
10天Hadoop快速突擊(5)——Hadoop I/O操作
Hadoop IO操作
意義
Hadoop自帶一套用於I/O的原子性的操作
(不會被執行緒排程機制打斷,一直到結束,中間不會有任何context switch)
特點
基於保障海量資料集的完整性和壓縮性
Hadoop提供了一些用於開發分散式系統的API(一些序列化操作+基於磁碟的底層資料結構)
一、資料完整性
hdfs寫入的時候計算出校驗和,然後每次讀的時候再計算校驗和。要注意的一點是,hdfs每固定長度就會計算一次校驗和,這個值由io.bytes.per.checksum指定,預設是512位元組。因為CRC32是32位即4個位元組,這樣校驗和佔用的空間就會少於原資料的1%。1%這個數字在hadoop中會經常看到。以後有時間會整理一份hadoop和1%不得不說的故事。
實現
LocalFileSystem繼承自ChecksumFileSystem,已經實現了checksum功能,checksum的資訊儲存在與檔名同名的crc檔案中,發現錯誤的檔案放在bad_files資料夾中。如果你確認頂層系統已經實現了checksum功能,那麼你就沒必要使用LocalFileSystem,改為用RowLocalFileSystem。可以通過更改fs.file.impl=org.apache.hadoop.fs.RawLoacalFileSystem全域性指定,也可以通過程式碼直接例項化。- Configuration conf=...
- FileSystem fs=new RawLocalFileSystem();
- fs.initialize(null, conf);
- FileSystem rawFs=...
- FileSystem checksummedFs=new ChecksumFileSystem(fs){} ;
二、檔案格式
Hadoop中的檔案格式大致上分為面向行和麵向列兩類:
面向行:同一行的資料儲存在一起,即連續儲存。SequenceFile,MapFile,Avro Datafile。採用這種方式,如果只需要訪問行的一小部分資料,亦需要將整行讀入記憶體,推遲序列化一定程度上可以緩解這個問題,但是從磁碟讀取整行資料的開銷卻無法避免。面向行的儲存適合於整行資料需要同時處理的情況。
面向列:整個檔案被切割為若干列資料,每一列資料一起儲存。Parquet , RCFile,ORCFile。面向列的格式使得讀取資料時,可以跳過不需要的列,適合於只處於行的一小部分欄位的情況。但是這種格式的讀寫需要更多的記憶體空間,因為需要快取行在記憶體中(為了獲取多行中的某一列)。同時不適合流式寫入,因為一旦寫入失敗,當前檔案無法恢復,而面向行的資料在寫入失敗時可以重新同步到最後一個同步點,所以Flume採用的是面向行的儲存格式。
1. SequenceFile
SequenceFile的檔案結構如下:
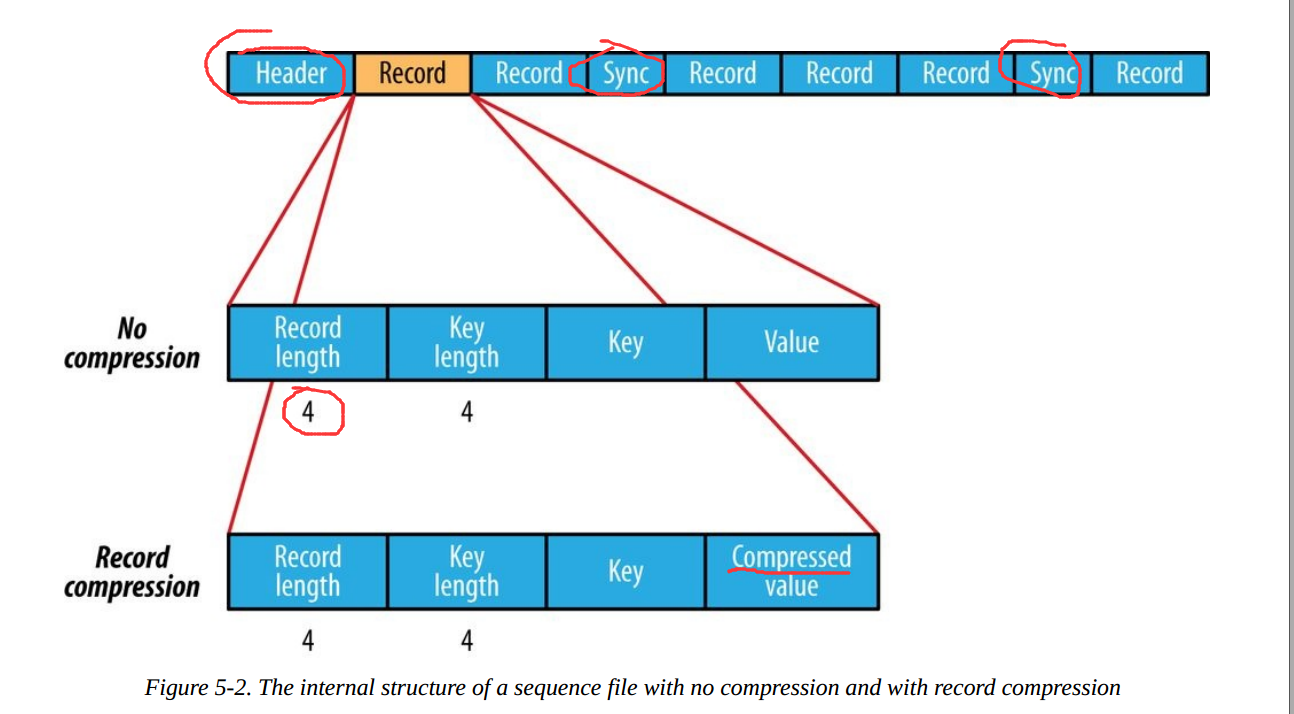
根據是否壓縮,以及採用記錄壓縮還是塊壓縮,儲存格式有所不同:
不壓縮:
按照記錄長度、Key長度、Value程度、Key值、Value值依次儲存。長度是指位元組數。採用指定的Serialization進行序列化。Record壓縮:
只有value被壓縮,壓縮的codec儲存在Header中。Block壓縮:
多條記錄被壓縮在一起,可以利用記錄之間的相似性,更節省空間。Block前後都加入了同步標識。Block的最小值由io.seqfile.compress.blocksize屬性設定。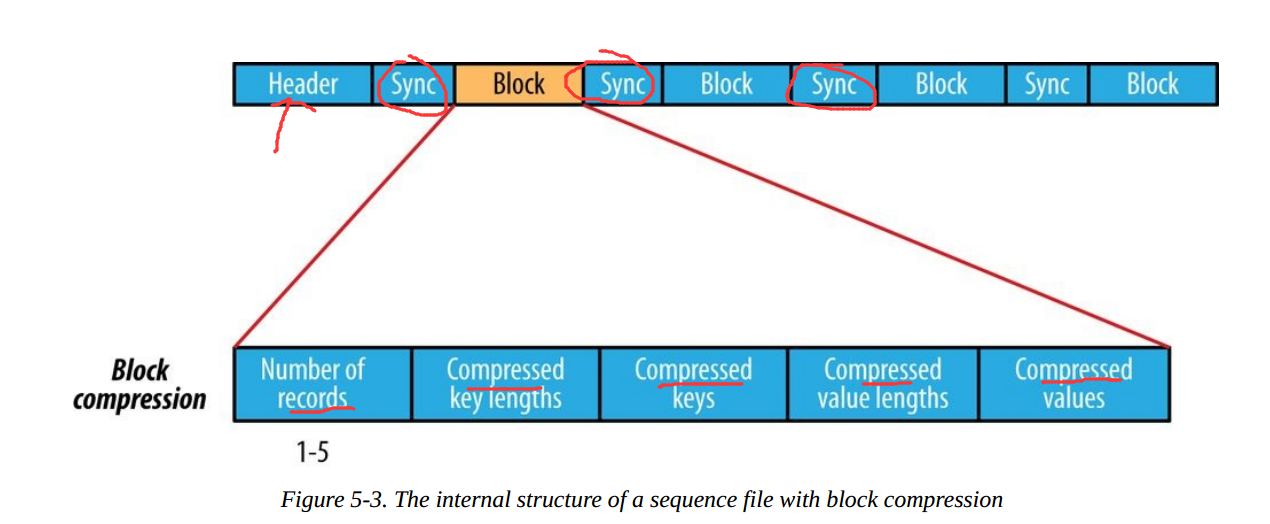
2. MapFile
MapFile是SequenceFile的變種,在SequenceFile中加入索引並排序後就是MapFile。索引作為一個單獨的檔案儲存,一般每個128個記錄儲存一個索引。索引可以被載入記憶體,用於快速查詢。存放資料的檔案根據Key定義的順序排列。
MapFile的記錄必須按照順序寫入,否則丟擲IOException。
MapFile的衍生型別:
- SetFile:特殊的MapFile,用於儲存一序列Writable型別的Key。Key按照順序寫入。
- ArrayFile:Key為整數,代表在陣列中的位置,value為Writable型別。
- BloomMapFile:針對MapFile的get()方法,使用動態Bloom過濾器進行優化。過濾器儲存在記憶體中,只有帶key值存在的時候,才會呼叫常規的get()方法,真正進行讀操作。
Hadoop體系下面向列的檔案包括RCFile,ORCFile,Parquet的。Avro的面向列版本為Trevni。
三、壓縮
hadoop對於壓縮格式的是透明識別,我們的MapReduce任務的執行是透明的,hadoop能夠自動為我們 將壓縮的檔案解壓,而不用我們去關心。
如果我們壓縮的檔案有相應壓縮格式的副檔名(比如lzo,gz,bzip2等),hadoop就會根據副檔名去選擇解碼器解壓。hadoop對每個壓縮格式的支援,詳細見下表:| 壓縮格式 | 工具 | 演算法 | 副檔名 | 多檔案 | 可分割性 |
| DEFLATE | 無 | DEFLATE | .deflate | 不 | 不 |
| gzip | gzip | DEFLATE | .gz | 不 | 不 |
| ZIP | zip | DEFLATE | .zip | 是 | 是,在檔案範圍內 |
| bzip2 | bzip2 | bzip2 | .bz2 | 不 | 是 |
| LZO | lzop | LZO | .lzo | 不 | 是 |
hadoop下各種壓縮演算法的壓縮比,壓縮時間,解壓時間見下表:
| 壓縮演算法 | 原始檔案大小 | 壓縮後的檔案大小 | 壓縮速度 | 解壓縮速度 |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO-bset | 8.3GB | 2GB | 4MB/s | 60.6MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/S | 74.6MB/s |
四、序列化
1、什麼是序列化?
將結構化物件轉換成位元組流以便於進行網路傳輸或寫入持久儲存的過程。
2、什麼是反序列化?
將位元組流轉換為一系列結構化物件的過程。
序列化用途:
1、作為一種持久化格式。
2、作為一種通訊的資料格式。
3、作為一種資料拷貝、克隆機制。
Java序列化和反序列化
1、建立一個物件實現了Serializable
2、序列化:ObjectOutputStream.writeObject(序列化物件)
反序列化:ObjectInputStream.readObject()返回序列化物件
具體實現,可參考如下文章:
http://blog.csdn.net/scgaliguodong123_/article/details/45938555
為什麼Hadoop不直接使用java序列化?
Hadoop的序列化機制與Java的序列化機制不同,它將物件序列化到流中,值得一提的是java的序列化機制是不斷的建立物件,但在hadoop的序列化機制中,使用者可以複用物件,這樣就減少了java物件的分配和回收,提高了應用效率。
Hadoop序列化
Hadoop的序列化不採用java的序列化,而是實現了自己的序列化機制。
Hadoop通過Writable介面實現的序列化機制,不過沒有提供比較功能,所以和java中的Comparable介面合併,提供一個介面WritableComparable。(自定義比較)
Writable介面提供兩個方法(write和readFields)。
- package org.apache.hadoop.io;
- public interface Writable {
- void write(DataOutput out) throws IOException;
- void readFields(DataInput in) throws IOException;
- }
- 需要進行比較的話,要實現WritableComparable介面。
- public interfaceWritableComparable<T> extendsWritable, Comparable<T>{
- }
Hadoop提供了幾個重要的序列化介面與實現類:
外部集合的比較器
RawComparator<T>、WritableComparator
- package org.apache.hadoop.io;
- public interfaceRawComparator<T> extendsComparator<T> {
- public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
- }
- public classWritableComparatorimplementsRawComparator{
- private final Class<? extendsWritableComparable> keyClass;
- privatefinalWritableComparablekey1;
- privatefinalWritableComparablekey2;
- }
實現了WritableComparable介面的類(自定義比較)
- org.apache.hadoop.io
- 介面
- WritableComparable<T>
- 父介面
- Comparable<T>, Writable
- 基礎實現類
- BooleanWritable, ByteWritable, ShortWritable,IntWritable,
- VIntWritable,LongWritable, VLongWritable , FloatWritable, DoubleWritable
- 高階實現類
- MD5Hash, NullWritable,Text, BytesWritable,ObjectWritable,GenericWritab
僅實現了Writable介面的類
- org.apache.hadoop.io
- Interface(介面) Writable
- All Known Subinterfaces(子介面):
- Counter, CounterGroup, CounterGroupBase<T>, InputSplit, InputSplitWithLocationInfo, WritableComparable<T>
- 僅實現了Writable介面的類
- 陣列:AbstractWritable、TwoDArrayWritable
- 對映:AbstractMapWritable、MapWritable、SortedMapWritabl
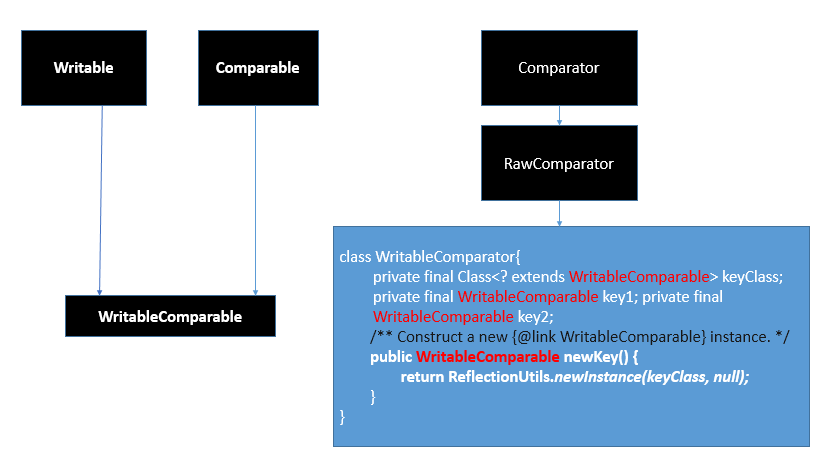
Writable介面
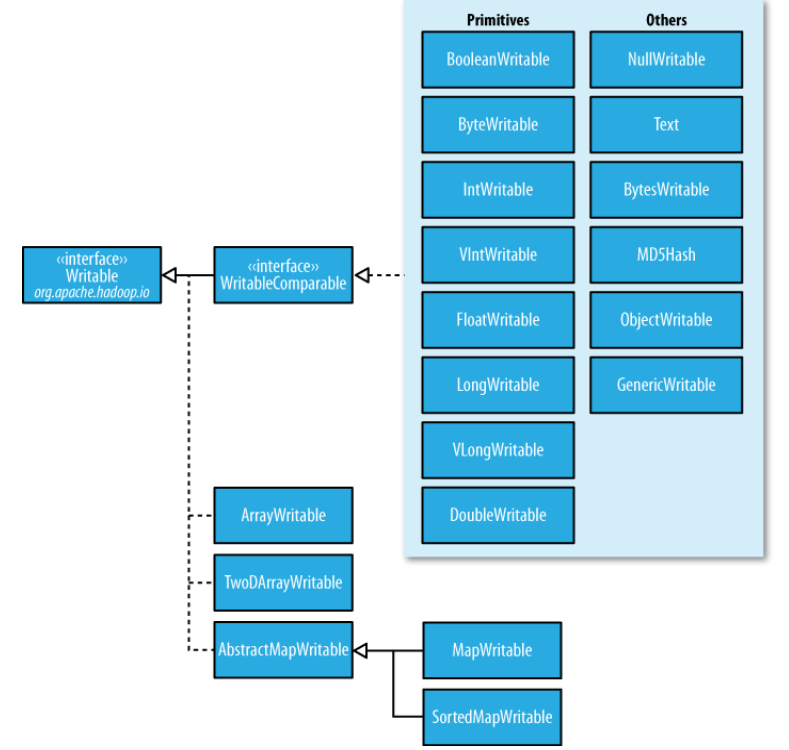
Text
Text是UTF-8的Writable,可以理解為java.lang.String相類似的Writable。Text類替代了UTF-8類。Text是可變的,其值可以通過呼叫set()方法改變。最大可以儲存2GB的大小。
NullWritable
NullWritable是一種特殊的Writable型別,它的序列化長度為零,可以用作佔位符。
BytesWritable
BytesWritable是一個二進位制資料陣列封裝,序列化格式是一個int欄位。
例如:一個長度為2,值為3和5的位元組陣列序列後的結果是:
- publicvoidtestByteWritableSerilizedFromat() throws IOException {
- BytesWritable bytesWritable=new BytesWritable(new byte[]{3,5});
- byte[] bytes=SerializeUtils.serialize(bytesWritable);
- Assert.assertEquals(StringUtils.byteToHexString(bytes),"000000020305"); //true
- }
BytesWritable是可變的,其值可以通過呼叫set()方法來改變。
ObjectWritable
ObjectWritable適用於欄位使用多種型別時。
Writable集合
1、ArrayWritable和TwoDArrayWritable是針對陣列和二維陣列。
2、MapWritable和SortedMapWritable是針對Map和SortMap。
自定義Writable
1、實現WritableComparable介面
2、實現相應的介面方法:
A.write() //將物件轉換為位元組流並寫入到輸出流out中。
B.readFileds() //從輸入流in中讀取位元組流併發序列化為物件。
C.compareTo(o) //將this物件和物件o進行比較。
可參考下面的例子,自定義NewK2類:
http://blog.csdn.net/scgaliguodong123_/article/details/46010947
- package Writable;
- import java.io.BufferedInputStream;
- import java.io.BufferedOutputStream;
- import java.io.DataInput;
- import java.io.DataInputStream;
- import java.io.DataOutput;
- import java.io.DataOutputStream;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.io.WritableComparable;
- public classDefineWritable{
- publicstaticvoidmain(String[] args) throws IOException {
- Student student = new Student("liguodong", 22, "男");
- BufferedOutputStream bos = new BufferedOutputStream(
- new FileOutputStream(new File("g:/liguodong.txt")));
- DataOutputStream dos = new DataOutputStream(bos);
- student.write(dos);
- dos.flush();
- dos.close();
- bos.close();
- Student student2 = new Student();
- BufferedInputStream bis = new BufferedInputStream(
- new FileInputStream(new File("g:/liguodong.txt")));
- DataInputStream dis = new DataInputStream(bis);
- student2.readFields(dis);
- System.out.println("name="+student2.getName()
- +",age="+student2.getAge()+",sex="+student2.getSex());
- }
- }
- class Student implements WritableComparable<Student>{
- private Text name = new Text();
- private IntWritable age = new IntWritable();
- private Text sex = new Text();
- publicStudent() {
- }
- publicStudent(String name, int age, String sex) {
- super();
- this.name = new Text(name);
- this.age = new IntWritable(age);
- this.sex = new Text(sex);
- }
- public Text getName() {
- return name;
- }
- publicvoidsetName(Text name) {
- this.name = name;
- }
- public IntWritable getAge