
CNN中的卷積操作
CNN中的卷積
很多文章都介紹過卷積的操作:用一個小的卷積核在影象上滑動,每次滑動計算出一個值,比如用3*3的卷積核卷積一個5*5的矩陣(不考慮擴充套件邊緣),過程如下:
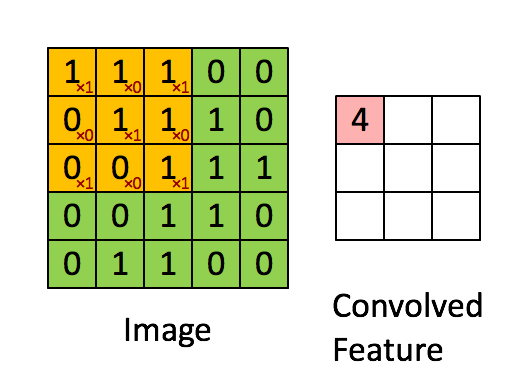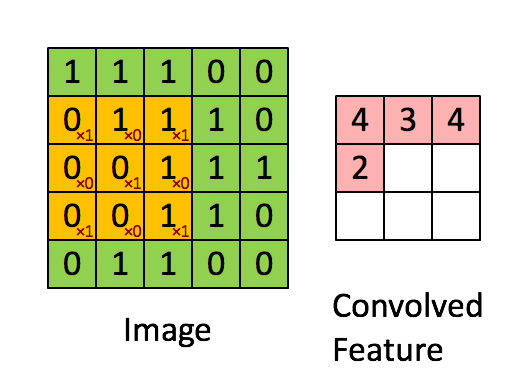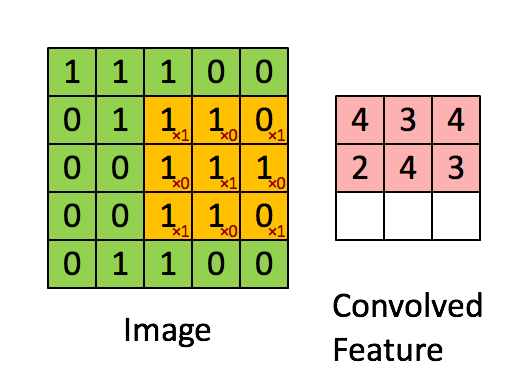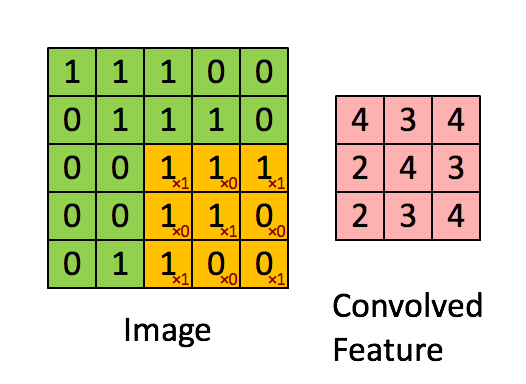
卷積操作在二維平面上很好理解,但是在CNN中,被卷積的矩陣是有深度的:

這個深度可以類比三通道的RGB影象想象。所以被卷積的矩陣的維度是depth*height*width,那麼針對這樣的矩陣,卷積操作是如何進行的呢?一次卷積涉及到的引數量又是多少呢?
斯坦福的教程裡說:
Every filter is small spatially (along width and height), but extends through the full depth of the input volume.
大致意思就是,每次卷積的操作是在“一小塊兒面積,但是全部深度”上進行的。假如這一層輸入的維度是32*32*3,卷積核的維度是5*5*3(這裡,5*5兩個維度可以隨意設計,但是3是固定的,因為輸入資料的第三維度的值是3),那麼得到的輸入應該是28*28*1的。問題來了,怎麼把立體的卷積成平面了呢?
上邊的操作只使用了一個卷積核,如果使用多個卷積核呢,比如12個?那得到的輸入就是立體的了28*28*12。沒錯,CNN中就是這麼操作的,但是請注意兩個名詞區域性連線和權值共享,關於這兩個詞有很多解釋,這裡不再贅述。
然後來計算一下引數量
還是上邊的例子:32*32*3的輸入,5*5*3的卷積核,需要的引數個數是5*5*3=75.
該層使用12個卷積核的話,總引數個數(沒有算偏置項)5*5*3*12=900.
可以看一下caffe中conv的原始碼:
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const 上邊呼叫的forward_cpu_gemm也貼過來:
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_ / group_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}conv_im2col_cpu:貼過來:
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
Dtype* data_col) {
int height_col = (height + 2 * pad_h - kernel_h) / stride_h + 1;
int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
int channels_col = channels * kernel_h * kernel_w;
for (int c = 0; c < channels_col; ++c) {
int w_offset = c % kernel_w;
int h_offset = (c / kernel_w) % kernel_h;
int c_im = c / kernel_h / kernel_w;
for (int h = 0; h < height_col; ++h) {
for (int w = 0; w < width_col; ++w) {
int h_pad = h * stride_h - pad_h + h_offset;
int w_pad = w * stride_w - pad_w + w_offset;
if (h_pad >= 0 && h_pad < height && w_pad >= 0 && w_pad < width)
data_col[(c * height_col + h) * width_col + w] =
data_im[(c_im * height + h_pad) * width + w_pad];
else
data_col[(c * height_col + h) * width_col + w] = 0;
}
}
}
}`caffe_cpu_gemm“貼過來:
template<>
void caffe_cpu_gemm<double>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const double alpha, const double* A, const double* B, const double beta,
double* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_dgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}相關推薦
CNN中卷積層的計算細節
原文連結: https://zhuanlan.zhihu.com/p/29119239 卷積層尺寸的計算原理 輸入矩陣格式:四個維度,依次為:樣本數、影象高度、影象寬度、影象通道數 輸出矩陣格式:
由淺入深:CNN中卷積層與轉置卷積層的關系
更多 deep 每次 展開 大禮包 位移 入門 ssg 得出 歡迎大家前往騰訊雲+社區,獲取更多騰訊海量技術實踐幹貨哦~ 本文由forrestlin發表於雲+社區專欄 導語:轉置卷積層(Transpose Convolution Layer)又稱反卷積層或分數卷積層,在
理解影象中卷積操作的含義
上文用生動的例子來解釋卷積記載了卷積的含義,現在就來看看卷積在影象處理中的應用吧。(ps:本文大部分內容系轉載大神的部落格,現在csdn強制圖片水印,實在感到很無奈!!!) 數字影象處理中卷積 數字影象是一個二維的離散訊號,對數字影象做卷積操作其實就是利用卷
由淺入深:CNN中卷積層與轉置卷積層的關係
歡迎大家前往騰訊雲+社群,獲取更多騰訊海量技術實踐乾貨哦~ 導語:轉置卷積層(Transpose Convolution Layer)又稱反捲積層或分數卷積層,在最近提出的卷積神經網路中越來越常見了,特別是在對抗生成神經網路(GAN)中,生成器網路中上取樣部分就出現了轉置卷積層,用於恢復減少的維數。那麼,轉
CNN中卷積層的詳細計算
前幾天在看CS231n中的CNN經典模型講解時,花了一些時間才搞清楚卷積層輸入輸出的尺寸關係到底是什麼樣的,現總結如下。(可以參照我畫的題圖理解卷積層的運算)卷積層尺寸的計算原理輸入矩陣格式:四個維度,依次為:樣本數、影象高度、影象寬度、影象通道數輸出矩陣格式:與輸出矩陣的維度順序和含義相同,但是後三個維度(
CNN中卷積方式大彙總
1.原始版本 最早的卷積方式還沒有任何騷套路,那就也沒什麼好說的了。 見下圖,原始的conv操作可以看做一個2D版本的無隱層神經網路。 附上一個卷積詳細流程: 【TensorFlow】tf.nn.conv2d是怎樣實現卷積的? - CSDN部落格
CNN中的卷積操作
CNN中的卷積 很多文章都介紹過卷積的操作:用一個小的卷積核在影象上滑動,每次滑動計算出一個值,比如用3*3的卷積核卷積一個5*5的矩陣(不考慮擴充套件邊緣),過程如下: 卷積操作在二維平面上很好理解,但是在CNN中,被卷積的矩陣是有深度的: 這個
CNN中feature map、卷積核、卷積核個數、filter、channel的概念解釋,以及CNN 學習過程中卷積核更新的理解
feature map、卷積核、卷積核個數、filter、channel的概念解釋 feather map的理解 在cnn的每個卷積層,資料都是以三維形式存在的。你可以把它看成許多個二維圖片疊在一起(像豆腐皮一樣),其中每一個稱為一個feature map。 feather map 是怎
總結CNN的發展歷程,以及一些卷積操作的變形,附帶基礎的深度學習知識與公式
1.Lenet-5 :最先出現的卷積神經網路,1998年,由於當時的硬體還不成熟,因此到了2012年出現了AlexNet 2.AlexNet:可以說是現在卷積神經網路的雛形 3.VGGNet:五個模組的卷積疊加,網路結構如下: 4.GoogleNet:ince
關於CNN(卷積神經網路)中一些基本要點的簡要敘述
現階段卷積神經網路基本是以下幾個過程 : 1.卷積(Convolution) 2.非線性處理(ReLu) 3.池化(Pooling) 4.全連線層進行分類(Fully Connected) 假設輸入影象可以是狗 ,貓,船,鳥,當我們輸入一張船的影象的時候,卷
手動實現卷積神經網路中的卷積操作(conv2d)
寫這個的原因:一來好像沒怎麼搜到別人手動實現,作為補充;二來鞏固一下基礎。 卷積操作示意 先從一張示意圖說起,卷積基礎概念和操作步驟就不囉嗦了,只講這張圖,大意就是,有in-channel,有out-channel,你需要把in-channel都做卷積操作,然
卷積操作中特徵值大小的計算
感想 今年對我來說是非常重要的一年,面臨著找工作和發論文的壓力,因此,我打算把我機器學習刷題之路記錄下來,我認為刷題要把原理弄明白,所以我整理了分析的內容,作為對自己的提高,也希望對大家能夠有所幫助。 Problem 輸入圖片大小為200×200,依次經過一層卷積(
關於深度學習中卷積核操作
直接舉例進行說明輸出圖片的長和寬。 輸入照片為:32*32*3, 這是用一個Filter得到的結果,即使一個activation map。(filter 總會自動擴充到和輸入照片一樣的depth)。 當我們用6個5*5的Filter時,我們將會得到6個分開的acti
CNN(卷積神經網路)在視訊動作分類中的應用
簡介 最近接觸了一些卷積神經網路的只是以及其在視訊動作分類中的應用,本文對其進行一下小結。CNN在影象任務,比如ImageNet上取得很好的效果,但是在視訊相關的任務中還沒有太大的進展。取得比較好效果的有兩篇文章,一篇是Stanford發表在CVPR
CNN神經網路之卷積操作
在看這兩個函式之前,我們需要先了解一維卷積(conv1d)和二維卷積(conv2d),二維卷積是將一個特徵圖在width和height兩個方向進行滑動視窗操作,對應位置進行相乘求和;而一維卷積則只是在width或者height方向上進行滑動視窗並相乘求和。 一維卷積:tf.layers.conv1d()
caffe原始碼深入學習6:超級詳細的im2col繪圖解析,分析caffe卷積操作的底層實現
在先前的兩篇部落格中,筆者詳細解析了caffe卷積層的定義與實現,可是在conv_layer.cpp與base_conv_layer.cpp中,卷積操作的實現仍然被隱藏,通過im2col_cpu函式和caffe_cpu_gemm函式(後者實現矩陣乘法)實現,在此篇部落格中,筆者旨在向大家展示,caf
0024-利用OpenCV的filter2D函式作影象的卷積操作和協相關操作
影象的卷積操作是影象處理中最常用的操作之一,一般是用核算子來實現卷積操作。什麼叫核算子?請移步博文https://blog.csdn.net/lehuoziyuan/article/details/84101788 OpenCV用函式filter2D來實現對影象或矩陣的卷積操作。這個函式本質上做
pytorch 自定義卷積核進行卷積操作
一 卷積操作:在pytorch搭建起網路時,大家通常都使用已有的框架進行訓練,在網路中使用最多就是卷積操作,最熟悉不過的就是 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation
Keras中卷積LSTM的使用
Keras官方自帶了很多實用的模型教程,地址在https://github.com/keras-team/keras/tree/master/examples,這裡主要是conv_lstm.py的基礎上進行了一定修改,來實現一個非常簡單的運動預測
CNN 的卷積過程為什麼 要將卷積核旋轉180°
CNN(卷積神經網路)的誤差反傳(error back propagation)中有一個非常關鍵的的步驟就是將某個卷積(Convolve)層的誤差傳到前一層的池化(Pool)層上,因為在CNN中是2D反傳,與傳統神