
CNN文字分類
文字分類是NLP領域的一個重要的子任務,文字分類的目標是自動的將文字打上已經定義好的標籤,常見的文字分類任務有:垃圾郵件過濾、情感分析、新聞分類等等。
程式碼是來自
大家可以自行下載閱讀,下面僅僅是自己對程式碼的一個解讀,僅此而已,若有不合適的地方,希望大家多多指出,共同交流
1、任務
對給定的一個文字進行盜竊型別的判斷
2、型別種類
入戶盜竊、扒竊、一般盜竊
程式碼的具體閱讀如下所示:
1、檔案的位置
base_dir = 'data/cnews' train_dir = os.path.join(base_dir, 'cnews.train.txt') test_dir = os.path.join(base_dir, 'cnews.test.txt') val_dir = os.path.join(base_dir, 'cnews.val.txt') vocab_dir = os.path.join(base_dir, 'cnews.vocab.txt') print ('train_dir',train_dir) print ('test_dir',test_dir) print ('val_dir',val_dir) print ('vocab_dir',vocab_dir)
打印出的結果如下所示:
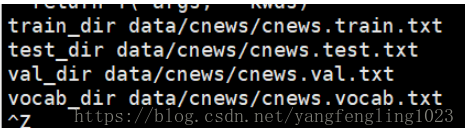
os.path.join()函式的作用是將各個路徑進行拼接操作
2、主函式
if __name__ == '__main__': if len(sys.argv) != 2 or sys.argv[1] not in ['train', 'test']: raise ValueError("""usage: python run_cnn.py [train / test]""") categories = ['入戶盜竊', '扒竊', '一般盜竊'] if not os.path.exists(vocab_dir): # 如果不存在詞彙表,重建 build_vocab(train_dir, vocab_dir, config.vocab_size) categories, cat_to_id = read_category(categories) ##將文字的標籤進行id轉換 words, word_to_id = read_vocab(vocab_dir) ##字、字對應的id號 #該處是使用提前訓練好的字向量,但此處註釋掉了,此次不進行講解 #embedding = embed(word_to_id) print('Configuring CNN model...') config = TCNNConfig(embedding) config.vocab_size = len(words) print('vocab_size',config.vocab_size) ##2426
程式執行時的命令列:
python run_cnn.py train
(1)build_vocab()函式:
該函式的主要功能是建立字典
def build_vocab(train_dir, vocab_dir, vocab_size=5000): """根據訓練集構建詞彙表,儲存""" data_train, _ = read_file(train_dir) ##data_train儲存的是一個一個的文字 print(data_train) all_data = [] for content in data_train: all_data.extend(content) counter = Counter(all_data) count_pairs = counter.most_common(vocab_size - 1) words, _ = list(zip(*count_pairs)) # 新增一個 <PAD> 來將所有文字pad為同一長度 words = ['<PAD>'] + list(words) open_file(vocab_dir, mode='w').write('\n'.join(words) + '\n')
該函式主要是構建詞彙表,使用字元級的表示,這一函式會將詞彙表儲存下來,避免每一次重複處理
def read_file(filename):
"""讀取檔案資料"""
contents, labels = [], []
with open_file(filename) as f:
for line in f:
try:
label, content = line.strip().split('\t')
if content:
contents.append(list(native_content(content)))
labels.append(native_content(label))
except:
pass
return contents, labels(2)open_file()函式:
def open_file(filename, mode='r'):
"""
常用檔案操作,可在python2和python3間切換.
mode: 'r' or 'w' for read or write
"""
if is_py3:
return open(filename, mode, encoding='utf-8', errors='ignore')
else:
return open(filename, mode)
例子:
文字中儲存的內容如下所示:
入戶盜竊 被告人周×於2014年1月26日,趁無人之機,用事先偷取的鑰匙進入被害人李×租住地,竊取“科龍牌”KFR-26W/VGFDBP-3型壁掛式空調1臺、“美的牌”F40-15A4型熱水機1臺及椅子6把、茶几1張。
data_train, _ = read_file()之後:
data_train = ['二、被告人周×於2014年1月26日,趁無人之機,用事先偷取的鑰匙進入被害人李×租住地,竊取“科龍牌”KFR-26W/VGFDBP-3型壁掛式空調1臺、“美的牌”F40-15A4型熱水機1臺及椅子6把、茶几1張。']
_儲存的是labels:['入戶盜竊']
執行完build_vocab()函式之後新生成的字典檔案的內容如下所示:
<PAD>
1
、
人
2
4
6
……
幾
張
(3)read_category()函式
def read_category(categories):
"""讀取分類目錄,固定"""
categories = ['入戶盜竊', '扒竊', '一般盜竊']
categories = [native_content(x) for x in categories]
cat_to_id = dict(zip(categories, range(len(categories)))) #將類別分別進行id的轉換
return categories, cat_to_id該函式的目的主要是將類別進行id的轉換,即使用數字對分類的類別進行表示。將分類目錄固定,轉換為{類別:id}表示
(4)read_vocab()函式
def read_vocab(vocab_dir):
"""讀取詞彙表"""
with open_file(vocab_dir) as fp:
# 如果是py2 則每個值都轉化為unicode
words = [native_content(_.strip()) for _ in fp.readlines()]
word_to_id = dict(zip(words, range(len(words))))
return words, word_to_id該函式是從已經建立好的字典檔案中讀取每一個字,同時進行id的轉換
3、模型引數的設定
模型引數設定的呼叫:
config = TCNNConfig()
模型引數設定的類:
class TCNNConfig(object): ##神經網路相關引數的設定
"""CNN配置引數"""
def __init__(self,embedding):
self.embedding = embedding
embedding_dim = 100 # 詞向量維度
seq_length = 600 # 序列長度 即文字設定的長度
num_classes = 3 # 類別數 3類
num_filters = 256 # 卷積核數目
kernel_size = 5 # 卷積核尺寸
vocab_size = 5000 # 詞彙表達小
hidden_dim = 128 # 全連線層神經元
dropout_keep_prob = 0.5 # dropout保留比例
learning_rate = 1e-3 # 學習率
batch_size = 64 # 每批訓練大小
num_epochs = 10 # 總迭代輪次
print_per_batch = 100 # 每多少輪輸出一次結果
save_per_batch = 10 # 每多少輪存入tensorboard
##提前訓練好的詞向量可以放在這個裡面,進行後續得網路的輸入
# embedding = tf.get_variable('embedding', [vocab_size,embedding_dim]) 4、網路層的理解
(1)模型的呼叫:
model = TextCNN(config)
(2)模型的定義
class TextCNN(object):
"""文字分類,CNN模型"""
def __init__(self, config):
self.config = config
# 三個待輸入的資料,首先定義我們傳遞給我們網路的輸入資料
##seq_length :文字的長度
##num_classes 標籤的數量
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y') self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
def cnn(self):
"""CNN模型"""
# 詞向量對映
with tf.device('/cpu:0'):
#下面是輸入的向量時隨機進行初始化的
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim]) ##詞向量的初始值為隨機值
# print('embedding',embedding) ##embedding <tf.Variable 'embedding:0' shape=(2426, 100) dtype=float32_ref>
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
#
# ##下面是使用訓練好的字向量進行訓練
# embed = tf.Variable(initial_value=self.config.embedding, dtype=tf.float32)
# print('self.config.embedding', embed)
# embedding_inputs = tf.nn.embedding_lookup(embed, self.input_x)
# print('self.input_x',self.input_x) ##Tensor("input_x:0", shape=(?, 600), dtype=int32)
with tf.name_scope("cnn"):
# CNN layer
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv') ##256,5
# print('embedding_inputs',embedding_inputs) ##Tensor("embedding_lookup:0", shape=(?, 600, 100), dtype=float32, device=/device:CPU:0)
# print('conv',conv) ##Tensor("cnn/conv/BiasAdd:0", shape=(?, 596, 256), dtype=float32) 596 = 600-5+1
# global max pooling layer
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp') ##取最大值 是在第二維上進行最大值的取出
# print('gmp',gmp)##Tensor("cnn/gmp:0", shape=(?, 256), dtype=float32)
with tf.name_scope("score"):
# 全連線層,後面接dropout以及relu啟用
fc = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分類器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
# print('self.logits',self.logits) #self.logits Tensor("score/fc2/BiasAdd:0", shape=(?, 3), dtype=float32)
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 預測類別
with tf.name_scope("optimize"):
# 損失函式,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y) ##返回的是一個向量
# print('cross_entropy',cross_entropy) #cross_entropy Tensor("optimize/Reshape_2:0", shape=(?,), dtype=float32)
self.loss = tf.reduce_mean(cross_entropy) ##對向量求均值,計算loss 損失函式
'''
,logits是作為softmax的輸入。經過softmax的加工,就變成“歸一化”的概率(設為q),然後和labels代表的概率分佈(設為q),於是,整個函式的功能就是前面的計算labels(概率分佈p)和logits(概率分佈q)之間的交叉熵
'''
# 優化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 準確率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls) ##bool型
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) ##資料型別的轉換,同時進行計算準確率
程式碼的理解:
tf.placeholder建立一個佔位符變數,第一個維度表示的是批量大小,使用None表示,第二個引數是輸入張量的形狀
tf.nn.softmax_cross_entropy_with_logits是一個損失的函式,計算每個類的交叉熵損失,給定我們的分數和正確的輸入標籤,對損失進行計算平均值
損失是我們訓練模型好壞的衡量標準,目的是降低損失,減少網路的誤差,分類問題的標準損失函式是交叉熵損失
CNN網路:
程式碼中的卷積神經網路時最基本的網路,有input layer、convolutional layer、max-pooling layer以及最後的輸出的softmax layer
(1)input layer層
使用隨機初始化的embedding作為輸入層輸入的資訊
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim]) ##詞向量的初始值為隨機值
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
此時的輸入的shape為:shape=(?, 600, 100)
(2)convolutional layer層
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv')
引數的大小:
embedding_inputs:shape=(?, 600, 100)
self.config.num_filters:256 卷積核數目 卷積出的最後一個維度 256個卷積核
self.config.kernel_size:5 卷積核尺寸 一維卷積視窗大大小
輸出的維度大小:
shape=(?, 596, 256)
其中596 = 600-5+1
256個卷積核的初始化的大小是隨機的,所以對句子進行256個卷積結果是不同的,即使初始化卷積核的大小都是一樣的,但是根據標籤進行調參時,也會將卷積核矩陣中的內容進行訓練修改,此時的卷積核矩陣中的資料相當於傳統神經網路的權重引數W
對句子中的每一個字的向量的每一維度都進行引數的學習
tf.layers.conv1d()功能:
生成卷積核,對輸入層進行卷積,產生輸出的tensor
(3)max-pooling layer層
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp') ##取最大值 是在第二維上進行最大值的取出
print('gmp',gmp)##Tensor("cnn/gmp:0", shape=(?, 256), dtype=float32)
(4)softmax layer層
# 全連線層,後面接dropout以及relu啟用
fc = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分類器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
print('self.logits',self.logits) #self.logits Tensor("score/fc2/BiasAdd:0", shape=(?, 3), dtype=float32)
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 預測類別
在自然語言處理中,我們假設一個序列是600個單詞,每個單詞的詞向量是300維,那麼一個序列輸入到網路中就是(600,300),當我使用Conv1D進行卷積的時候,實際上就完成了直接在序列上的卷積,卷積的時候實際是以(3,300)進行卷積,又因為每一行都是一個詞向量,因此使用Conv1D(kernel_size=3)也就相當於使用神經網路進行了n_gram=3的特徵提取了。這也是為什麼使用卷積神經網路處理文字會非常快速有效的內涵。
5、模型的訓練
if sys.argv[1] == 'train':
train()
else:
test()
具體的train()函式程式碼如下所示:
def train():
print("Configuring TensorBoard and Saver...")
# 配置 Tensorboard,重新訓練時,請將tensorboard資料夾刪除,不然圖會覆蓋
tensorboard_dir = 'tensorboard/textcnn'
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
tf.summary.scalar("loss", model.loss)
tf.summary.scalar("accuracy", model.acc)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 配置 Saver
saver = tf.train.Saver()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("Loading training and validation data...")
# 載入訓練集與驗證集
start_time = time.time()
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, config.seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, config.seq_length)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# 建立session
session = tf.Session()
session.run(tf.global_variables_initializer())
writer.add_graph(session.graph)
print('Training and evaluating...')
start_time = time.time()
total_batch = 0 # 總批次
best_acc_val = 0.0 # 最佳驗證集準確率
last_improved = 0 # 記錄上一次提升批次
require_improvement = 1000 # 如果超過1000輪未提升,提前結束訓練
flag = False
for epoch in range(config.num_epochs):
print('Epoch:', epoch + 1)
batch_train = batch_iter(x_train, y_train, config.batch_size)
for x_batch, y_batch in batch_train:
feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob)
if total_batch % config.save_per_batch == 0:
# 每多少輪次將訓練結果寫入tensorboard scalar
s = session.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, total_batch)
if total_batch % config.print_per_batch == 0:
# 每多少輪次輸出在訓練集和驗證集上的效能
feed_dict[model.keep_prob] = 1.0
loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict)
loss_val, acc_val = evaluate(session, x_val, y_val) # todo
if acc_val > best_acc_val:
# 儲存最好結果
best_acc_val = acc_val
last_improved = total_batch
saver.save(sess=session, save_path=save_path)
improved_str = '*'
else:
improved_str = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \
+ ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss_train, acc_train, loss_val, acc_val, time_dif, improved_str))
session.run(model.optim, feed_dict=feed_dict) # 執行優化
total_batch += 1
if total_batch - last_improved > require_improvement:
# 驗證集正確率長期不提升,提前結束訓練
print("No optimization for a long time, auto-stopping...")
flag = True
break # 跳出迴圈
if flag: # 同上
break
對train()函式進行分析:
(1)process_file()函式
def process_file(filename, word_to_id, cat_to_id, max_length=600):
"""將檔案轉換為id表示"""
contents, labels = read_file(filename)
'''
一個句子放在一個列表中,且字與字之間是分開放的,將所有的句子放在一個列表contents中
'''
data_id, label_id = [], []
for i in range(len(contents)):
data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id])
label_id.append(cat_to_id[labels[i]])
# 使用keras提供的pad_sequences來將文字pad為固定長度
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id)) # 將標籤轉換為one-hot表示
return x_pad, y_pad該函式主要實現了將訓練語料、開發集語料、測試集語料中的每一句話中的每一個字進行id的轉換,同時做padding,將所有的句子長度進行統一長度
將資料集從文字轉換為固定長度的id序列表示
對於CNN,輸入與輸出都是固定的,當每一個句子長短不一是,需要做定長處理,超過的截斷,不足的補0,注意補充的0對後面的結果沒有影響,因為後面的max-pooling只會輸出最大值,補0的項會被過濾掉
(2)batch_iter()函式
def batch_iter(x, y, batch_size=64):
"""生成批次資料"""
data_len = len(x)
##可以將語料分成多少個batch_size
num_batch = int((data_len - 1) / batch_size) + 1
##做shuffle 即進行對語料的前後順序進行打亂 在整個語料上進行打亂操作
indices = np.random.permutation(np.arange(data_len))
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i * batch_size
##只有在最後一個batch上,才有可能取data_len,前面的都是取前者
end_id = min((i + 1) * batch_size, data_len)
yield x_shuffle[start_id:end_id], y_shuffle[start_id:end_id]該函式主要是為神經網路的訓練準備經過shuffle的批次的資料
網路的大致結構如下所示:
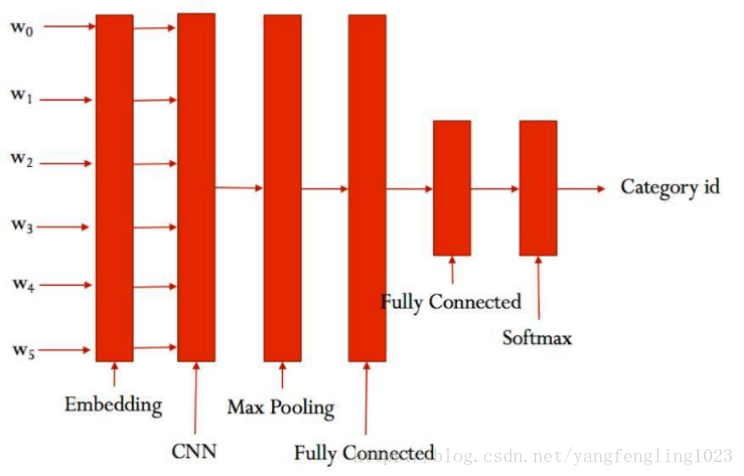
CNN網路的理解:
1、輸入層
輸入層輸入的是句子中的字對應的向量,假設句子有n個字,向量的維度為k,則輸入的是一個nxk的矩陣(在CNN中可以看作一副高度為n、寬度為k的影象),在本文中輸入的矩陣大小為:600x100,一個句子的最大長度設定為600,每一個字的字向量長度設定為100維
對於未登入詞,對映到PAD上
輸入的矩陣可以是靜態的,也可以是動態的。靜態指的是字向量是固定不變的,而動態則是在模型訓練過程中,字向量也被當做是可以進行優化的引數,通常把反向誤差傳播導致字向量中值發生變化的這一過程稱為Finetune。若字向量是隨機初始化的,不僅訓練得到了CNN分類模型,還得到了字向量這個副產品,如果已經有訓練的字向量,那麼其實是一個遷移學習的過程
Embedding layer:通過一個隱藏層,將one-hot編碼的詞投影到一個低維空間中,本質上是特徵提取器,在指定維度中編碼語義特徵,這樣,語義相近的詞,它們的歐氏距離或餘弦距離也比較近
執行python run_cnn.py train,顯示如下所示:
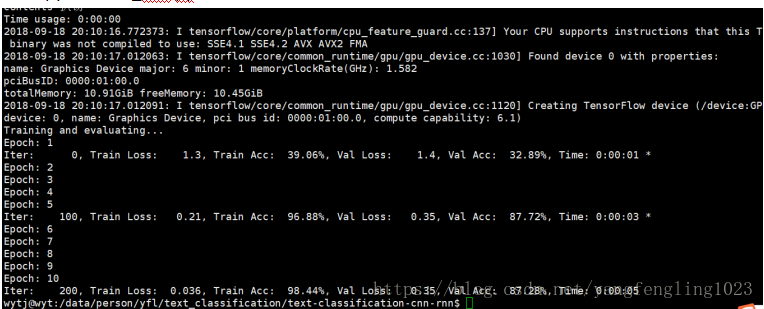
執行python run_cnn.py test,結果如下所示:
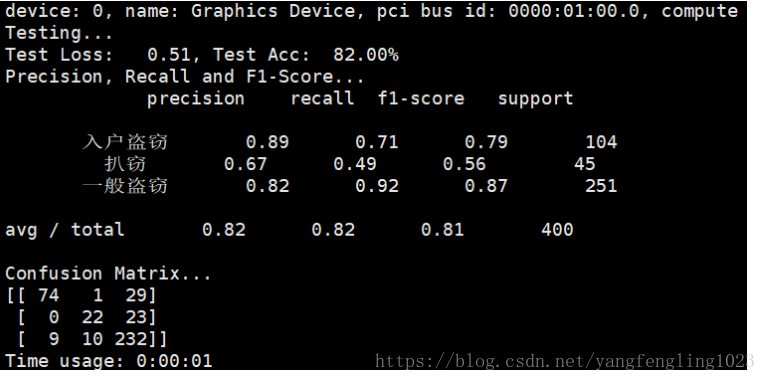
文中有不對的地方,歡迎指出,共同交流