
基於TextRank的中文摘要抽取演算法(一)
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms within a document (e.g., their relative proximity). It is not a single function, but actually a whole family of scoring functions, with slightly different components and parameters. One of the most prominent instantiations of the function is as follows.
BM25演算法,通常用來作搜尋相關性平分。一句話概況其主要思想:對Query進行語素解析,生成語素qi;然後,對於每個搜尋結果D,計算每個語素qi與D的相關性得分,最後,將qi相對於D的相關性得分進行加權求和,從而得到Query與D的相關性得分。
BM25演算法的一般性公式如下:
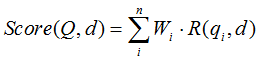
其中,Q表示Query,qi表示Q解析之後的一個語素(對中文而言,我們可以把對Query的分詞作為語素分析,每個詞看成語素qi。);d表示一個搜尋結果文件;Wi表示語素qi的權重;R(qi,d)表示語素qi與文件d的相關性得分。
下面我們來看如何定義Wi。判斷一個詞與一個文件的相關性的權重,方法有多種,較常用的是IDF。這裡以IDF為例,公式如下:
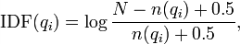
其中,N為索引中的全部文件數,n(qi)為包含了qi的文件數。
根據IDF的定義可以看出,對於給定的文件集合,包含了qi的文件數越多,qi的權重則越低。也就是說,當很多文件都包含了qi時,qi的區分度就不高,因此使用qi來判斷相關性時的重要度就較低。
我們再來看語素qi與文件d的相關性得分R(qi,d)。首先來看BM25中相關性得分的一般形式:
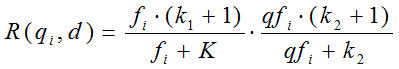
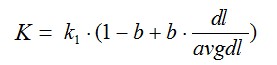
其中,k1,k2,b為調節因子,通常根據經驗設定,一般k1=2,b=0.75;fi為qi在d中的出現頻率,qfi為qi在Query中的出現頻率。dl為文件d的長度,avgdl為所有文件的平均長度。由於絕大部分情況下,qi在Query中只會出現一次,即qfi=1,因此公式可以簡化為:
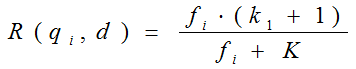
從K的定義中可以看到,引數b的作用是調整文件長度對相關性影響的大小。b越大,文件長度的對相關性得分的影響越大,反之越小。而文件的相對長度越長,K值將越大,則相關性得分會越小。這可以理解為,當文件較長時,包含qi的機會越大,因此,同等fi的情況下,長文件與qi的相關性應該比短文件與qi的相關性弱。
綜上,BM25演算法的相關性得分公式可總結為:
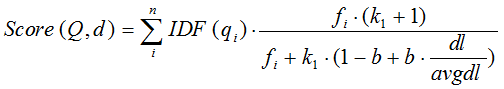
從BM25的公式可以看到,通過使用不同的語素分析方法、語素權重判定方法,以及語素與文件的相關性判定方法,我們可以衍生出不同的搜尋相關性得分計算方法,這就為我們設計演算法提供了較大的靈活性。
基於此演算法算例與應用場景,可以用來在文字摘要應用進行語素與句子的相似度。在一篇document當中,該document看成是一個sentences的集合,而中文文字摘要本質上是按文字中對句子的重要性權值進行排名,取權值最高的若干句子作為文章的摘要句子,按原文的語句排列順序輸出,輸出的結果即為文章的摘要內容。目前有許多演算法可以用來進行中文摘要的抽取,這裡先介紹基於TextRank打分思想的中文摘要抽取演算法:
TextRank的打分思想依然是從PageRank的迭代思想衍生過來的,如下公式所示:

等式左邊表示一個句子的權重(WS是weight_sum的縮寫),右側的求和表示每個相鄰句子對本句子的貢獻程度。與提取關鍵字的時候不同,一般認為全部句子都是相鄰的,不再提取視窗。
求和的分母Wji表示兩個句子的相似程度,分母又是一個weight_sum,而WS(Vj)代表上次迭代j的權重。整個公式是一個迭代的過程。相似程度Wji的計算,推薦使用BM25演算法。BM25演算法,通常用來作搜尋相關性平分。一句話概況其主要思想:對Query進行語素解析,生成語素qi;然後,對於每個搜尋結果D,計算每個語素qi與D的相關性得分,最後,將qi相對於D的相關性得分進行加權求和,從而得到Query與D的相關性得分。相關程式碼實現:
//bm25演算法:計算兩個句子之間的相關性,對當前語句進行打分
public double sim(List<String> sentence, int index)
{
double score = 0;
for (String word : sentence)
{
if (!f[index].containsKey(word)) continue; //不是共有的詞,則看成對句子之間的相似度沒有任何貢獻,直接過濾掉
int d = docs.get(index).size(); //該句子的長度
Integer wf = f[index].get(word); //獲取word在該句子中的詞頻
score += (idf.get(word) * wf * (k1 + 1) / (wf + k1 * (1 - b + b * d / avgdl)));
}
return score;
}
//用於計算當前語句與文字中所有語句的相似性,從而求得該語句的分數
public double[] simAll(List<String> sentence)
{
double[] scores = new double[D];
for (int i = 0; i < D; ++i)
{
scores[i] = sim(sentence, i); //句子與其他句子都看成是相鄰的
}
return scores;
}