
插入排序和迭代歸併排序以及複雜度分析
引言: 演算法是電腦科學中的基礎,程式=演算法+資料結構,演算法描述了我們將如何來處理資料的過程。本文將介紹兩種演算法的實現以及其中一種演算法的複雜度分析過程。
1. 演算法介紹
歸併排序是利用歸併思想對數列進行排序,核心點是將陣列進行分組拆分,拆分到最小單元之時,即為有序;然後進行分組資料的歸併排序合併,從而達到排序的目的。
插入排序是將元素插入到某個有序陣列之中,並保持原有資料的有序性,以此類推來解決資料排序的問題。
2. 演算法實現
插入排序是在這裡的實現是從有序陣列的最後一個元素來進行比較和插入,當然這裡也可以從第一個元素來進行比較和插入操作。
歸併元素是基於2分法來進行分拆、排序歸併的。
程式碼如下:
在插入排序中, direction方向表示: 0為順序排序,1: 降序排序。import java.util.Arrays; public class SortWays { /** * direction: * * @param data * @param direction 0: ascendent, 1: descendent * @return */ public static int[] insertSort(int[] data, int direction) { if (data == null || data.length == 0) return new int[]{}; for (int j=1; j<data.length; j++) { int key = data[j]; int i = j -1; while ((i>=0)) { if ((data[i] > key) && (direction == 0)) { data[i+1] = data[i]; i--; //auto decrease } else if ((data[i]<key) &&(direction == 1)) { data[i+1] = data[i]; i--; //auto decrease } else { break; } } data[i+1] = key; } return data; } public static void mergeSort(int[] data, int startIndex, int endIndex) { if (startIndex < endIndex) { int splitIndex = (int)Math.floor((startIndex+endIndex)/2); mergeSort(data, startIndex, splitIndex); mergeSort(data, splitIndex+1, endIndex); merge(data, startIndex, splitIndex, endIndex); } } /** * merge method body. * * @param data * @param startIndex * @param splitIndex * @param endIndex */ private static void merge(int[] data, int startIndex, int splitIndex, int endIndex) { int[] tmp = new int[endIndex - startIndex+1]; //臨時區域 int i = startIndex; // first area index int j = splitIndex +1; //second area index int k = 0; // temporary area index while (i<= splitIndex && j <= endIndex) { //System.out.println("splitIndex/i/endIndx/j:" + splitIndex + "/" + i + "/" + endIndex + "/" + j); if (data[i] > data[j]) tmp[k++] = data[j++]; else tmp[k++] = data[i++]; } while (i<=splitIndex) { tmp[k++] = data[i++]; } while(j<=endIndex) { tmp[k++] = data[j++]; } for (int c=0; c<k; c++) data[startIndex+c] = tmp[c]; tmp = null; } public static void main(String[] args) { int[] rawdata = new int[]{7,2, 3, 5, 1, 8, 4, 6}; //int[] data = SortWays.insertSort(rawdata, 0); SortWays.mergeSort(rawdata, 0, rawdata.length-1); System.out.println("Array Data:" + Arrays.toString(rawdata)); } }
在歸併排序中,注意mergeSort的輸入引數中最後一個引數為最後一個元素的位置,而非陣列長度;比如這裡實際的位置為7, 而非長度8.
3. 迭代歸併排序的複雜度分析
關於插入排序的複雜度分析, 我們基於其虛擬碼實現來進行分析:

其執行的總時間為:
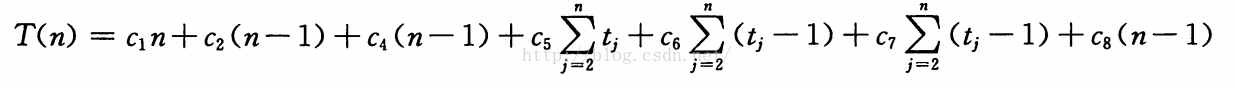
其在最壞情況下的總時間為:
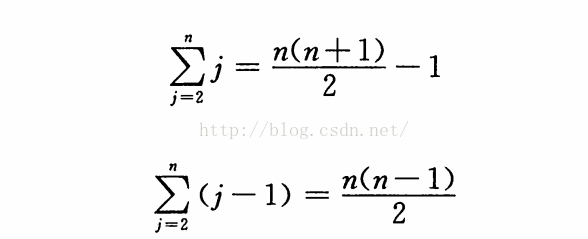
總時間為 N*N的正相關關係, 故其消耗時間為:
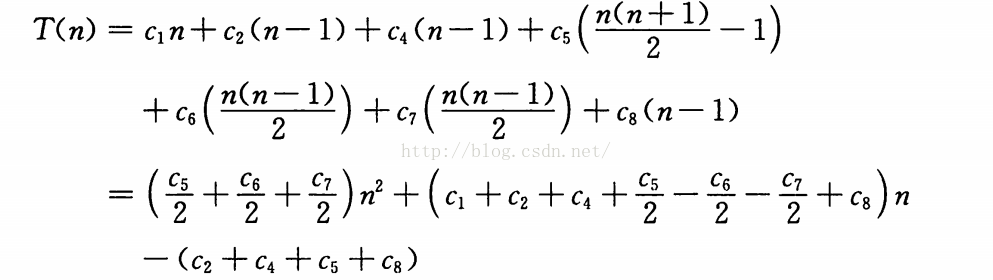
故這裡的插入演算法的複雜度為O(n*n),至於其他的n和常量都在複雜度的級別上進行忽略。
對於合併排序的演算法複雜度分析,遞迴演算法的時間複雜度公式為:
當n<<c,c為某個常量值之時,則問題規模足夠小,可以直接求出其解所需時間,為O(1). T(n) = O(1)
其他情況下,
T(n) = aT(n/b) + D(n)+C(n)
其中,a為分解的問題個數,T(n/b)為單個被分級的問題規模所需時間,二分法情況下為 a=b=2;但是大部分情況下,a並不等於b
D(n):將問題分解為子問題所需時間
C(n): 將子問題的解合併為原問題的解所需要的時間
對於歸併排序的演算法而言:
n = 1 ==> T(n) = O(1)= c [c為常量,固定時間]
n>1 => T(n)=2T(n/2) + O(n) = 2T(n/2) + cn
[c為常數, n為元素數量正相關的元素]
我們將遞迴演算法分解為以下圖中所示的層次關係:
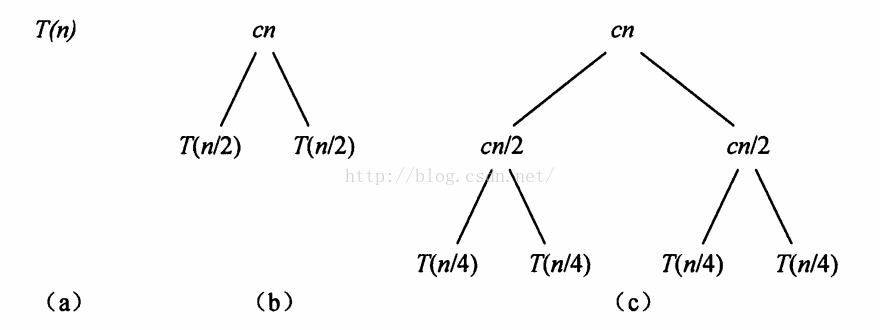
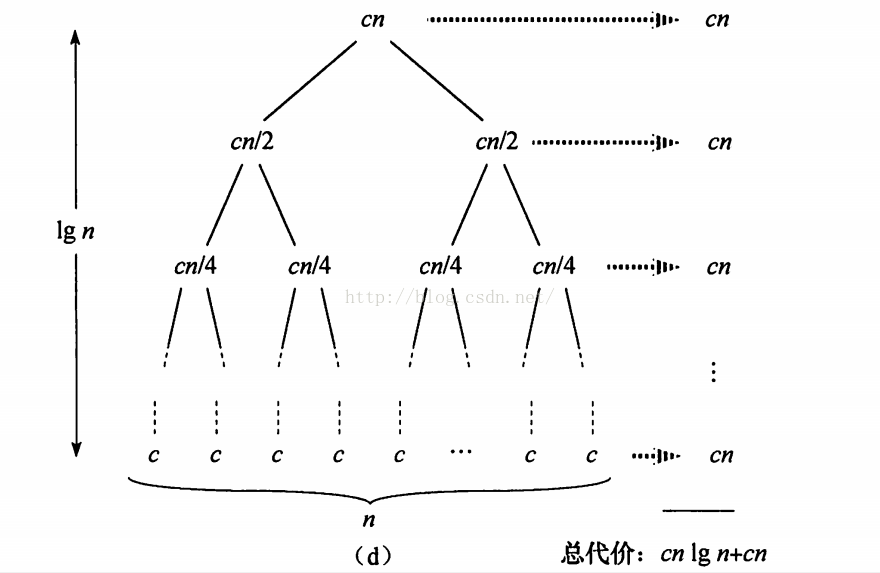
從上圖可知,整個遞迴樹的層次為lgn+1層,每層的時間消耗為cn,故整體的時間消耗為: cnlgn + cn = cn(lgn+1) ~~~ O(nlgn)
故迭代歸併的時間複雜度為 O(nlgn)
4.總結
對於各個演算法的複雜度分析一般會分為最壞情況,最好情況和平均情況,在這裡只是使用了最壞情況下的分析,這些資料方便我們瞭解各個演算法在不同情況下的資源和時間消耗,這裡並未涉及空間複雜度的討論,主要是由於資源空間消耗不大,故沒有討論。
5. 參考資料
- 歸併排序 http://www.cnblogs.com/skywang12345/p/3602369.html
- 插入排序 http://blog.csdn.net/cjf_iceking/article/details/7916194