SPI匯流排介紹和verilog實現
阿新 • • 發佈:2019-01-11
這篇文章講SPI匯流排,SPI是serial peripheral interface 的縮寫,即序列外圍裝置介面。該介面是摩托羅拉公司提出的全雙工同步通訊的介面,該介面只有四根訊號線,在晶片的管腳上只佔用4根線,節約了晶片的管腳。
這四根訊號信如下:
1、MOSI:主器件資料輸出,從器件資料輸入。
2、MISO:主器件資料輸入,從器件資料輸出。
3、SCLK:時鐘線,有主器件控制。
4、CS:從器件的片選線,由主器件控制。
在點對點的通訊當中:無須定址工作,使用該介面實現全雙工通訊,高效簡單,一個主器件可以連線多個從裝置,每個從裝置有獨立的片選訊號。不過該介面有一個缺點,就是沒有應答機制。
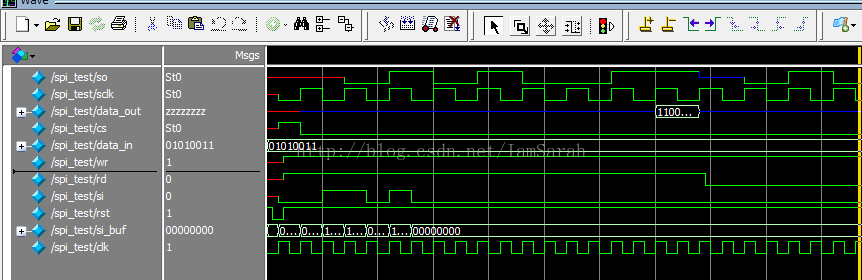
該介面的工作機制:主裝置啟動,連線多個從裝置,在sdo端輸出,si端輸入資料,均在sclk的上升沿傳輸資料,則經過8/16次時鐘的改變,就能夠完成8/16 bit的資料傳輸。
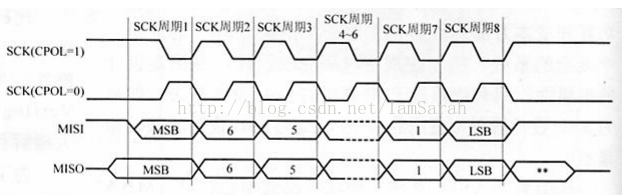
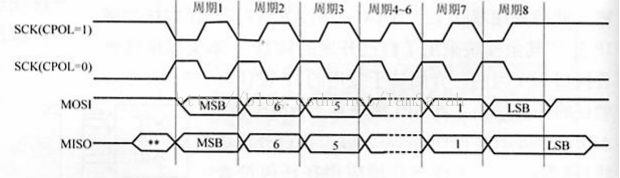
一般情況下,對有該介面的時鐘會有兩方面的設定:一方面是時鐘極性,主要是用來規定空閒狀態下sclk的值,0代表空閒狀態下是低電平,1代表空閒狀態下是高電平;另一方面是時鐘相位的設定,主要是規定資料是在第一個跳變沿被取樣還是第二個跳變沿被取樣,0是代表第一個跳變沿,1是代表第二個跳變沿。下面兩幅圖給出不同相位下,不同極性的傳輸效果:
相位為0:
相位為1:
以上就是SPI介面的工作原理,下面給出其verilog實現,這裡主器件用讀命令和寫命令來控制資料的輸入和輸出,並且對於一個位元組的資料讀和寫分別用一個任務實現,如下:
module spi(clk,rd,wr,rst,data_in,si,so,sclk,cs,data_out);
parameter bit7=4'd0,bit6=4'd1,bit5=4'd2,bit4=4'd3,bit3=4'd4,bit2=4'd5,bit1=4'd6,bit0=4'd7,bit_end=4'd8;
parameter bit70=4'd0,bit60=4'd1,bit50=4'd2,bit40=4'd3,bit30=4'd4,bit20=4'd5,bit10=4'd6,bit00=4'd7,bit_end0=4'd8;
parameter size=8;
input clk,rst;
input wr,rd;//讀寫命令
input si;//spi資料輸入端
input [size-1:0]data_in;//待發送的資料
output[size-1:0]data_out;//待接收的資料
output sclk;//spi中的時鐘
output so;//spi的傳送端
output cs;//片選訊號
wire [size-1:0]data_out;
reg [size-1:0]dout_buf;
reg FF;
reg sclk;
reg so;
reg cs;
reg [3:0]send_state;//傳送狀態暫存器
reg [3:0]receive_state;//接收狀態暫存器
`timescale 1ns/1ns
`define half_period 10
module spi_test;
parameter size=8;
wire so;
wire sclk;
wire [size-1:0]data_out;
wire cs;
reg [size-1:0]data_in;
reg wr,rd;
reg si;
reg rst;
reg [size-1:0]si_buf;
reg clk;
always#(`half_period) clk=~clk;
initial
begin
clk=0;
rst=1;
si_buf=8'b1001_1010;
data_in=8'b0101_0011;
#5
rst=0;
#10
rst=1;
wr=1;
rd=1;
#380 rd=0;
#1000 $stop;
end
[email protected](posedge clk)
begin
si_buf=si_buf<<1;
si<=si_buf[7];
end
spi m(clk,rd,wr,rst,data_in,si,so,sclk,cs,data_out);
endmodule