
正則化方法之DropBlock
論文:
DropBlock: A regularization method for convolutional networks
Github:
https://github.com/miguelvr/dropblock
https://github.com/DHZS/tf-dropblock
論文主要提出了一種針對卷積層的正則化方法DropBlock,最終在ImageNet分類任務上,使用Resnet-50結構,將精度提升1.6%個點,在COCO檢測任務上,精度提升1.6%個點。

(a)原始輸入影象
(b)綠色部分表示啟用的特徵單元,b圖表示了隨機dropout啟用單元,但是這樣dropout後,網路還會從drouout掉的啟用單元附近學習到同樣的資訊
(c)綠色部分表示啟用的特徵單元,c圖表示本文的DropBlock,通過dropout掉一部分相鄰的整片的區域(比如頭和腳),網路就會去注重學習狗的別的部位的特徵,來實現正確分類,從而表現出更好的泛化。
DropBlock 模組:
DropBlock 模組主要有2個引數,block_size,γ。
block_size:表示dropout的方塊的大小(長,寬),當block_size=1,DropBlock 退化為傳統的dropout,正常可以取3,5,7
γ:表示drop過程中的概率,也就是伯努利函式的概率

首先,保證DropBlock drop的元素個數和傳統dropout drop的元素個數相等。
那麼,傳統的dropout drop的元素個數為drop概率乘以一共的元素個數,即(1-keep_prob)*(feat_size*feat_size)
DropBlock drop的元素個數也是drop概率乘以一共的元素個數,
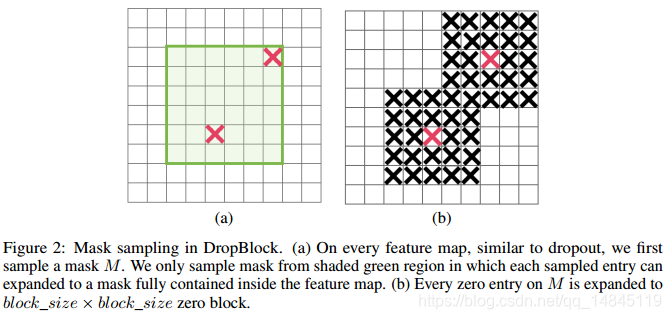
這裡在實現中,為了保證drop的block不會超出原始影象,需要先設定一個drop的有效區域,如下圖(a)中綠色的區域,也就是原始的圖減去block,即(feat_size-block_size+1)。
這裡的概率γ為伯努利函式的概率,而這個概率只表示了隨機drop的中間點的概率,如下圖(a)中紅色的×,實際需要的是要drop掉X周圍的block_size大小的區域,也就是一個X對應一個block_size大小的區域(假設不相互重疊)。
所以,DropBlock 的概率即γ*(block_size*block_size),有效的區域面積為(feat_size-block_size+1)*(feat_size-block_size+1),最終得到drop掉的元素數目為γ*(block_size*block_size)*(feat_size-block_size+1)*(feat_size-block_size+1)
最後,dropout==DropBlock ,即讓(1-keep_prob)*(feat_size*feat_size)=γ*(block_size*block_size)*(feat_size-block_size+1)*(feat_size-block_size+1)
這樣就會得到上面最終的伯努利概率γ。
在實驗過程中,使用固定的keep_prob值的效果不如使用線性下降的keep_prob值。
實驗中keep_prob值從1.0線性下降為0.75。
整體流程:

(1)輸入特徵層A,block_size,γ,模式(訓練,測試)
(2,3,4)如果是測試,直接返回特徵層A
(5)根據輸入的概率γ,使用伯努利函式對生成的隨機數mask矩陣進行drop,最終該步驟得到的mask只有0,1值。如上圖中(a)。
伯努利概率分佈為0-1分佈,或者兩點分佈,公式如下
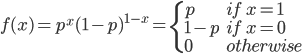
(6)對上一步得到的mask進行max pooling操作(stride=1,kernel_size=block_size),得到最終需要使用的mask。如上圖中(b)。
(7)輸入矩陣和Mask矩陣相乘,得到輸出矩陣
(8)將上一步的輸出矩陣進行歸一化操作,保證做DropBlock 之前和做DropBlock 之後,該層都具體相同的均值,方差。
哪一層該使用DropBlock:

Keep_prob值的選擇(a圖):
Drouout:0.7取得最優值
SpatialDropout:0.9取得最優值
DropBlock:0.9取得最優值
使用線性下降的方式(scheduling)來使用Keep_prob,可以獲得更高的驗證準確性。(b圖)

Block_size=7時,獲得最高驗證集準確性
對Keep_prob值進行線性下降方式(scheduling)可以獲得更好效果
Resnet-50的第3,4個block加Drouout比只在第4個block加Drouout更有效
在Resnet-50的卷積層和skip connection都使用Drouout效果更好
實驗分析:

訓練時使用block_size=7,keep_prob=0.9,測試時使用block_size=7,keep_prob=1.0,可以獲得更好的效果。這點和傳統的dropout一樣。

第一行為原始的圖片,第二行為未使用DropBlock,第三行為block_size=1,第四行為block_size=7。可以看出
(1)使用DropBlock比不使用DropBlock具有更大的熱量圖
(2)DropBlock的block_size越大,熱量圖的啟用部分越多
實驗結果:
ImageNet 影象分類:

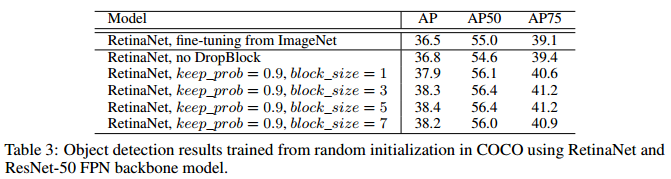
COCO檢測任務:
PASCAL VOC 分割任務:

自己的復現:
import tensorflow as tf
def compute_gamma(keep_prob,feat_size_h,feat_size_w,block_size_h,block_size_w):
feat_size_h=tf.to_float(feat_size_h)
feat_size_w=tf.to_float(feat_size_w)
gamma=(1-keep_prob)*(feat_size_h*feat_size_w)/(block_size_h*block_size_w)/((feat_size_h-block_size_h+1)*(feat_size_w-block_size_w+1))
return gamma
def compute_keep_prob(now_step=0,start_value=1.0,stop_value=0.75,nr_steps=100000,trainable=False):
prob_values = tf.linspace(start=start_value, stop=stop_value, num=nr_steps)
prob=tf.where(tf.less(now_step,nr_steps),prob_values[now_step],prob_values[-1])
keep_prob=tf.where(tf.equal(trainable,False),start_value,prob)
return keep_prob
def bernoulli(shape,gamma=0):
mask=tf.cast(tf.random_uniform(shape, minval=0, maxval=1, dtype=tf.float32)<gamma,tf.float32)
return mask
def compute_block_mask(shape,padding,gamma,block_size_shape):
mask=bernoulli(shape,gamma)
mask = tf.pad(mask, padding,"CONSTANT")
mask = tf.nn.max_pool(mask, [1,block_size_shape[0],block_size_shape[1], 1], [1, 1, 1, 1], 'SAME')
mask = 1 - mask
return mask
def DropBlock(inputs,keep_prob,block_size_shape,feat_size_shape):
#keep_prob:keep ratio,float32
#block_size_shape:[height,width]
#feat_size_shape:[batch,height,width,channel]
gamma=compute_gamma(keep_prob,feat_size_shape[1],feat_size_shape[2],block_size_shape[0],block_size_shape[1])
shape=[feat_size_shape[0],feat_size_shape[1]-block_size_shape[0]+1,feat_size_shape[2]-block_size_shape[1]+1,feat_size_shape[3]]
bottom = (block_size_shape[0]-1) // 2
right = (block_size_shape[1]-1) // 2
top = (block_size_shape[0]-1) // 2
left = (block_size_shape[1]-1) // 2
padding = [[0, 0], [top, bottom], [left, right], [0, 0]]
mask=compute_block_mask(shape,padding,gamma,block_size_shape)
normalize_mask=mask*tf.to_float(tf.size(mask)) / tf.reduce_sum(mask)
outputs=inputs*normalize_mask
return outputs呼叫:
......
pool=*****
now_step=tf.Variable(0,trainable=False,name="now_step")
keep_prob=compute_keep_prob(now_step=now_step,trainable=True)
dropblock=DropBlock(pool,keep_prob,[3,3],tf.shape(pool))
......訓練中只需要將每一步step 傳遞(feed)給now_step即可。