
基於依存關係的空間關係抽取演算法
0.引入
空間關係是指存在於實體之間的具有空間特徵的關係,如方位關係、距離關係、拓撲關係、層次關係等。空間關係在自然語言描述中一般具有三個部分或者兩個層次。三個部分是從認知學的角度出發的將其分為射體、界標和方位詞,其中:
- 射體是空間關係中的主體成分。
- 方位詞是用來描述實體之間的空間方向和位置關係的,通常與其前面的名詞構成句子中的處所格。
- 界標則為射體的方位提供了參照物依據。
例如S1:杯子在桌子上。S1 中包含空間表示式(在,上,桌子)。
則杯子為射體,桌子為界標,上為方位詞。
獲取空間關係就需要找出句子中的空間表示式。首先要對原始語料進行預處理。然後抽取其中的空間關係。
1.語料預處理
1.1. 獲得句子分詞後的依存關係
基於哈工大的自然語言處理技術,使用它的API對句子進行分詞,並得到它的依存關係。
使用者通過指定API引數來獲取對應的結果,語言云服務的API引數集連結如下:
http://www.ltp-cloud.com/document/
在語言云中,所有的API訪問都是通過HTTP請求的方式。並且需要從api.ltp-cloud.com域進行訪問。語言云只支援GET和POST方式的HTTP請求。使用者通過在HTTP請求中指定引數來獲取對應的結果。
舉個例子,對“房頂上落著一隻小鳥”這句話做依存句法分析。
這句話的依存關係的句子檢視如下:
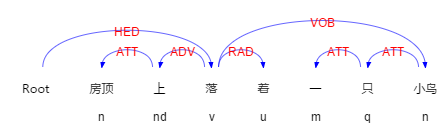
圖1-1例句的依存關係
返回xml格式的結果。GET請求及返回結果示例:
GET http ://api.ltp-cloud.com/analysis/?api_key=U1H0S1Z1CkcUtrLouJvyHVNSOWkY9ycmAVahcduW&text=房頂上落著一隻小鳥&pattern=all&format=xml

圖1-2 例句的xml標準結果
- 這句話的XML標準結果如下:結點標籤分別為 xml4nlp, note, doc, para, sent, word,arg 共七種結點標籤:
1、xml4nlp 為根結點,無任何屬性值;
2、note 為標記結點,具有的屬性分別為:sent, word, pos, ne, parser, srl;分別代表分句,分詞,詞性標註,命名實體識別,依存句法分析,詞義消歧,語義角色標註;值為”n”,表明未做,值為”y”則表示完成,如pos=”y”,表示已經完成了詞性標註;
3、doc 為篇章結點,以段落為單位包含文字內容;無任何屬性值;
4、para 為段落結點,需含id 屬性,其值從0 開始;
5、sent 為句子結點,需含屬性為id,cont;id 為段落中句子序號,其值從0 開始;cont 為句子內容;
6、word 為分詞結點,需含屬性為id, cont;id 為句子中的詞的序號,其值從0 開始,cont為分詞內容;可選屬性為 pos, ne, parent, relate , semparent,semrelate;pos 的內容為詞性標註內容;ne 為命名實體內容;parent 與 relate 成對出現,parent 為依存句法分析的父親結點id 號,relate 為相對應的關係;semparent 與 semrelate 成對出現,semparent 為語義依存分析的父親結點id 號,semrelate 為相對應的關係;
7、arg 為語義角色資訊結點,任何一個謂詞都會帶有若干個該結點;其屬性為id, type, beg,end;id 為序號,從0 開始;type 代表角色名稱;beg 為開始的詞序號,end 為結束的序號;
各結點及屬性的邏輯關係說明如下:
- 1、各結點層次關係可以從圖中清楚獲得,凡帶有id 屬性的結點是可以包含多個;
2、如果sent=”n”即未完成分句,則不應包含sent 及其下結點;
3、如果sent=”y” word=”n”即完成分句,未完成分詞,則不應包含word 及其下結點;
4、其它情況均是在sent=”y” word=”y”的情況下:
- (1)如果 pos=”y” 則分詞結點中必須包含pos 屬性;
(2)如果 ne=”y” 則分詞結點中必須包含ne 屬性;
(3)如果 parser=”y” 則分詞結點中必須包含parent 及relate 屬性;
(4)如果 semparser=”y” 則分詞結點中必須包含semparent 及semrelate 屬性;
(5)如果 srl=”y” 則凡是謂詞(predicate)的分詞會包含若干個arg 結點;
在XML格式的分析中,使用者可以通過指定引數pattern=ws | pos | ner | dp | sdp | srl | all 來指名分析任務並獲取對應的XML結果。
1.2. 把依存關係儲存為XML檔案
將依存關係以XML格式的字串的形式把儲存到XML檔案。
例“房頂上落著一隻小鳥”這句話的依存關係的XML格式如圖所示:

圖 1-3 例句依存關係的XML
1.3解析XML檔案獲得每個詞的屬性
使用dom4j解析XML檔案,獲得節點下各屬性值(如上圖紅框內所示)。建立一個實體類Word,成員變數對應著XML檔案中節點的各屬性。把解析得到的每個詞的屬性值作為Word例項儲存到一個List裡面。

圖 1-4 節點屬性
2.空間關係三元組抽取
通過語料預處理得到的一個短句中所有詞的詞性、依存關係和句子的句法結構等資訊,根據這些資訊再加上我們的認知常識來識別出空間關係三元組。
先根據一個短句中的方位詞個數來確定短句中至少有多少個三元組,之後對於每一個方位詞,去確定其界標和射體,如果存在多個射體,那麼複製方位詞和界標,增添三元組的數量。
例:“小明和奧巴馬在屋子後面的橋上釣魚。”
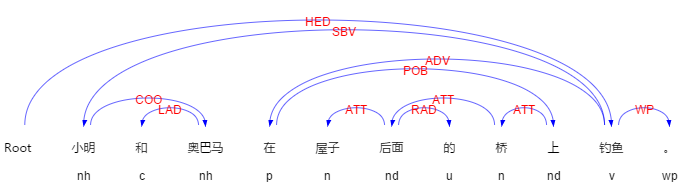
圖2- 1例句的句法分析和詞性標註
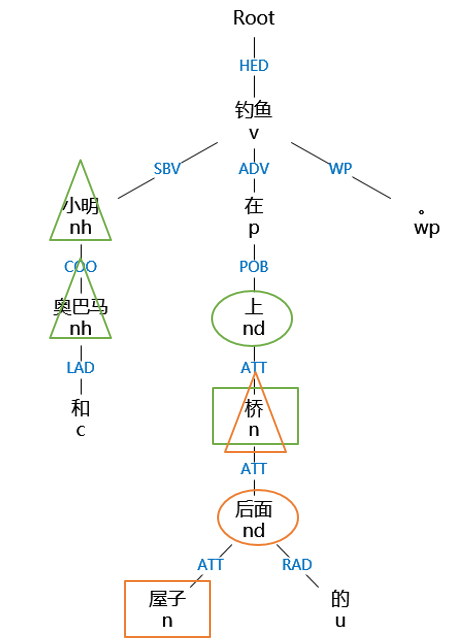
圖2-2 例句的句法分析樹
如上圖,例句中識別出的方位詞為“後面”和“上”,方位詞的個數為2,則可確定至少有兩個三元組,根據依存關係為ATT(定中關係)的方位詞的子節點,確定界標分別為“屋子”和“橋”,之後再根據方位詞來找到三元組中的射體(具體的方法下面做介紹),因為有一個三元組的射體為“小明”和“奧巴馬”,所以要將“小明”的界標和方位詞複製給“奧巴馬”,然後將新的三元組增添到結果三元組列表中。
2.1方位詞的識別
通過遍歷一個短句中所有的詞,找出其中詞性為“nd”(direction noun)的詞來作為方位詞。
哈工大的語言技術平臺的分詞系統中有一百餘種固定的方位詞,比如“東北面”、“前後”等,所以短句中方位詞的識別比較精確,不會存在方位詞分開識別的情況。

圖2-3方位詞識別
2.2界標的識別
將2.1中識別出的方位詞新增到相應的三元組中,對於當前的每一個三元組,根據其中的方位詞去識別界標,經過大量考察例句,在句法分析樹中,界標是方位詞的子節點,界標的依存關係是ATT(定中關係),根據這樣的規則,識別出相應三元組中的界標。
例“房頂上落著一隻小鳥”這句話的依存關係如圖 3-2 所示:
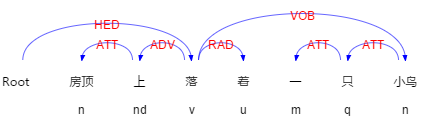
圖 2-4 依存關係和詞性標註
例“他站在房子前”這句話的依存關係如圖 3-3 所示:
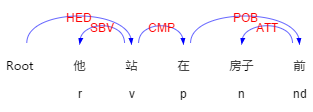
圖 2-5 依存關係和詞性標註
當依存關係ATT中方位詞的直接依存物件不是界標的時候,比如“大象的背上有一隻螞蟻”
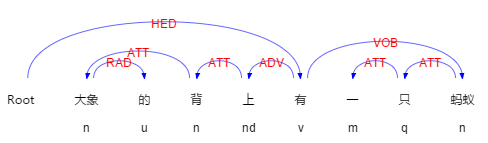
圖2-6依存關係和詞性標註
在上圖可以看到依存關係ATT(上—>背)、(背—>大象),此時方位詞“上”的直接依存物件並不是界標,但是“背”的直接依存物件是界標。,從它的義原得知“背”是部件,因此不能作為界標,確定大象是界標。
界標識別演算法如下:
- ① 確定方位詞子節點的依存關係 ATT。
② 在方位詞依存關係 ATT 中得到方位詞的直接依存物件 X1。
③ 查詢 X1 是否為部件,如果不是轉(4),否則轉(5)
④ 確定X1為界標。結束。
⑤ 得到X1的依存關係ATT,從依存關係ATT的到X1的直接依存物件X2,更新 X1的值為X2。轉③。
2.3射體識別
2.3.1簡單射體識別
根據短句中方位詞的重要性來對方位詞進行分類,與句法分析樹的根節點直接相關的方位詞可以視為主要方位詞;相對的,遠離根節點且方位詞的依存關係為ATT的方位詞可以視為次要方位詞。
如下圖,例子“小明和奧巴馬在屋子後面的橋上釣魚。”中,三元組為(小明,橋,上)、(奧巴馬,橋,上)、(橋,屋子,後面),其中“上”是主要方位詞,“後面”是次要方位詞。下面就根據方位詞的分類來對相應的射體進行識別。
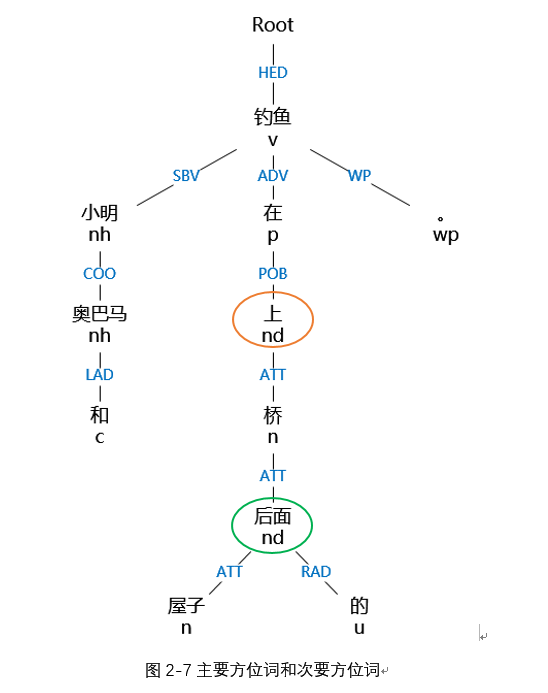
(1)方位詞是主要方位詞。
當方位詞是主要方位詞的時候,父節點的依存關係是HED(核心關係)或者父節點的父節點(或者更多)的依存關係為HED,如圖3-9中的例子,“上”的父節點的父節點的依存關係是HED。
從方位詞開始一層一層地向上獲取節點,直到獲取到依存關係為HED的節點,然後遍歷找出該節點子節點中詞性為名詞“n”(或包含“n”)和代詞“r”的節點。在上面的例子中就可以找到上的射體“小明”。
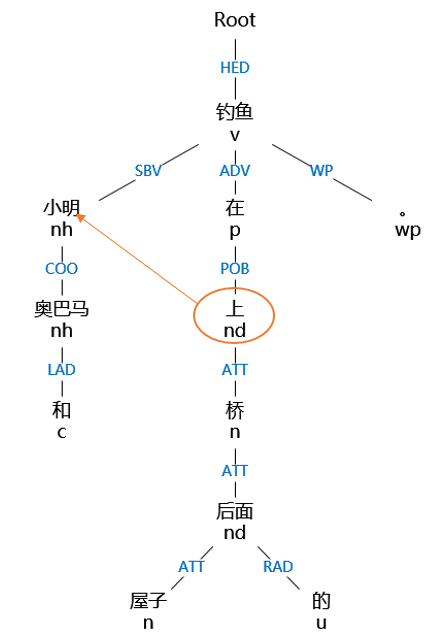
圖2-8句法分析樹
例“屋子前的桌子上有一個水杯”其中主要方位詞“上”的射體是“水杯”。這句話的依存關係和句法分析樹如圖 2-8、2-9 所示:
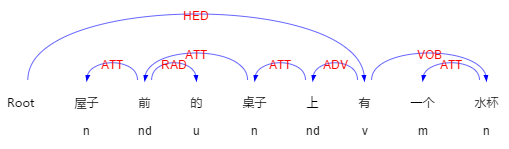
2-9依存關係
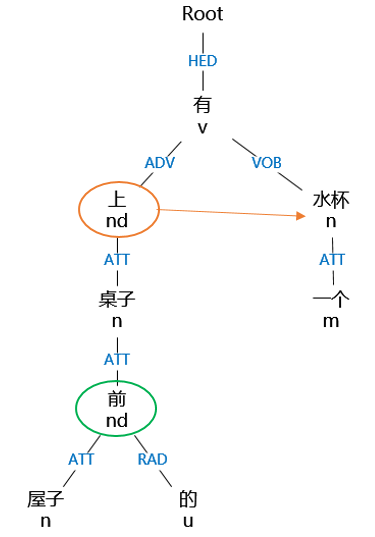
圖2-10句法分析樹
(2) 方位詞是次要方位詞。
當方位詞是次要方位詞的時候,方位詞的依存關係是ATT(定中關係),且直接依存的物件是名詞“n”(或者包含“n”的詞性,比如“小明”“nh”)或者代詞“r”時,可以判定這個詞就是次要方位詞的射體。
例子“小明和奧巴馬在屋子後面的橋上釣魚。”中,次要方位詞“後面”的依存關係為ATT,直接依存的物件是“橋”詞性“n”,符合上面的要求,所以“橋”就是“後面”的射體。

簡單射體識別演算法如下:
- ① 判斷方位詞是否為次要方位詞(依存關係是否為ATT),如果是,轉②,否則轉③。
② 驗證父節點是否為名詞或代詞,如果是,那麼確定射體,否則返回空值。
③ 將方位詞作為當前詞,判斷當前詞的父節點的依存關係是否為HED,如果不是,將當前詞的父節點覆蓋當前詞,再作判斷,直到滿足當前詞的父節點的依存關係是HED的情況。
④ 遍歷句法樹,抽取父節點與當前詞的父節點相同的詞,並驗證其詞性是否為名詞或者代詞,如果是,那麼確定射體,否則,返回空值。
2.3.2複雜射體識別
當一個短句中存在多個並列的射體時,如例子“小明和奧巴馬在屋子後面的橋上釣魚。”通過2.3.1的方法我們只能識別出兩個三元組(小明,橋,上),(橋,屋子,後面),對於跟“小明”並列的射體“奧巴馬”並沒有識別出來,所以就要在簡單射體識別之後對並列的射體做處理,複製相應的界標和方位詞,增添到結果三元組的列表中去。

在上圖中我們可以通過遍歷句法樹來抽取父節點為已確定射體,依存關係為COO的節點來作為新增三元組的射體,在複製父節點射體的三元組中的界標和方位詞,增添到結果三元組列表中去。
複雜射體識別演算法如下:
- ① 簡單射體識別。
② 遍歷句法樹,抽取父節點是當前處理三元組中的射體的節點,驗證其依存關係是否為“COO”。
③ 複製當前處理三元組的界標和方位詞到新的三元組,將該節點作為新的三元組中射體,並將新的三元組新增到結果三元組列表中。
④ 返回結果三元組
相關推薦
基於TextRank的中文摘要抽取演算法(一)
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless
基於依存關係的空間關係抽取演算法
0.引入 空間關係是指存在於實體之間的具有空間特徵的關係,如方位關係、距離關係、拓撲關係、層次關係等。空間關係在自然語言描述中一般具有三個部分或者兩個層次。三個部分是從認知學的角度出發的將其分為射體、界標和方位詞,其中: 射體是空間關係中的主體成分。 方位
基於依存句法分析的實體關係抽取
from:https://mp.weixin.qq.com/s/Q-WMYSTjGGxIMGNq-wfpRg 這一段時間一直在做知識圖譜,卡在實體關係抽取這裡幾個月了,在github上面看到有人使用卷積神經網路訓練模型進行抽取,自己也嘗試了一下,但是一直苦於沒有像樣資料去訓練,而標註訓練集又太
清華大學馮珺:基於強化學習的關係抽取和文字分類 | 實錄·PhD Talk
本文為 11 月 22 日,清華大學計算機系——馮珺博士在第 18 期 PhD Talk 中的直播分享實錄。 隨著強化學習在機器人和遊戲 AI 等領域的成功,該方法也引起了越來越多的關注。本期 P
JTS Geometry空間關係的判斷
幾何資訊和拓撲關係是地理資訊系統中描述地理要素的空間位置和空間關係的不可缺少的基本資訊。其中幾何資訊主要涉及幾何目標的座標位置、方向、角度、距離和麵積等資訊,它通常用解析幾何的方法來分析。而空間關係資訊主要涉及幾何關係的“相連”、“相鄰”、“包含”等資訊,它通常用拓撲關係或拓撲結構的方法來分析。拓撲
使用者態核心態及使用者空間核心空間關係
1 使用者態與核心態 當一個任務(程序)執行系統呼叫而陷入核心程式碼中執行時,我們就稱程序處於核心執行態(或簡稱為核心態)。此時處理器處於特權級最高的(0級)核心程式碼中執行。當程序處於核心態時,執行的核心程式碼會使用當前程序的核心棧。每個程序都有自己的核心棧。 當程序在執行
基於依存句法與語義角色標註的事件抽取專案
EventTriplesExtraction 專案地址:https://github.com/liuhuanyong/EventTriplesExtraction EventTriplesExtraction based on dependency parser
學習筆記《Dynamic Routing Between Capsules》-(“膠囊”網路之區域性空間關係)
喜歡才能持久,熱愛才會盡心! 0 前言 昨天的面試官講了利用自動駕駛鐳射雷達資料探測路上行人、車輛問題的區域性空間關係的見解,提到了Vector向量多方位,多角度問題,我感覺和Capsule裡的Ve
oracle 使用者與表空間關係
oracle使用者與表空間關係 使用者=商家 表=商品 表空間=倉庫 1. 1個商家能有很多商品,1個商品只能屬於一個商家 2. 1個商品可以放到倉庫A,也可以放到倉庫B,但不能同時放入A和B 3. 倉庫不屬於任何商家 4. 商家都有一個預設的倉庫,如果不指定具體倉庫,商品則放到預設的倉庫中 o
PostGIS教程九:空間關係
目錄 一、ST_Equals 二、ST_Intersects、ST_Disjoint、ST_Crosses和ST_Overlaps 三、ST_Touches 四、ST_Within和ST_Contains 五、ST_Distance和ST_DWithin 六
Arcmap 空間連線,在通過麵包含面的空間關係做屬性關聯的時候,發生關聯冗餘的問題。
處理過程: (1)用 空間關聯 工具實現 面與面的 空間和屬性關聯。 (2) 問題描述: 一個子面要素對應多個父面要素,出現數據冗餘。 問題根源: 解決辦法: 取子面要素的 中心點,在用中心點和 父面要素做空間關聯,生成關聯圖層, 最後用關聯圖
neo4j cypher基於節點label、關係type的與或查詢
希望能實現類似match (a:test1 & :test2),match (a:test1 | :test2)的效果 1、節點的label的與查詢 MATCH (a:test1:test2) return a limit 25很直接,沒有什麼符號連線2、節點的l
李飛飛團隊CVPR論文:讓AI識別語義空間關係(附論文、實現程式碼)
本文經AI新媒體量子位(公眾號ID:qbitai )授權轉載,轉載請聯絡出處。本文共1000字,
基於行塊分佈函式的網頁正文抽取演算法程式碼實現
最近在在做一個與資訊相關的APP,資訊是通過爬取獲得,但是獲取只有簡單的資訊,正文沒有獲取。所以在顯示的時候很麻煩,一個<a>標籤鏈到到別人的網頁,滿屏的廣告 ,還有各種彈窗,雖然頁面確實做得很漂亮,但是不得不放棄這種簡單的方式了,所以接下來自己動手了
基於深度學習的目標檢測演算法綜述(一)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40047760 目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標檢測演算法也從基於手工特徵的傳統演算法轉向了基於深度神經網路的檢測技
基於深度學習的目標檢測演算法綜述(三)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40102001 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經
基於深度學習的目標檢測演算法綜述(二)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40020809 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經
學習筆記之——基於深度學習的目標檢測演算法
國慶假期閒來無事~又正好打算入門基於深度學習的視覺檢測領域,就利用這個時間來寫一份學習的博文~本博文主要是本人的學習筆記與調研報告(不涉及商業用途),博文的部分來自我團隊的幾位成員的調研報告(由於隱私關係,不公告他們的名字了哈~),同時結合
基於分解的多目標進化演算法(MOEA/D)
目錄 1、MOEA/D的特點 2、 MOEA/D的分解策略 3、MOEA/D的流程 基於分解的多目標進化演算法(Multi-objectiveEvolutionary Algorithm Based on Decomposition, MOEA/D)將多目標優化問題被轉
基於使用者的電視節目推薦演算法例項
# -*- coding: utf-8 -*- """ Created on Thu Nov 1 10:29:52 2018 @author: AZ """ # 程式碼說明: # 基於使用者的協同過濾演算法的具體實現 import math import numpy as np import