
解讀pandas的IO操作
pandas檔案讀取和輸出¶
資料分析過程中經常需要進行讀寫操作,Pandas實現了很多 IO 操作的API,這裡簡單做了一個列舉。¶
| 格式型別 | 資料描述 | Reader | Writer |
|---|---|---|---|
| text | CSV | read_ csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | clipboard | read_clipboard | to_clipboard |
| binary | Excel | read_excel | to_excel |
| binary | HDF5 | read_hdf | to_hdf |
| binary | Feather | read_feather | to_feather |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | Python Pickle | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQLGoogle | Big Query | read_gbq | to_gbq |
主要內容¶
檔案讀取
- 1.read_csv
- 2.read_excel
檔案儲存
- 1.to_csv
- 2.to_excel
- 3.to_sql
檔案讀取¶
In [43]:from io import StringIO import pandas as pd
-
- read_csv
讀取 csv 檔案算是一種最常見的操作了。假如已經有人將一些使用者的資訊記錄在了一個csv檔案中,我們如何通過 Pandas 讀取呢?
讀取之前先來看下這個檔案裡的內容吧。
- read_csv
data = pd.read_csv('../friends.csv',encoding='utf-8',index_col='NickName') data.head()Out[44]:
| Unnamed: 0 | Sex | Province | City | Signature | |
|---|---|---|---|---|---|
| NickName | |||||
| 張亞飛 | 0 | 1 | NaN | NaN | 我一定會證明我努力的意義,即使生活一次一次否定它。 |
| Messi | 1 | 1 | 山西 | 晉城 | NaN |
| 夕 | 2 | 2 | 山西 | 晉城 | NaN |
| Irving | 3 | 1 | Offaly | NaN | NaN |
| 苊兒 | 4 | 2 | 山西 | 晉中 | 希望外表的放肆遮得住內心的柔弱 |
In [4]:可以看到,讀取出來生成了一個 DataFrame,索引是自動建立的一個數字,我們可以設定引數 index_col 來將某列設定為索引,可以傳入索引號或者名稱。
""" 除了可以從檔案中讀取,我們還可以從 StringIO 物件中讀取。 """ data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male" print(data) df = pd.read_csv(StringIO(data)) df
name,age,birth,sex Tom,18.0,2000-02-10, Bob,30.0,1988-10-17,maleOut[4]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | 18.0 | 2000-02-10 | NaN |
| 1 | Bob | 30.0 | 1988-10-17 | male |
- 當然了,你還可以設定引數 sep 來自定義欄位之間的分隔符,設定引數 lineterminator 來自定義每行的分隔符。
data = "name|age|birth|sex~Tom|18.0|2000-02-10|~Bob|30.0|1988-10-17|male" df = pd.read_csv(StringIO(data), sep="|", lineterminator="~") dfOut[5]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | 18.0 | 2000-02-10 | NaN |
| 1 | Bob | 30.0 | 1988-10-17 | male |
- 在讀取時,解析器會進行型別推斷,任何非數字列都會以物件dtype的形式出現。當然我們也可以自己指定資料型別
df = pd.read_csv(StringIO(data), sep="|", lineterminator="~", dtype={"age": int}) dfOut[7]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | 18 | 2000-02-10 | NaN |
| 1 | Bob | 30 | 1988-10-17 | male |
- Pandas 預設將第一行作為標題,但是有時候,csv檔案並沒有標題,我們可以設定引數 names 來新增標題。
data="Tom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male" print(data) df = pd.read_csv(StringIO(data), names=["name", "age", "birth", "sex"]) df
Tom,18.0,2000-02-10, Bob,30.0,1988-10-17,maleOut[9]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | 18.0 | 2000-02-10 | NaN |
| 1 | Bob | 30.0 | 1988-10-17 | male |
- 有時候可能只需要讀取部分列的資料,可以指定引數 user_cols
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male" print(data) df = pd.read_csv(StringIO(data), usecols=["name", "age"]) df
name,age,birth,sex Tom,18.0,2000-02-10, Bob,30.0,1988-10-17,maleOut[10]:
| name | age | |
|---|---|---|
| 0 | Tom | 18.0 |
| 1 | Bob | 30.0 |
- 關於缺失值的處理,也是有技巧的。預設引數 keep_default_na=False,會將空值都填充為 NaN。
print(pd.read_csv(StringIO(data))) df = pd.read_csv(StringIO(data), keep_default_na=False) df
name age birth sex 0 Tom 18.0 2000-02-10 NaN 1 Bob 30.0 1988-10-17 maleOut[14]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | 18.0 | 2000-02-10 | |
| 1 | Bob | 30.0 | 1988-10-17 | male |
- 有時候,空值的定義比較廣泛,假定我們認為 18 也是空值,那麼將它加入到引數 na_values 中即可。
df = pd.read_csv(StringIO(data), na_values=[18]) dfOut[16]:
| name | age | birth | sex | |
|---|---|---|---|---|
| 0 | Tom | NaN | 2000-02-10 | NaN |
| 1 | Bob | 30.0 | 1988-10-17 | male |
- to_json
通常在得到了 DataFrame 之後,有時候我們需要將它轉為一個 json 字串,可以使用 to_json 來完成。 轉換時,可以通過指定引數 orient 來輸出不同格式的格式,之後以下幾個引數:
- split 字典像索引 - > [索引],列 - > [列],資料 - > [值]}
- records 列表像{[列 - >值},…,{列 - >值}]
- index 字典像{索引 - > {列 - >值}}
- columns 字典像{列 - > {索引 - >值}}
- values 只是值陣列
In [21]:DataFrame 預設情況下使用 columns 這種形式,Series 預設情況下使用 index 這種形式。
- 設定為 columns 後會將資料作為巢狀JSON物件進行序列化,並將列標籤作為主索引。
- 設定為index 後會將資料作為巢狀JSON物件進行序列化,並將索引標籤作為主索引。
- 設定為 records 後會將資料序列化為列 - >值記錄的JSON陣列,不包括索引標籤。
- 設定為 values 後會將是一個僅用於巢狀JSON陣列值,不包含列和索引標籤。
- 設定為 split 後會將序列化為包含值,索引和列的單獨條目的JSON物件。
df = pd.read_csv("../friends.csv", index_col="NickName").head() print(df) df.to_json()
Unnamed: 0 Sex Province City Signature NickName 張亞飛 0 1 NaN NaN 我一定會證明我努力的意義,即使生活一次一次否定它。 Messi 1 1 山西 晉城 NaN 夕 2 2 山西 晉城 NaN Irving 3 1 Offaly NaN NaN 苊兒 4 2 山西 晉中 希望外表的放肆遮得住內心的柔弱Out[21]:
'{"Unnamed: 0":{"\\u5f20\\u4e9a\\u98de":0,"Messi":1,"\\u5915":2,"Irving":3,"\\u82ca\\u513f":4},"Sex":{"\\u5f20\\u4e9a\\u98de":1,"Messi":1,"\\u5915":2,"Irving":1,"\\u82ca\\u513f":2},"Province":{"\\u5f20\\u4e9a\\u98de":null,"Messi":"\\u5c71\\u897f","\\u5915":"\\u5c71\\u897f","Irving":"Offaly","\\u82ca\\u513f":"\\u5c71\\u897f"},"City":{"\\u5f20\\u4e9a\\u98de":null,"Messi":"\\u664b\\u57ce","\\u5915":"\\u664b\\u57ce","Irving":null,"\\u82ca\\u513f":"\\u664b\\u4e2d"},"Signature":{"\\u5f20\\u4e9a\\u98de":"\\u6211\\u4e00\\u5b9a\\u4f1a\\u8bc1\\u660e\\u6211\\u52aa\\u529b\\u7684\\u610f\\u4e49\\uff0c\\u5373\\u4f7f\\u751f\\u6d3b\\u4e00\\u6b21\\u4e00\\u6b21\\u5426\\u5b9a\\u5b83\\u3002","Messi":null,"\\u5915":null,"Irving":null,"\\u82ca\\u513f":"\\u5e0c\\u671b\\u5916\\u8868\\u7684\\u653e\\u8086\\u906e\\u5f97\\u4f4f\\u5185\\u5fc3\\u7684\\u67d4\\u5f31"}}'
In [22]:
print(df.to_json(orient="index"))
{"\u5f20\u4e9a\u98de":{"Unnamed: 0":0,"Sex":1,"Province":null,"City":null,"Signature":"\u6211\u4e00\u5b9a\u4f1a\u8bc1\u660e\u6211\u52aa\u529b\u7684\u610f\u4e49\uff0c\u5373\u4f7f\u751f\u6d3b\u4e00\u6b21\u4e00\u6b21\u5426\u5b9a\u5b83\u3002"},"Messi":{"Unnamed: 0":1,"Sex":1,"Province":"\u5c71\u897f","City":"\u664b\u57ce","Signature":null},"\u5915":{"Unnamed: 0":2,"Sex":2,"Province":"\u5c71\u897f","City":"\u664b\u57ce","Signature":null},"Irving":{"Unnamed: 0":3,"Sex":1,"Province":"Offaly","City":null,"Signature":null},"\u82ca\u513f":{"Unnamed: 0":4,"Sex":2,"Province":"\u5c71\u897f","City":"\u664b\u4e2d","Signature":"\u5e0c\u671b\u5916\u8868\u7684\u653e\u8086\u906e\u5f97\u4f4f\u5185\u5fc3\u7684\u67d4\u5f31"}}
In [23]:
print(df.to_json(orient="records"))
[{"Unnamed: 0":0,"Sex":1,"Province":null,"City":null,"Signature":"\u6211\u4e00\u5b9a\u4f1a\u8bc1\u660e\u6211\u52aa\u529b\u7684\u610f\u4e49\uff0c\u5373\u4f7f\u751f\u6d3b\u4e00\u6b21\u4e00\u6b21\u5426\u5b9a\u5b83\u3002"},{"Unnamed: 0":1,"Sex":1,"Province":"\u5c71\u897f","City":"\u664b\u57ce","Signature":null},{"Unnamed: 0":2,"Sex":2,"Province":"\u5c71\u897f","City":"\u664b\u57ce","Signature":null},{"Unnamed: 0":3,"Sex":1,"Province":"Offaly","City":null,"Signature":null},{"Unnamed: 0":4,"Sex":2,"Province":"\u5c71\u897f","City":"\u664b\u4e2d","Signature":"\u5e0c\u671b\u5916\u8868\u7684\u653e\u8086\u906e\u5f97\u4f4f\u5185\u5fc3\u7684\u67d4\u5f31"}]
In [24]:
print(df.to_json(orient="values"))
[[0,1,null,null,"\u6211\u4e00\u5b9a\u4f1a\u8bc1\u660e\u6211\u52aa\u529b\u7684\u610f\u4e49\uff0c\u5373\u4f7f\u751f\u6d3b\u4e00\u6b21\u4e00\u6b21\u5426\u5b9a\u5b83\u3002"],[1,1,"\u5c71\u897f","\u664b\u57ce",null],[2,2,"\u5c71\u897f","\u664b\u57ce",null],[3,1,"Offaly",null,null],[4,2,"\u5c71\u897f","\u664b\u4e2d","\u5e0c\u671b\u5916\u8868\u7684\u653e\u8086\u906e\u5f97\u4f4f\u5185\u5fc3\u7684\u67d4\u5f31"]]In [25]:
print(df.to_json(orient="split"))
{"columns":["Unnamed: 0","Sex","Province","City","Signature"],"index":["\u5f20\u4e9a\u98de","Messi","\u5915","Irving","\u82ca\u513f"],"data":[[0,1,null,null,"\u6211\u4e00\u5b9a\u4f1a\u8bc1\u660e\u6211\u52aa\u529b\u7684\u610f\u4e49\uff0c\u5373\u4f7f\u751f\u6d3b\u4e00\u6b21\u4e00\u6b21\u5426\u5b9a\u5b83\u3002"],[1,1,"\u5c71\u897f","\u664b\u57ce",null],[2,2,"\u5c71\u897f","\u664b\u57ce",null],[3,1,"Offaly",null,null],[4,2,"\u5c71\u897f","\u664b\u4e2d","\u5e0c\u671b\u5916\u8868\u7684\u653e\u8086\u906e\u5f97\u4f4f\u5185\u5fc3\u7684\u67d4\u5f31"]]}
-
- read_excel():具體引數read_eccel與read_csv相似
df = pd.read_excel('data/adverse_reaction_database.xlsx') df.head()Out[46]:
| 藥品通用名稱 | 適應症 | 不良反應 | |
|---|---|---|---|
| 0 | 鹽酸甲氧氯普胺注射液 | 腫瘤放化療等所致噁心、嘔吐 | 急性尿瀦留,不能自行小便。 |
| 1 | 甲苯丙胺丸 | NaN | 緊張恐懼。 |
| 2 | 複方磺胺甲噁唑片 | 支氣管炎及肺部、尿路及腸道感染等 | 噁心、食慾不振,胃部燒灼感。 |
| 3 | 利福平片 | 抗結核 | 漸發現全身面板多處紫紅色斑點及持續明道流血。 |
| 4 | 依那普利 | 慢性心衰和(或)頑固性心衰 | 氣促、心悸,下肢水腫。 |
檔案儲存:這裡主要介紹三種常用的儲存方法¶
- to_excel
- to_csv
- to_sql
In [29]:資料我就按比較常見的列表巢狀字典來演示了,這種資料結構也是在各個場景下經常用到的資料結構[{},{},{}…]
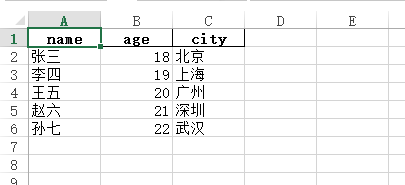
import pandas as pd data = [ {"name":"張三","age":18,"city":"北京"}, {"name":"李四","age":19,"city":"上海"}, {"name":"王五","age":20,"city":"廣州"}, {"name":"趙六","age":21,"city":"深圳"}, {"name":"孫七","age":22,"city":"武漢"} ] df = pd.DataFrame(data,columns=["name","age","city"]) dfOut[29]:
| name | age | city | |
|---|---|---|---|
| 0 | 張三 | 18 | 北京 |
| 1 | 李四 | 19 | 上海 |
| 2 | 王五 | 20 | 廣州 |
| 3 | 趙六 | 21 | 深圳 |
| 4 | 孫七 | 22 | 武漢 |
df.to_csv("data/csv_file.csv",encoding="utf-8",index=False) dfOut[32]:
| name | age | city | |
|---|---|---|---|
| 0 | 張三 | 18 | 北京 |
| 1 | 李四 | 19 | 上海 |
| 2 | 王五 | 20 | 廣州 |
| 3 | 趙六 | 21 | 深圳 |
| 4 | 孫七 | 22 | 武漢 |
In [31]:注意事項:
- 1、一般情況下我們用utf-8編碼進行儲存,如果出現中文編碼錯誤,則可以依次換用gbk,gb2312 , gb18030,一般總能成功的,本例中用utf-8
- 2、to_csv方法,具體引數還有很多,可以去看官方文件,這裡提到一個index = False引數,表示儲存csv的時候,我們不儲存pandas 的Data frame的行索引1234這樣的序號,預設情況不加的話是index = True,會有行號(如下圖),這點在儲存資料庫mysql的時候體現尤其明顯,不注意的話可能會出錯
df.to_csv("data/csv_file.csv",encoding="utf-8") dfOut[31]:
| name | age | city | |
|---|---|---|---|
| 0 | 張三 | 18 | 北京 |
| 1 | 李四 | 19 | 上海 |
| 2 | 王五 | 20 | 廣州 |
| 3 | 趙六 | 21 | 深圳 |
| 4 | 孫七 | 22 | 武漢 |
- 輸出excel檔案
writer = pd.ExcelWriter('data/excel.xlsx') df.to_excel(writer, sheet_name='user', index=False) writer.save()

- 儲存mysql
from sqlalchemy import create_engine table_name = "user" engine = create_engine( "mysql+pymysql://root:[email protected]:3306/db_test?charset=utf8", max_overflow=0, # 超過連線池大小外最多建立的連線 pool_size=5, # 連線池大小 pool_timeout=30, # 池中沒有執行緒最多等待的時間,否則報錯 pool_recycle=-1 # 多久之後對執行緒池中的執行緒進行一次連線的回收(重置) ) conn = engine.connect() df.to_sql(table_name, conn, if_exists='append',index=False)
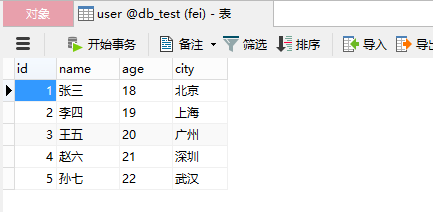

- 上面程式碼已經實現將我們構造的df資料儲存MySQL,現在提一些注意點
注意事項:
1、我們用的庫是sqlalchemy,官方文件提到to_sql是被sqlalchemy支援
文件地址:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
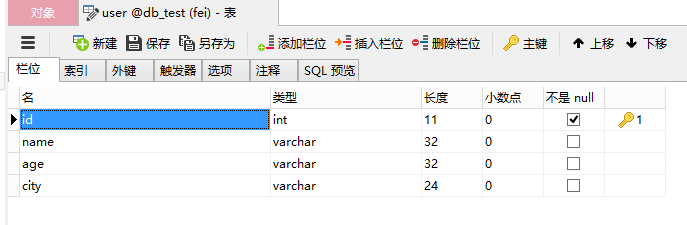
2、資料庫配置用你自己的資料庫配置,db_flag為資料庫型別,根據不同情況更改,在儲存資料之前,要先建立資料庫欄位,下圖是我這邊簡單建立的欄位
3、engine_config為資料庫連線配置資訊
4、create_engine是根據資料庫配置資訊建立連線物件
5、if_exists = 'append',追加資料
6、index = False 儲存時候,不儲存df的行索引,這樣剛好df的3個列和資料庫的3個欄位一一對應,正常儲存,如果不設定為false的話,資料相當於4列,跟MySQL 3列對不上號,會報錯
- 這裡提個小問題,比如我們想在遍歷的時候來一條資料,儲存一條,而不是整體生成Dataframe後才儲存,該怎麼做?上面提到if_exists,可以追加,用這個即可實現,包括儲存csv同樣也有此引數,可以參考官方文件
圖解集合7:紅黑樹概念、紅黑樹的插入及旋轉操作詳細解讀
集合 得到 2個 排序。 數據流 except boolean 修正 split 原文地址http://www.cnblogs.com/xrq730/p/6867924.html,轉載請註明出處,謝謝! 初識TreeMap 之前的文章講解了兩種Map,分別是HashMa
IBM專家親自解讀 Spark2.0 操作指南
Spark 背景介紹 1、什麼是Spark 在Apache的網站上,有非常簡單的一句話,”Spark is a fast and general engine ”,就是Spark是一個統一的計算引擎,而且突出了fast。那麼具體是做什麼的呢?是做large-scale的p
解讀Android之ContentProvider(1)CRUD操作
本文翻譯自android官方文件,結合自己測試,整理如下。 Content providers能夠管理結構化的資料集,封裝資料,並且能夠提供資料安全的機制。Content providers是一種標準的介面,能夠跨程序資料共享。中文可以被稱為內容提供器。 當
解讀pandas的IO操作
pandas檔案讀取和輸出¶ 資料分析過程中經常需要進行讀寫操作,
棧+佇列的基本操作實現(嚴蔚敏版設計思路解讀c++)
大家好,我是集美貌與才華於一身的阿俊吶,咳咳咳…不接受任何反駁,感謝你辣麼好看還來關注我,嘿嘿嘿,讓我們進入正題叭…biu~ biu~… 這篇部落格主要是我學完資料結構(嚴蔚敏版),想記錄下來以後複習用。 從零搭建起棧和佇列的操作 順序動態棧和動
F28027第九課---SPI操作解讀
這周又是忙碌的一週,經常加班到一兩點,又荒廢了將近一週,都不好意思了,所以今天把事情做完後,匆忙吃晚飯就回來了。 今天我們要學習的是SPI(Serial Peripheral Interface)序列外設介面。 先來看個總圖: 從上面大概可以知道,SP
F28027第十課---SCI操作解讀
今天我們先來學習下SCI的理論知識,明天再進行實踐課學習。 SCI(serial communications interface),序列通訊介面。其他今晚剛看SCI定義的時候,很自然的就跟SPI關聯起來了,然後我就去查了下SPI跟SCI之間的區別: SCI
【資料結構與演算法】B tree 即相關操作 深入解讀
B tree是從其他搜尋樹結構中延伸出來的一種用於外存裝置比如disk的一種資料結構。先拋開B tree與disk的關係,單純地瞭解下資料結構。 1.定義 粗略地來講,B tree定義主要包含以下幾個方面: (1)每一個節點的結構,節點包含關鍵字key,指標pointer,
F28027第八課---ADC操作解讀
已經有三天沒有寫了,心裡真過意不過,但最近確實真的太忙了,大家見諒。 前面那幾節課,我們基本上把F28027自身的特性瞭解了一下,從這節課開始,我們將要學習它的外設,我的目標是週末這兩天,要把ADC、溫度、比較器、ePWM、SPI都瞭解完,並完成對應的實踐練習
.NETCore3.1中的Json互操作最全解讀-收藏級
前言 本文比較長,我建議大家先點贊、收藏後慢慢閱讀,點贊再看,形成習慣! 我很高興,.NETCore終於來到了3.1LTS版本,並且將支援3年,我們也準備讓部分業務遷移到3.1上面,不過很快我們就遇到了新的問題,就是對於Json序列化的選擇;我本著清真的原則,既然選擇遷移到3.1,一切都應該用官方標準或者建議
Selenium系列(十) - 針對Select下拉框的操作和原始碼解讀
如果你還想從頭學起Selenium,可以看看這個系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基礎知識,需要自己去補充哦,博主暫時沒有總結(雖然我也會,所以我學selenium就不用複習前端了哈哈哈.
Selenium系列(21) - Cookie操作和原始碼解讀
如果你還想從頭學起Selenium,可以看看這個系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基礎知識,需要自己去補充哦,博主暫時沒有總結(雖然我也會,所以我學selenium就不用複習前端了哈哈哈.
數據結構--Avl樹的創建,插入的遞歸版本和非遞歸版本,刪除等操作
pop end eem static cout 遞歸 sta div else AVL樹本質上還是一棵二叉搜索樹,它的特點是: 1.本身首先是一棵二叉搜索樹。 2.帶有平衡條件:每個結點的左右子樹的高度之差的絕對值最多為1(空樹的高度為-1)。 也就是說,AV
WinForm 控件TabelControl對TabelPage頁的添加,刪除操作
sender control dex bsp for class spa pri void 一般是寫一個按鈕點擊事件 實現了選中那個關那個 //點擊添加按鈕 private void button1_Click(object send
xubuntu 17.04 和 iphone 6互傳文件方法——使用libimobiledevice就可以像u盤一樣操作文件了
ges this med ipo val apt app edev pair I need to preface this by saying I‘m also new to Linux, but I‘ve got it working I think. The inst
python音頻處理用到的操作
single mes 語句 install whl fig show true htm 作者:桂。 時間:2017-05-03 12:18:46 鏈接:http://www.cnblogs.com/xingshansi/p/6799994.html 前言
python基礎之socket編程-------基於tcp的套接字實現遠程執行命令的操作
logs lose stream res std 遠程控制 python log out 遠程實現cmd功能: import socket import subprocess phone=socket.socket(socket.AF_INET,socket.SOC
List Except 操作,IEqualityComparer 使用
exce .text stat his var out turn line 貴州 1.此接口用於對集合 的自定義相等比較算法的實現。包含2個方法: Equals(T,T): 確定指定的對象是否相等。 T 為要比較的對象類型; GetHashCode(T)
MYSQL常用日期操作
距離 rda user rdate bsp nth 當前 core tween mysql查詢今天、昨天、7天、近30天、本月、上一月 數據 今天 select * from 表名 where to_days(時間字段名) = to_days(now()); 昨天
jquery 操作 select 默認選擇第一個元素
tar easy eset 思路 blog reset function 標簽 數組元素 問題:點擊按鈕設置select元素的默認選項。 首先,有個環境,並引入jquery。 <!DOCTYPE html> <html> <h