
大數因數分解Pollard_rho 演算法詳解
適用範圍:給你一個大數n,將它分解它的質因子的乘積的形式。
P.S. 在下面的論述中會使用到Miller_rabin和快速乘法和快速冪,如果有興趣請看另一篇博文。
不過其實你只需要知道Miller_rabin是判斷一個數是否是素數。q_mul是求(a*b)% mod,q_pow是求(a^b) % mod即可。
大數分解最簡單的思想也是試除法,這裡就不再展示程式碼了,就是從2到sqrt(n),一個一個的試驗,直到除到1或者迴圈完,最後判斷一下是否已經除到1了即可。
但是這樣的做的複雜度是相當高的。一種很妙的思路是找到一個因子(不一定是質因子),然後再一路分解下去。這就是基於Miller_rabin的大數分解法Pollard_rho大數分解。
Pollard_rho演算法的大致流程是 先判斷當前數是否是素數(Miller_rabin)了,如果是則直接返回。如果不是素數的話,試圖找到當前數的一個因子(可以不是質因子)。然後遞迴對該因子和約去這個因子的另一個因子進行分解。
那麼自然的疑問就是,怎麼找到當前數n的一個因子?當然不是一個一個慢慢試驗,而是一種神奇的想法。其實這個找因子的過程我理解的不是非常透徹,感覺還是有一點兒試的意味,但不是盲目的列舉,而是一種隨機化演算法。我們假設要找的因子為p,他是隨機取一個x1,由x1構造x2,使得{p可以整除x1-x2 && x1-x2不能整除n}則p=gcd(x1-x2,n
因為x1和x2再調整時最終一定會出現迴圈,形成一個類似希臘字母rho的形狀,故因此得名。
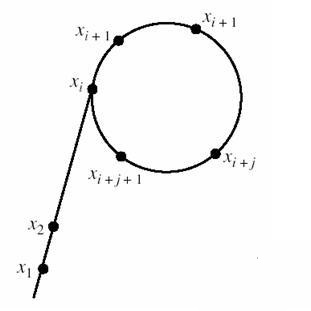
另外通過find函式來分解素數,如果找到了一個素數因子則加入到因子map中,否則如果用Pollard找到一個因子則遞迴去找素數因子。
上程式碼:
#include <iostream> #include <cstdio> #include <algorithm> #include <cmath> #include <cstring> #include <map> using namespace std; const int times = 50; int number = 0; map<long long, int>m; long long Random( long long n ) { return ((double)rand( ) / RAND_MAX*n + 0.5); } long long q_mul( long long a, long long b, long long mod ) //快速乘法取模 { long long ans = 0; while(b) { if(b & 1) { ans += a; } b /= 2; a = (a + a) % mod; } return ans; } long long q_pow( long long a, long long b, long long mod ) //快速乘法下的快速冪,叼 { long long ans = 1; while(b) { if(b & 1) { ans = q_mul( ans, a, mod ); } b /= 2; a = q_mul( a, a, mod ); } return ans; } bool witness( long long a, long long n )//miller_rabin演算法的精華 { long long tem = n - 1; int j = 0; while(tem % 2 == 0) { tem /= 2; j++; } long long x = q_pow( a, tem, n ); //得到a^(n-1) mod n if(x == 1 || x == n - 1) return true; while(j--) { x = q_mul( x, x, n ); if(x = n - 1) return true; } return false; } bool miller_rabin( long long n ) //檢驗n是否是素數 { if(n == 2) return true; if(n < 2 || n % 2 == 0) return false; for(int i = 1; i <= times; i++) //做times次隨機檢驗 { long long a = Random( n - 2 ) + 1; //得到隨機檢驗運算元 a if(!witness( a, n )) //用a檢驗n是否是素數 return false; } return true; } long long gcd( long long a, long long b ) { if(b == 0) return a; return gcd( b, a%b ); } long long pollard_rho( long long n, long long c )//找到n的一個因子 { long long x, y, d, i = 1, k = 2; x = Random( n - 1 ) + 1; y = x; while(1) { i++; x = (q_mul( x, x, n ) + c) % n; d = gcd( y - x, n ); if(1<d&&d<n) return d; if(y == x)//找到迴圈,選取失敗,重新來 return n; if(i == k) //似乎是一個優化,但是不是很清楚 { y = x; k <<= 1; } } } void find( long long n, long long c ) { if(n == 1) return; if(miller_rabin( n )) { m[n]++; number++; return; } long long p = n; while(p >= n) p = pollard_rho( p, c-- ); find( p, c ); find( n / p, c ); } int main( ) { long long tar; while(cin >> tar) { number = 0; m.clear(); find( tar, 2137342 ); printf( "%lld = ", tar ); if(m.empty()) { printf( "%lld\n", tar ); } for(map<long long, int>::iterator c = m.begin(); c != m.end();) { printf( "%lld^%d", c->first, c->second ); if((++c) != m.end()) printf( " * " ); } printf( "\n" ); } return 0; }
五一最後一天好煩躁啊,,端午端午你快點兒來!
相關推薦
大數因數分解Pollard_rho 演算法詳解
適用範圍:給你一個大數n,將它分解它的質因子的乘積的形式。 P.S. 在下面的論述中會使用到Miller_rabin和快速乘法和快速冪,如果有興趣請看另一篇博文。 不過其實你只需要知道Miller_rabin是判斷一個數是否是素數。q_mul是求(a*b)% mod,q_pow是求(a^b) % mo
大數因數分解Pollard_rho 演算法
大數分解最簡單的思想也是試除法,這裡就不再展示程式碼了,就是從2到sqrt(n),一個一個的試驗,直到除到1或者迴圈完,最後判斷一下是否已經除到1了即可。 但是這樣的做的複雜度是相當高的。一種很妙的思路是找到一個因子(不一定是質因子),然後再一路分解下去。這就
Largest Number組合最大數演算法詳解
題目是給出一個非負整數陣列,將他們組合成最大的整數。題目描述如下: Given a list of non negative integers, arrange them such that they form the largest numb
CentOS6.5下如何正確下載、安裝Intellij IDEA、Scala、Scala-intellij-bin插件、Scala IDE for Eclipse助推大數據開發(圖文詳解)
scala 建議 strong 安裝jdk rgs 默認 tell launcher eclipse 第二步:安裝Intellij IDEA 若是3節點如,master、slave1、slave2,則建議將其安裝在master節點上 到https:/
php openssl_sign() 語法+RSA公私鑰加密解密,非對稱加密演算法詳解
其實有時候覺得寫部落格好煩,就個函式就開篇部落格。很小的意見事情而已,知道的人看來多取一舉,或者說沒什麼必要,浪費時間,不知道的人就會很鬱悶。技術就是這樣的,懂的人覺得真的很簡單啊,不知道的人真的好難。。。 一般在跟第三方介面對接資料的時候,為了保證很多都使用的RSA簽名,沒性趣瞭解的同學只需要
Show, attend and tell演算法詳解及原始碼
mark一下,感謝作者分享! https://blog.csdn.net/shenxiaolu1984/article/details/51493673 原論文:https://arxiv.org/pdf/1502.03044v2.pdf 原始碼:https://github.c
資料分析學習之不得不知的八大演算法詳解
學習資料分析的朋友們都知道,演算法是不可或缺的,或者說演算法在一定程度上可以更好的量化的一個人的學習能力和水平,本文感謝科多大資料的馮老師,由他整理了經典的八大演算法,相關的資料希望能幫助大家瞭解。 演算法一:快速排序法 快速排序是由東尼 · 霍爾所發展的一種排序演算法。在平均狀況下,排序
程式設計思想 - 五大常用演算法詳解
https://www.cnblogs.com/brucemengbm/p/6875340.html https://blog.csdn.net/changyuanchn/article/details/51476281 https://www.cnblogs.com/chuninggao/p/
奇異值分解(SVD)原理詳解
一、奇異值與特徵值基礎知識: 特徵值分解和奇異值分解在機器學習領域都是屬於滿地可見的方法。兩者有著很緊密的關係,我在接下來會談到,特徵值分解和奇異值分解的目的都是一樣,就是提取出一個矩陣最重要的特徵。先談談特徵值分解吧: 1)特
Kadane演算法詳解及求解最大子數列和問題
最大子數列和問題 給出一個數列,現在求其中一個子數列,要求是所有子數列的和的最大值。另外還有其他問法,例如給出一個數組,要求求出連續的元素和的最大值。可以一個例子來解釋: 假設有數列:[-1,2,3,-5,6,-2,4],那麼總共有
K-NN近鄰演算法詳解
K-近鄰演算法屬於一種監督學習分類演算法,該方法的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。 (1) 需要進行分類,分類的依據是什麼呢,每個物體都有它的特徵點,這個就是分類的依據,特徵點可
字典序演算法詳解
一、字典序 字典序,就是按照字典中出現的先後順序進行排序。 1、單個字元 在計算機中,25個字母以及數字字元,字典排序如下: '0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... &l
【演算法 詳解】 二維動態規劃
馬攔過河卒 原題傳送門 這一到題目也是比較基礎的動態規劃,也可以理解為是遞推,主要是運用加法原理,思維難度不大。我們要求從 (0,0) ( 0
圖的最小生成樹prim演算法詳解
prim演算法是求圖的最小生成樹的一種演算法,它是根據圖中的節點來進行求解,具體思想大概如下: 首先,將圖的所有節點(我們假定總共有n個節點)分成兩個集合,V和U。其中,集合V儲存的是我們已經訪問過的節點,集合U儲存的是我們未曾訪問的節點。prim演算法第一步就是選定第一個節點放入集合
吳恩達機器學習課程筆記02——處理房價預測問題(梯度下降演算法詳解)
建議記住的實用符號 符號 含義 m 樣本數目 x 輸入變數 y 輸出變數/目標變數
樹鏈剖分演算法詳解
學OI也有一段時間了,感覺該搞點東西了。 於是學習了樹(熟)鏈(練)剖(pou)分(糞) 當然,學習這個演算法是需要先學習線段樹的。不懂的還是再過一段時間吧。 如果碰到一道題,要對一顆樹的兩個點中的最短路徑、以u為根的子樹之類的東西進行修改或者查詢,那麼大概就是樹鏈剖分的題了。 樹鏈剖分就是把一顆
各種排序演算法詳解C++實現
1.氣泡排序 時間複雜度 O ( n
整數拆分演算法詳解
問題描述 輸入一個N,輸出所有拆分的方式。如輸入3 輸出1+1+1 1+2 3 演算法思想 用一個數組res[]存放拆分的解,用全域性變數存放拆分的方法數。divN(n,k)使用n表示要分解的整數,k表示res陣列下標,即第k次拆分。先從divN(n,1)開始,用num表示第
【演算法詳解】對於單調棧的重新理解
對於單調棧的重新理解 關於什麼是單調棧和為什麼要用單調棧: 亂頭髮節 地平線 Largest Rectangle in a Histogram 關於什麼是單調棧和為什麼要用單調棧: 單調棧,就是棧中的元
遞迴演算法詳解
1. 何為遞迴? 遞迴在我們的生活中其實很常見。假設你去電影院看電影,黑漆漆一片,你不知道自己來到了第幾排,於是你問前面的人他是第幾排,知道了前面的人是第幾排,加一也就是你所在的排數。但前面的人也不知道,於是他也繼續向前問,直到第一排的人回答他在第一排,然後再依次往後傳,最後