,是增添了一個額外的結構的向量空間。這個額外的結構叫做內積或標量積。內積將一對向量與一個標量連線起來,允許我們嚴格地談論向量的”夾角”和”長度”,並進一步討論向量的正交性)中才有意義。若內積空間中兩向量的內積為0,則稱它們是正交的。如果能夠定義向量間的夾角,則正交可以直觀的理解為垂直。
標準正交基:線上性代數中,一個內積空間的正交基(orthogonal basis)是元素兩兩正交的基。稱基中的元素為基向量。假若,一個正交基的基向量的模長都是單位長度1,則稱這正交基為標準正交基或”規範正交基”(orthogonal basis)。
正交矩陣:在矩陣論中,正交矩陣(orthogonal matrix)是一個方塊矩陣Q,其元素為實數,而且行與列皆為正交的單位向量,使得該矩陣的轉置矩陣為其逆矩陣:QT=Q-1ó QTQ=QQT=I.其中,I為單位矩陣。正交矩陣的行列式值必定為+1或-1。
旋轉矩陣(Rotation matrix):是在乘以一個向量的時候有改變向量的方向但不改變大小的效果並保持了手性的矩陣。旋轉可分為主動旋轉與被動旋轉。主動旋轉是指將向量逆時針圍繞旋轉軸所做出的旋轉。被動旋轉是對座標軸本身進行的逆時針旋轉,它相當於主動旋轉的逆操作。
旋轉矩陣性質:設M是任何維的一般旋轉矩陣:M∈Rn*n
(1)、兩個向量的點積(內積)在它們都被一個旋轉矩陣操作之後保持不變:a·b=Ma·Mb;
(2)、從而得出旋轉矩陣的逆矩陣是它的轉置矩陣:MM-1=MMT=I 這裡的I是單位矩陣;
(3)、一個矩陣是旋轉矩陣,當且僅當它是正交矩陣並且它的行列式是單位一。正交矩陣的行列式是±1;則它包含了一個反射而不是真旋轉矩陣;
(4)、旋轉矩陣是正交矩陣,如果它的列向量形成Rn的一個正交基,就是說在任何兩個列向量之間的標量積是零(正交性)而每個列向量的大小是單位一(單位向量);
在二維空間中,旋轉可以用一個單一的角θ定義。作為約定,正角表示逆時針旋轉。把笛卡爾座標的列向量關於原點逆時針旋轉θ的矩陣是:
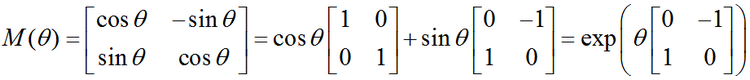
特徵分解(eigen decomposition)是使用最廣的矩陣分解之一,即我們將矩陣分解成一組特徵向量和特徵值。
方陣A的特徵向量(eigen vector)是指與A相乘後相當於對該向量進行縮放的非零向量v:Av=λv。標量λ被稱為這個特徵向量對應的特徵值(eigenvalue)。(類似地,我們也可以定義左特徵向量(left eigen vector) vTA=λVT,但是通常我們更關注右特徵向量(right eigen vector))。
如果v是A的特徵向量,那麼任何縮放後的向量sv(s∈R,s≠0)也是A的特徵向量。此外,sv和v有相同的特徵值。基於這個原因,通常我們只考慮單位特徵向量。
假設矩陣A有n個線性無關的特徵向量{v(1),…,v(n)},對應著特徵值{λ1,…,λn}。我們將特徵向量連線成一個矩陣,使得每一列是一個特徵向量:V=[v(1),…,v(n)].類似地,我們也可以將特徵值連線成一個向量λ=[λ1,…,λn]T。因此A的特徵分解(eigen decomposition)可以記作:A=Vdiag(λ)V-1。
不是每一個矩陣都可以分解成特徵值和特徵向量。在某些情況下,特徵分解存在,但是會涉及到複數,而非實數。每個實對稱矩陣都可以分解成實特徵向量和實特徵值:A=QΛQT。其中Q是A的特徵向量組成的正交矩陣,Λ是對角矩陣。特徵值Λi,i對應的特徵向量是矩陣Q的第i列,記作Q:,i。因為Q是正交矩陣,我們可以將A看作是沿方向v(i)延展λi倍的空間。
雖然任意一個實對稱矩陣A都有特徵分解,但是特徵分解可能並不唯一。如果兩個或多個特徵向量擁有相同的特徵值,那麼在由這些特徵向量產生的生成子空間中,任意一組正交向量都是該特徵值對應的特徵向量。因此,我們可以等價地從這些特徵向量中構成Q作為替代。按照慣例,我們通常按降序排列Λ的元素。在該約定下,特徵分解唯一當且僅當所有的特徵值都是唯一的。
矩陣的特徵分解給了我們很多關於矩陣的有用資訊。矩陣是奇異的當且僅當含有零特徵值。實對稱矩陣的特徵分解也可以用於優化二次方程f(x)=xTAx,其中限制‖x‖2=1。當x等於A的某個特徵向量時,f將返回對應的特徵值。在限制條件下,函式f的最大值是最大特徵值,最小值是最小特徵值。
所有特徵值都是正數的矩陣被稱為正定(positive definite);所有特徵值都是非負數的矩陣被稱為半正定(positive semidefinite)。同樣地,所有特徵值都是負數的矩陣被稱為負定(negative definite);所有特徵值都是非正數的矩陣被稱為半負定(negative semidefinite)。半正定矩陣受到關注是因為它們保證Ⅴx,xTAx≥0。此外,正定矩陣還保證xTAx=0 =>x=0。
特徵分解:線性代數中,特徵分解(Eigende composition),又稱譜分解(Spectral decomposition)是將矩陣分解為由其特徵值和特徵向量表示的矩陣之積的方法。需要注意只有對可對角化矩陣(如果一個方塊矩陣A相似於對角矩陣,也就是說,如果存在一個可逆矩陣P使得P-1AP是對角矩陣,則它就被稱為可對角化的)才可以施以特徵分解。
特徵值和特徵向量:在數學上,特別是線性代數中,對於一個給定的線性變換(在數學中,線性對映(有的書上將”線性變換”作為其同義詞,有的則不然)是在兩個向量空間(包括由函式構成的抽象的向量空間)之間的一種保持向量加法和標量乘法的特殊對映。設V和W是在相同域K上的向量空間。法則f:V→W被稱為是線性對映,如果對於V中任何兩個向量x和y與K中任何標量a,滿足下列兩個條件:可加性:f(x+y)=f(x)+f(y);齊次性:f(ax)=af(x);這等價於要求對於任何向量x1,…,xm和標量a1,…,am,方程f(a1x1+…+amxm)=a1f(x1)+…+amf(xm)成立)A,它的特徵向量(eigen vector,也譯固有向量或本徵向量)v經過這個線性變換之後,得到的新向量與原來的v保持在同一條直線上,但其長度或方向也許會改變。即Av=λv,λ為標量,即特徵向量的長度在該線性變換下縮放的比例,稱λ為其特徵值(本徵值)。如果特徵值為正,則表示v在經過線性變換的作用後方向也不變;如果特徵值為負,說明方向會反轉;如果特徵值為0,則是表示縮回零點。但無論怎樣,仍在同一條直線上。在一定條件下(如其矩陣形式為實對稱矩陣的線性變換),一個變換可以由其特徵值和特徵向量完全表述。
通過雅克比(Jacobi)方法求實對稱矩陣的特徵值和特徵向量操作步驟:S′=GTSG,其中G是旋轉矩陣,S′和S均為實對稱矩陣,S′和S有相同的Frobenius norm,可以用一個最簡單的3維實對稱矩陣為例,根據公式進行詳細推導(參考 維基百科 ):
通過旋轉矩陣將對稱矩陣轉換為近似對角矩陣,進而求出特徵值和特徵向量,對角矩陣中主對角元素即為S近似的實特徵值。Jacobi是通過迭代方法計算實對稱矩陣的特徵值和特徵向量。
(1)、初始化特徵向量V為單位矩陣;
(2)、初始化特徵值eigenvalues為矩陣S主對角線元素;
(3)、將二維矩陣S賦值給一維向量A;
(4)、查詢矩陣S中,每行除主對角元素外(僅上三角部分)絕對值最大的元素的索引賦給indR;
(5)、查詢矩陣S中,第k列,前k個元素中絕對值最大的元素的索引賦給indC;
(6)、查詢pivot的索引(k, l),並獲取向量A中絕對值最大的元素p;
(7)、如果p的絕對值小於設定的閾值則退出迴圈;
(8)、計算sinθ(s)和cosθ(c)的值;
(9)、更新(k, l)對應的A和eigenvalues的值;
(10)、旋轉A的(k,l);
(11)、旋轉特徵向量V的(k,l);
(12)、重新計算indR和indC;
(13)、迴圈執行以上(6)~(12)步,直到達到最大迭代次數,OpenCV中設定迭代次數為n*n*30;
(14)、如果需要對特徵向量和特性值進行sort,則執行sort操作。
以下是分別採用C++(參考opencv sources/modules/core/src/lapack.cpp)和OpenCV實現的求取實對稱矩陣的特徵值和特徵向量:
#include "funset.hpp"
#include <math.h>
#include <iostream>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
#include "common.hpp"
template<typename _Tp>
static inline _Tp hypot(_Tp a, _Tp b)
{
a = std::abs(a);
b = std::abs(b);
if (a > b) {
b /= a;
return a*std::sqrt(1 + b*b);
}
if (b > 0) {
a /= b;
return b*std::sqrt(1 + a*a);
}
return 0;
}
template<typename _Tp>
int eigen(const std::vector<std::vector<_Tp>>& mat, std::vector<_Tp>& eigenvalues, std::vector<std::vector<_Tp>>& eigenvectors, bool sort_ = true)
{
auto n = mat.size();
for (const auto& m : mat) {
if (m.size() != n) {
fprintf(stderr, "mat must be square and it should be a real symmetric matrix\n");
return -1;
}
}
eigenvalues.resize(n, (_Tp)0);
std::vector<_Tp> V(n*n, (_Tp)0);
for (int i = 0; i < n; ++i) {
V[n * i + i] = (_Tp)1;
eigenvalues[i] = mat[i][i];
}
const _Tp eps = std::numeric_limits<_Tp>::epsilon();
int maxIters{ (int)n * (int)n * 30 };
_Tp mv{ (_Tp)0 };
std::vector<int> indR(n, 0), indC(n, 0);
std::vector<_Tp> A;
for (int i = 0; i < n; ++i) {
A.insert(A.begin() + i * n, mat[i].begin(), mat[i].end());
}
for (int k = 0; k < n; ++k) {
int m, i;
if (k < n - 1) {
for (m = k + 1, mv = std::abs(A[n*k + m]), i = k + 2; i < n; i++) {
_Tp val = std::abs(A[n*k + i]);
if (mv < val)
mv = val, m = i;
}
indR[k] = m;
}
if (k > 0) {
for (m = 0, mv = std::abs(A[k]), i = 1; i < k; i++) {
_Tp val = std::abs(A[n*i + k]);
if (mv < val)
mv = val, m = i;
}
indC[k] = m;
}
}
if (n > 1) for (int iters = 0; iters < maxIters; iters++) {
int k, i, m;
// find index (k,l) of pivot p
for (k = 0, mv = std::abs(A[indR[0]]), i = 1; i < n - 1; i++) {
_Tp val = std::abs(A[n*i + indR[i]]);
if (mv < val)
mv = val, k = i;
}
int l = indR[k];
for (i = 1; i < n; i++) {
_Tp val = std::abs(A[n*indC[i] + i]);
if (mv < val)
mv = val, k = indC[i], l = i;
}
_Tp p = A[n*k + l];
if (std::abs(p) <= eps)
break;
_Tp y = (_Tp)((eigenvalues[l] - eigenvalues[k])*0.5);
_Tp t = std::abs(y) + hypot(p, y);
_Tp s = hypot(p, t);
_Tp c = t / s;
s = p / s; t = (p / t)*p;
if (y < 0)
s = -s, t = -t;
A[n*k + l] = 0;
eigenvalues[k] -= t;
eigenvalues[l] += t;
_Tp a0, b0;
#undef rotate
#define rotate(v0, v1) a0 = v0, b0 = v1, v0 = a0*c - b0*s, v1 = a0*s + b0*c
// rotate rows and columns k and l
for (i = 0; i < k; i++)
rotate(A[n*i + k], A[n*i + l]);
for (i = k + 1; i < l; i++)
rotate(A[n*k + i], A[n*i + l]);
for (i = l + 1; i < n; i++)
rotate(A[n*k + i], A[n*l + i]);
// rotate eigenvectors
for (i = 0; i < n; i++)
rotate(V[n*k+i], V[n*l+i]);
#undef rotate
for (int j = 0; j < 2; j++) {
int idx = j == 0 ? k : l;
if (idx < n - 1) {
for (m = idx + 1, mv = std::abs(A[n*idx + m]), i = idx + 2; i < n; i++) {
_Tp val = std::abs(A[n*idx + i]);
if (mv < val)
mv = val, m = i;
}
indR[idx] = m;
}
if (idx > 0) {
for (m = 0, mv = std::abs(A[idx]), i = 1; i < idx; i++) {
_Tp val = std::abs(A[n*i + idx]);
if (mv < val)
mv = val, m = i;
}
indC[idx] = m;
}
}
}
// sort eigenvalues & eigenvectors
if (sort_) {
for (int k = 0; k < n - 1; k++) {
int m = k;
for (int i = k + 1; i < n; i++) {
if (eigenvalues[m] < eigenvalues[i])
m = i;
}
if (k != m) {
std::swap(eigenvalues[m], eigenvalues[k]);
for (int i = 0; i < n; i++)
std::swap(V[n*m+i], V[n*k+i]);
}
}
}
eigenvectors.resize(n);
for (int i = 0; i < n; ++i) {
eigenvectors[i].resize(n);
eigenvectors[i].assign(V.begin() + i * n, V.begin() + i * n + n);
}
return 0;
}
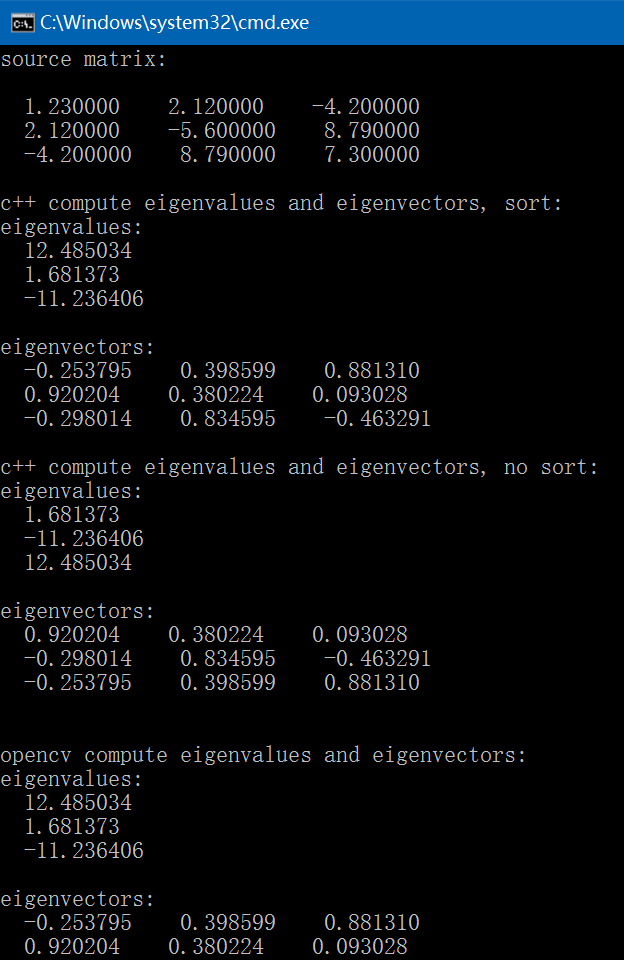
int test_eigenvalues_eigenvectors()
{
std::vector<float> vec{ 1.23f, 2.12f, -4.2f,
2.12f, -5.6f, 8.79f,
-4.2f, 8.79f, 7.3f };
const int N{ 3 };
fprintf(stderr, "source matrix:\n");
int count{ 0 };
for (const auto& value : vec) {
if (count++ % N == 0) fprintf(stderr, "\n");
fprintf(stderr, " %f ", value);
}
fprintf(stderr, "\n\n");
fprintf(stderr, "c++ compute eigenvalues and eigenvectors, sort:\n");
std::vector<std::vector<float>> eigen_vectors1, mat1;
std::vector<float> eigen_values1;
mat1.resize(N);
for (int i = 0; i < N; ++i) {
mat1[i].resize(N);
for (int j = 0; j < N; ++j) {
mat1[i][j] = vec[i * N + j];
}
}
if (eigen(mat1, eigen_values1, eigen_vectors1, true) != 0) {
fprintf(stderr, "campute eigenvalues and eigenvector fail\n");
return -1;
}
fprintf(stderr, "eigenvalues:\n");
std::vector<std::vector<float>> tmp(N);
for (int i = 0; i < N; ++i) {
tmp[i].resize(1);
tmp[i][0] = eigen_values1[i];
}
print_matrix(tmp);
fprintf(stderr, "eigenvectors:\n");
print_matrix(eigen_vectors1);
fprintf(stderr, "c++ compute eigenvalues and eigenvectors, no sort:\n");
if (eigen(mat1, eigen_values1, eigen_vectors1, false) != 0) {
fprintf(stderr, "campute eigenvalues and eigenvector fail\n");
return -1;
}
fprintf(stderr, "eigenvalues:\n");
for (int i = 0; i < N; ++i) {
tmp[i][0] = eigen_values1[i];
}
print_matrix(tmp);
fprintf(stderr, "eigenvectors:\n");
print_matrix(eigen_vectors1);
fprintf(stderr, "\nopencv compute eigenvalues and eigenvectors:\n");
cv::Mat mat2(N, N, CV_32FC1, vec.data());
cv::Mat eigen_values2, eigen_vectors2;
bool ret = cv::eigen(mat2, eigen_values2, eigen_vectors2);
if (!ret) {
fprintf(stderr, "fail to run cv::eigen\n");
return -1;
}
fprintf(stderr, "eigenvalues:\n");
print_matrix(eigen_values2);
fprintf(stderr, "eigenvectors:\n");
print_matrix(eigen_vectors2);
return 0;
}
以下是採用Eigen實現的求取特徵值和特徵向量的code:
#include "funset.hpp"
#include <math.h>
#include <iostream>
#include <vector>
#include <string>
#include <opencv2/opencv.hpp>
#include <Eigen/Dense>
#include "common.hpp"
int test_eigenvalues_eigenvectors()
{
std::vector<float> vec{ 1.23f, 2.12f, -4.2f,
2.12f, -5.6f, 8.79f,
-4.2f, 8.79f, 7.3f };
const int N{ 3 };
fprintf(stderr, "source matrix:\n");
print_matrix(vec.data(), N, N);
fprintf(stderr, "\n");
Eigen::Map<Eigen::MatrixXf> m(vec.data(), N, N);
Eigen::EigenSolver<Eigen::MatrixXf> es(m);
Eigen::VectorXf eigen_values = es.eigenvalues().real();
fprintf(stderr, "eigen values:\n");
print_matrix(eigen_values.data(), N, 1);
Eigen::MatrixXf eigen_vectors = es.eigenvectors().real();
fprintf(stderr, "eigen vectors:\n");
print_matrix(eigen_vectors.data(), N, N);
return 0;
}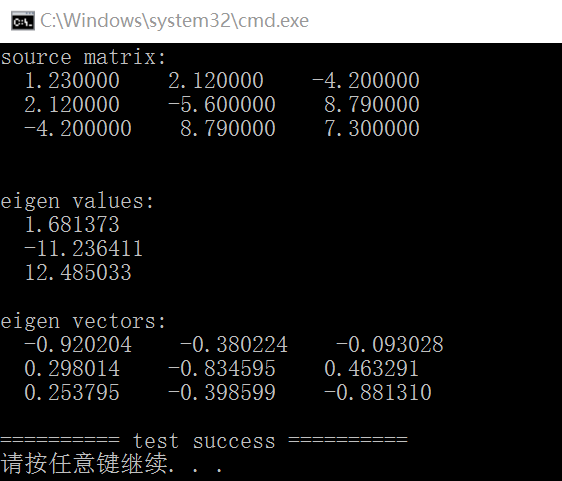 由以上結果可見:C++、OpenCV、Eigen結果是一致的。
由以上結果可見:C++、OpenCV、Eigen結果是一致的。GitHub: