
為什麼L1正則項產生稀疏的權重,L2正則項產生相對平滑的權重
阿新 • • 發佈:2019-01-10
- L1 和L2正則項的定義如下:
- 首先我們先計算一下他們對應的導數,匯入如下所示:
- 假設我們的Loss函式是 , 那麼我們的幾何解釋如下圖所示:
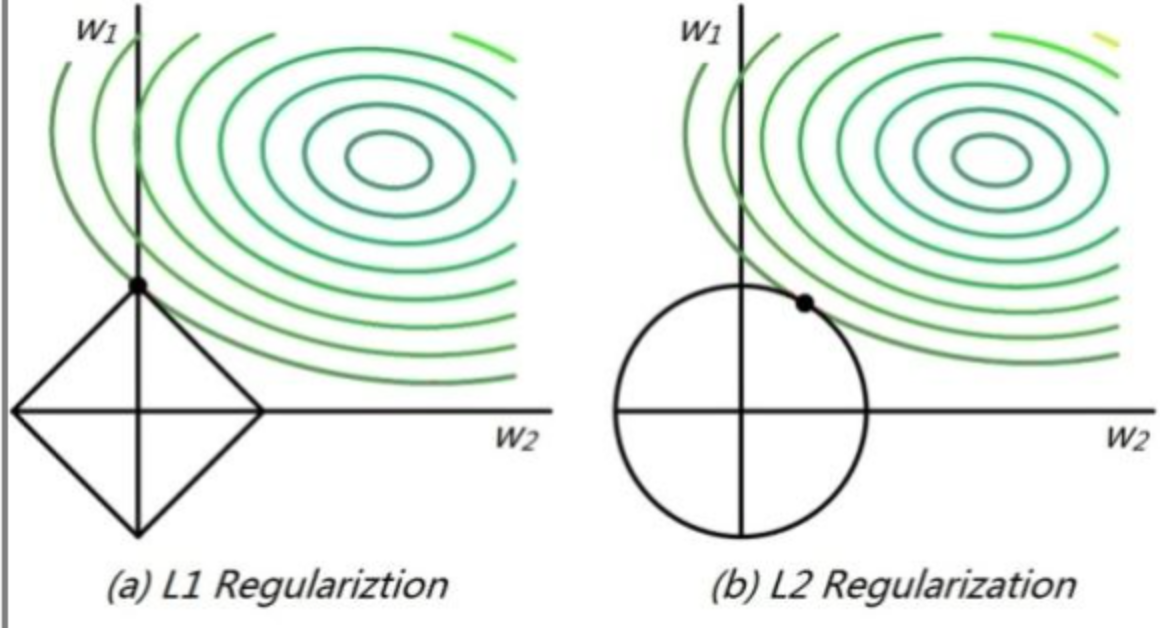
- 其中左圖表示L1,右圖表示L2。綠色代表的是loss的等高線, 在L1中的取值空間如左圖的菱形所示。在L2中的取值空間如右圖的圓形所示。從等高線和取值空間的交點可以看到L1更容易傾向一個權重偏大一個權重為0。L2更容易傾向權重都較小。