
測序資料質控-FastQC
通常我們下機得到的資料是raw reads,但是公司通常會質控一份給我們,所以到很多人手上就是clean data了。我們再次使用fastqc來進行測序資料質量檢視以及結果分析。
fastqc的操作:
1. FastQC使用 fastqc -f [bam | sam | fastq] -o [output] [filename1 filename2] 常用選項: -f --format:輸入檔案格式.【bam,sam,fastq檔案格式】 -o --outdir:輸出資料夾指定 -t --threads:執行緒數 非常用選項--noextract:結果檔案壓縮 [預設]
-c --contaminants:指定汙染序列。檔案格式 name[tab]sequence
-a --adapters:指定接頭序列。檔案格式name[tab]sequence
-k --kmers:指定kmers長度(2-10bp,預設7bp)
-q --quiet: 安靜模式-不顯示進展
# 不顯示此類進展 Approx 55% complete for ERR522959_2.fastq Approx 60% complete for ERR522959_2.fastq Approx 65% complete for ERR522959_2.fastq Approx 70% complete for ERR522959_2.fastq
1.下載並安裝fastqc
wget http://www.bioinformatics.babraham.ac.uk/projects/fastqc/fastqc_v0.11.8.zip unzip fastqc_v0.11.8.zip cd FastQC chmod 755 fastqc
2.下載測序資料
資料來源:單細胞RNA-seq,SMART-seq2. “a single cell from an mESC dataset produced by (Kolodziejczyk et al.
wget ftp://ftp.sra.ebi.ac.uk/vol1/fastq/ERR522/ERR522959/ERR/ERR522959_1.fastq.gz wget ftp://ftp.sra.ebi.ac.uk/vol1/fastq/ERR522/ERR522959/ERR/ERR522959_1.fastq.gz
3. 執行fastqc
nohup ~/software/FastQC/fastqc -f fastq -o result/ ERR522959_1.fastq ERR522959_2.fastq &
4. 結果檔案分析

zip檔案包含了html檔案,裡面有資料質量的圖片。
我們來檢視html檔案

各種顏色是各項標準分析結果:綠色代表"PASS";
黃色代表"WARN";紅色代表"FAIL"。
4.1 Basic Statics
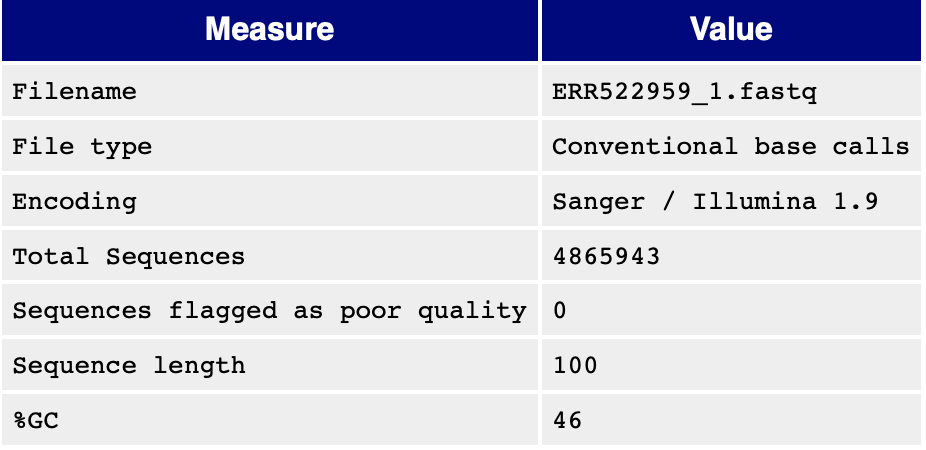
一些基本資訊在這個表格,其中的Encoding 很重要,表示測序資料的編碼方式。編碼方式有很多種:

這裡的Illumina1.9 就是 Phred+33。
4.2 每條reads不同位置(1-100bp)的測序質量統計
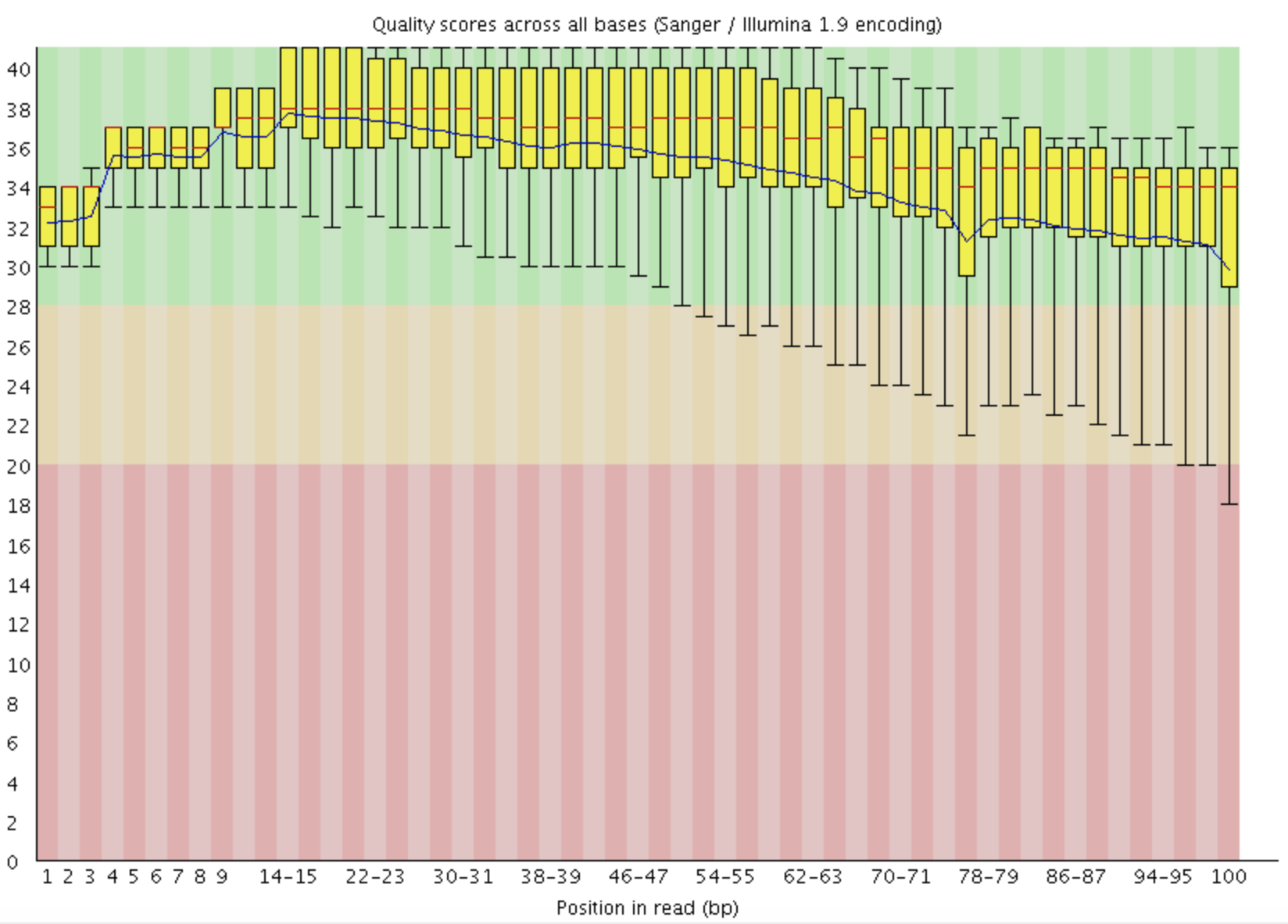
這是一個boxplot,注意看橫座標1-100bp的表示方式。一首一尾是單bp的,中間部分是2bp一個單位。Y軸是測序的質量Q=Phred=-log10(error rate),所以Q=20時,錯誤率為0.01,就是99%的正確率(兩個9,Q20)。Q=30, 錯誤率就是0.001, 就是99.9%的正確率(三個9,Q30),通常測序合同對Q20,Q30有指標要求。紅色表示中位數,黃色是25%-75%區間,觸鬚是10%-90%區間,藍線是平均數。平均每個鹼基的測序質量boxplot下四分位線在30分以上,則認為測序質量非常好;一般情況下,reads首尾質量較差。若任一位置的下四分位數低於10或中位數低於25,報"WARN";若任一位置的下四分位數低於5或中位數低於20,報"FAIL"。
4.3
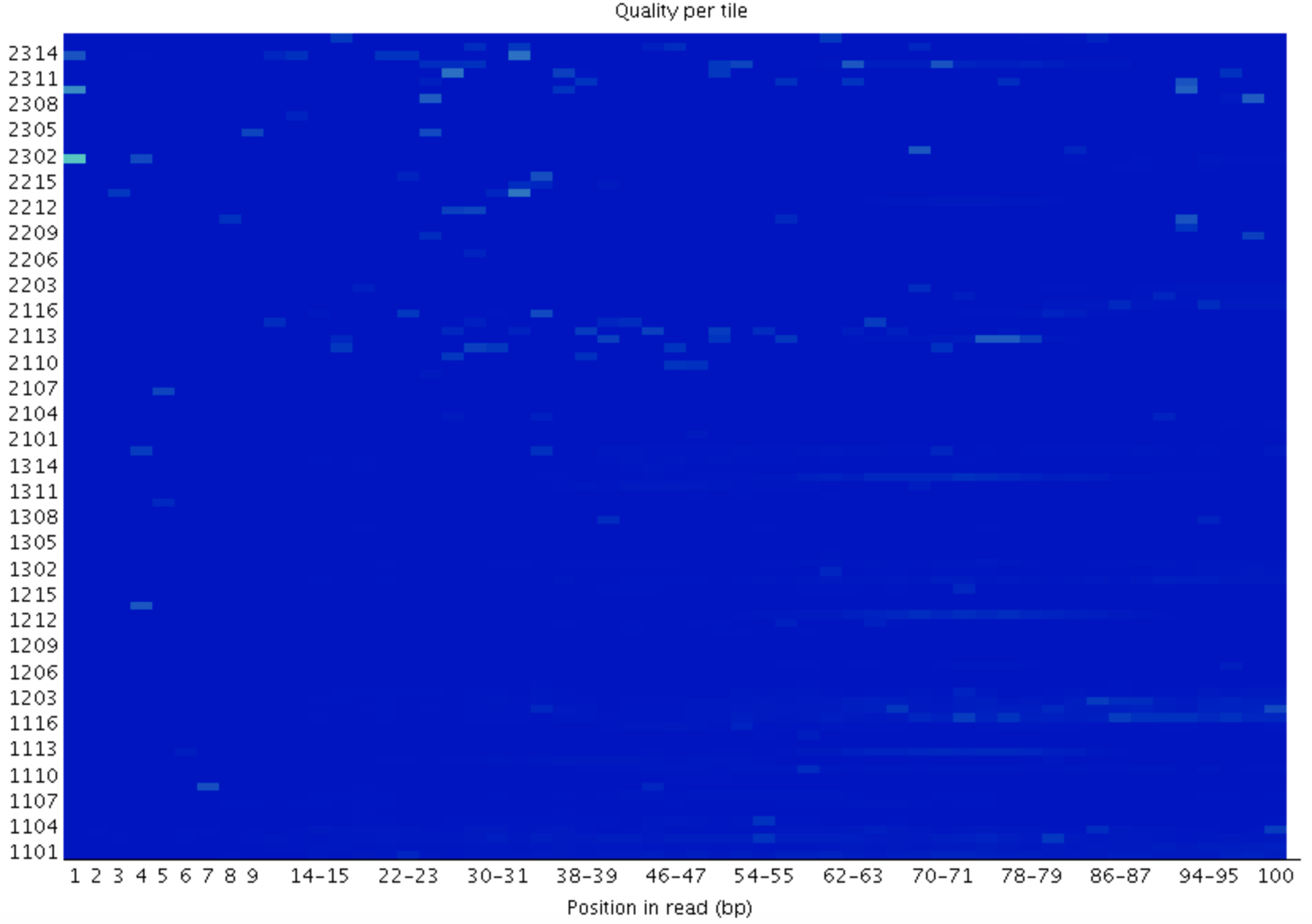
檢查reads中每一個鹼基位置在不同的測序小孔之間的偏離度,藍色表示低於平均偏離度,偏離度小,質量好;越紅表示偏離平均質量越多,質量也越差。如果出現質量問題可能是短暫的,如有氣泡產生,也可能是長期的,如在某一小孔中存在殘骸,問題不大。

橫軸為序列測序質量,縱軸是reads數目。一般認為90%的reads測序質量在35分以上,則認為該測序質量非常好。
當測序質量峰值小於27(錯誤率0.2%)時報"WARN";
當峰值小於20(錯誤率1%)時報"FAIL"。
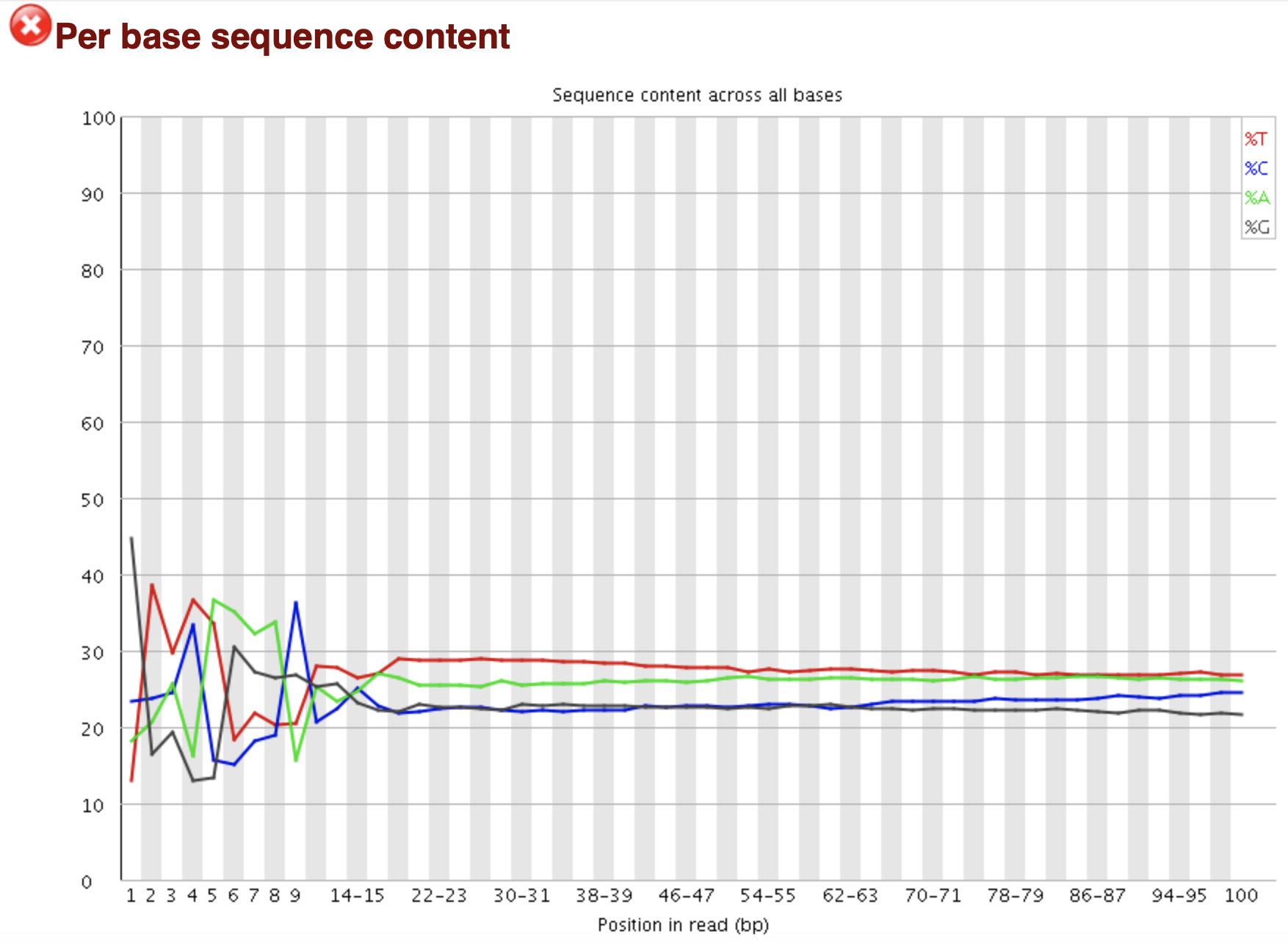
統計reads每個位置ATCG四種鹼基的分佈:
橫軸為鹼基位置,縱軸為百分比。因為隨機的文庫中,正常情況下所有位置出現某種鹼基的概率是相近的,因此好的測序結果中四條線應該平行且接近。當部分位置鹼基的比例出現bias時,即四條線在某些位置紛亂交織,往往提示我們有overrepresented sequence的汙染。當所有位置的鹼基比例一致的表現出bias時,即四條線平行但分開,往往代表文庫有bias (建庫過程或本身特點),或者是測序中的系統誤差。
當任一位置的A/T比例與G/C比例相差超過10%,報"WARN";
當任一位置的A/T比例與G/C比例相差超過20%,報"FAIL"。
 統計reads的平均GC含量分佈
統計reads的平均GC含量分佈
紅線是實際情況,藍線是理論分佈(正態分佈,均值不一定在50%,而是由平均GC含量推斷的)。 曲線形狀的偏差往往是由於文庫的汙染或是部分reads構成的子集有偏差(overrepresented reads)。形狀接近正態但偏離理論分佈的情況提示我們可能有系統偏差。
偏離理論分佈的reads超過15%時,報"WARN";偏離理論分佈的reads超過30%時,報"FAIL"。

reads某個位置無法確定是何種鹼基時,使用N代替;
正常情況下,N的比例是很小的,所以圖上常常看到一條直線,但放大Y軸之後會發現還是有N的存在,這不算問題。當Y軸在0%-100%的範圍內也能看到“鼓包”時,說明測序系統出了問題。
當任意位置的N的比例超過5%,報"WARN";
當任意位置的N的比例超過20%,報"FAIL"。
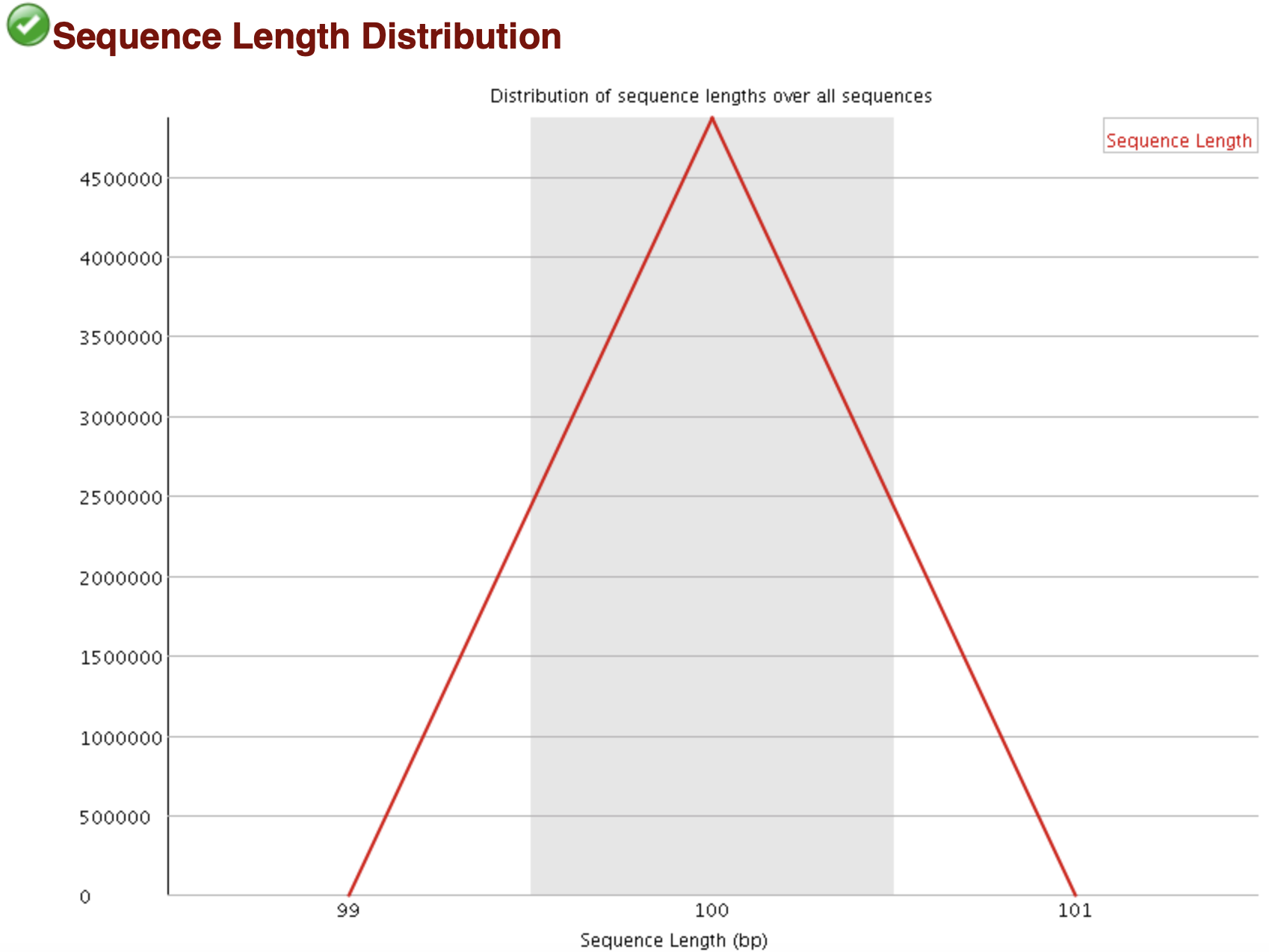
reads長度分佈
為了防止建庫或者測序時有一些不規則長度的序列也被進行測序而進行的一個對長度的統計,當所有序列的長度不一樣,fastqc就會警告。
當reads長度不一致時報"WARN";
當有長度為0的read時報“FAIL”。
統計reads重複水平測序本身就會產生重複reads,測序深度越高,reads重複數越大;如果重複出現峰值,就提示可能b存在偏差(如建庫過程中的PCR duplication)。
橫座標是重複的次數,縱座標是duplicated reads佔unique reads種數百分比。
fastqc抽取reads檔案前200,000條reads統計其重複情況。重複數目大於等於10的reads被合併統計,這也是為什麼我們看到上圖的最右側略有上揚。大於75bp的reads只取50bp進行比較。由於reads越長錯誤率越高,所以其重複程度仍有可能被低估。
當非unique的reads佔總數的比例大於20%時,報"WARN";
當非unique的reads佔總數的比例大於50%時,報"FAIL“。
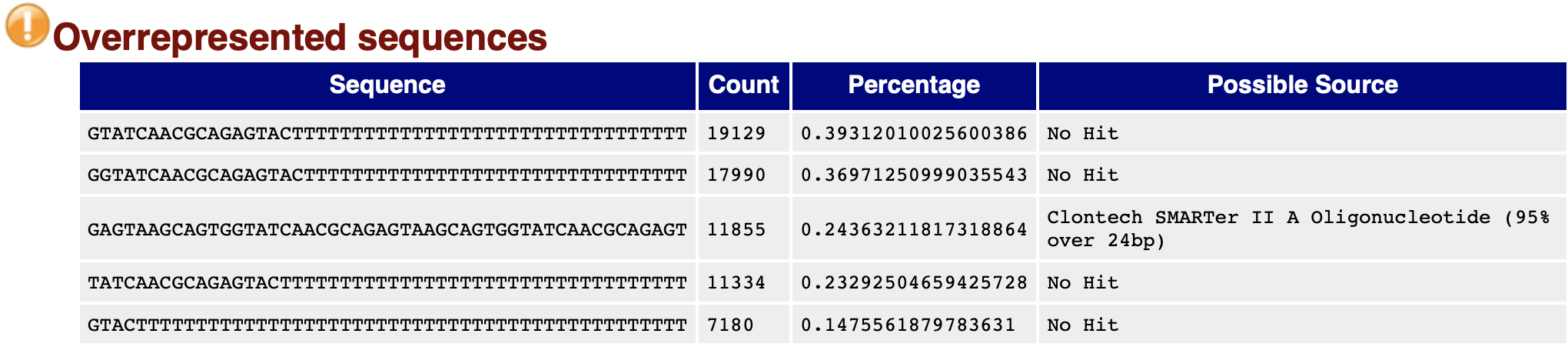
過度重複出現的序列的統計資訊
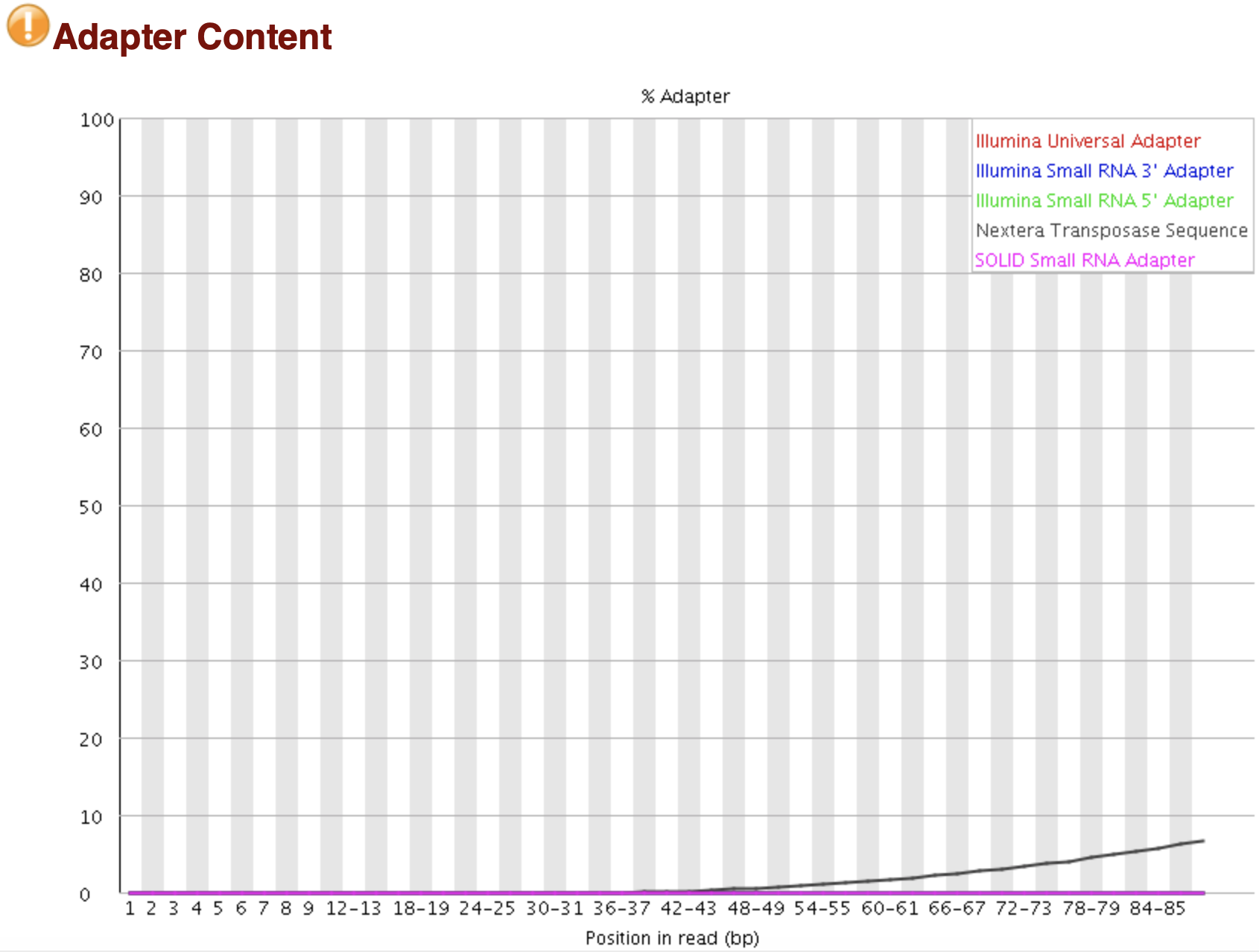
Adapter序列在reads中出現概率
接頭序列統計,>5%時是Warning,>10%時是Failure。
本文圖片由fastqc生成,後面對圖描述的文字來源於簡書: --------------------------------------
“作者:_eason_
連結:https://www.jianshu.com/p/835fd925d6ee
來源:簡書” --------------------------------------