
神經網路中的activation function到底扮演什麼樣的角色
參考Quora
為python作者Sebastian Raschka的回答
要回答這個問題,首先從線性迴歸(Linear Regression)說起,然後過度到邏輯迴歸(Logistic Regression),最後,過度到神經網路(Neural Network)
1.線性迴歸(Linear Regression)
所謂線性迴歸問題,就是針對某一個問題(例如:房價的預測問題),利用訓練樣本求解一個線性模型,然後利用這個線性模型去預測新的資料所對應的結果
例如:線性迴歸模型如下
2.邏輯迴歸問題(Logistic Regression)
將線性分類模型中的輸出
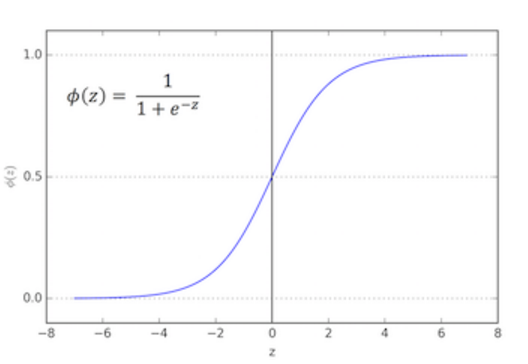
這個activation function返回的是一個概率值(某一個樣本屬於類1的概率):
接下來,在這個activation function後面新增一個step function,例如:
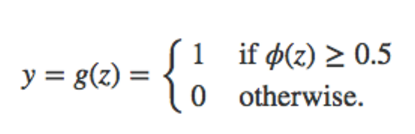
也就是說,如果activation function的輸出大於0.5,就認為輸入的樣本屬於類1,從而實現了分類
這個分類過程可以用下圖來表示
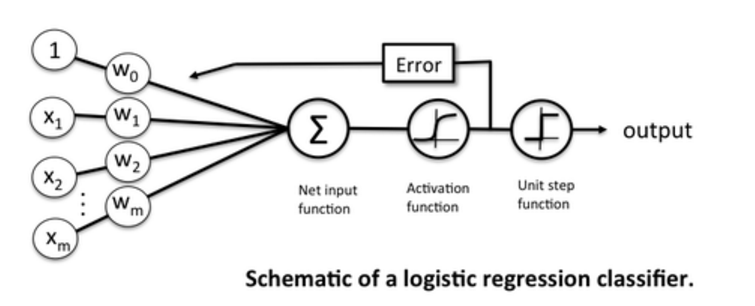
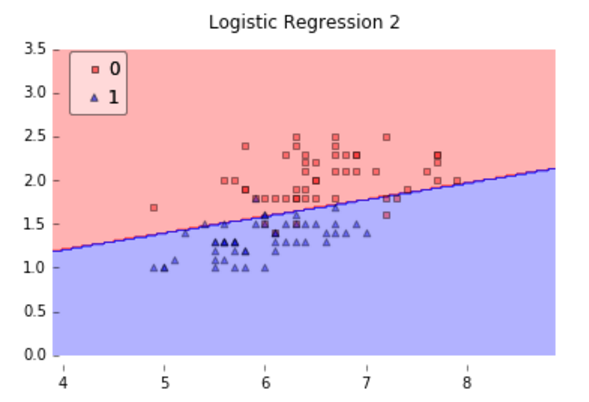
邏輯迴歸模型是一個線性模型(雖然它使用了非線性activation function),因為它的分類面是線性的,下圖給出了利用邏輯迴歸模型進行分類的一個例子:
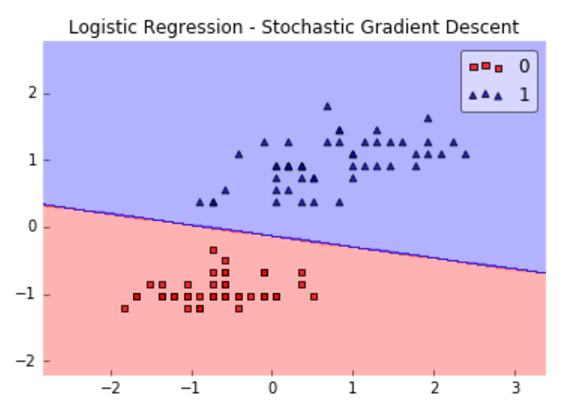
可以看到,因為樣本是線性可分的,所以邏輯迴歸模型的效果很好;
但當樣本不是線性可分時,邏輯迴歸模型就沒那麼好的效能了,如下圖所示的例子,樣本為非線性可分,邏輯迴歸模型效果就不是很好了
那麼,一個非線性分類器就是一個很好的選擇了!例如:MLP!
3.Multi-layer neural network
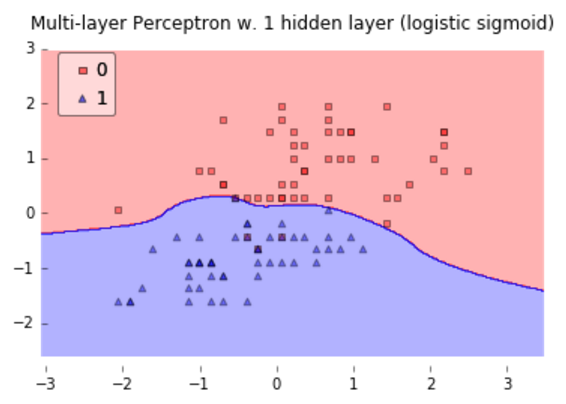
下圖是利用一個僅含有一個隱藏層的神經網路進行分類得到的結果,可以看到,MLP實現了非線性分類面的獲取
下圖是一個簡單的MLP的結構,
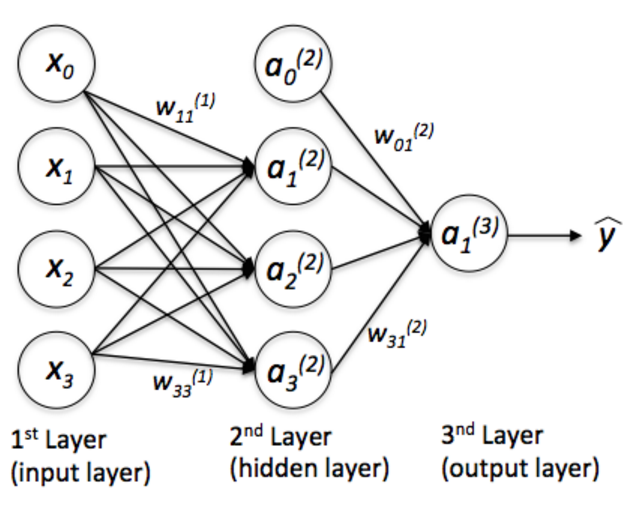
該網路有:
三個輸入單元:
x0=1 for the bias unit, andx1 andx2 for the 2 features (即二維座標系中的點)隱藏層含有200個neurons,分別帶有一個activation function(圖中只畫出了3個)
輸出層含有一個單元(是一個概率值)
4. 總結
邏輯迴歸分類器雖然具有非線性啟用函式,但該模型仍舊是權值的線性組合,所以說,邏輯迴歸分類器是一個”generalized” linear model
activation function的角色:通過對網路的加權輸入(weighted inputs)進行非線性組合產生非線性分類面
To sum it up, the logistic regression classifier has a non-linear activation function, but the weight coefficients of this model are essentially a linear combination, which is why logistic regression is a “generalized” linear model. Now, the role of the activation function in a neural network is to produce a non-linear decision boundary via non-linear combinations of the weighted inputs.
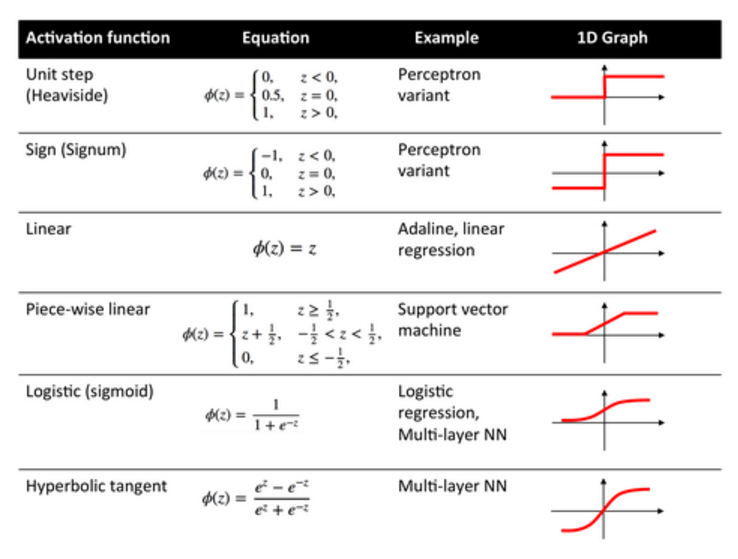
常用的啟用函式如下:
相關推薦
神經網路中的activation function到底扮演什麼樣的角色
參考Quora 為python作者Sebastian Raschka的回答 要回答這個問題,首先從線性迴歸(Linear Regression)說起,然後過度到邏輯迴歸(Logistic Regression),最後,過度到神經網路(Neural Netwo
[深度學習] 神經網路中的啟用函式(Activation function)
20180930 在研究調整FCN模型的時候,對啟用函式做更深入地選擇,記錄學習內容 啟用函式(Activation Function),就是在人工神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。 線性啟用函式:最簡單的linear fun
為什麼神經網路中需要啟用函式(activation function)?
在看tensorflow的時候,發現書中程式碼提到,使用ReLU啟用函式完成去線性化為什麼需要啟用函式去線性化?查了一下quaro,覺得這個回答能看明白(順便問一句,截圖算不算引用??)---------------------------------------------
人工神經網路中的activation function的作用以及ReLu,tanh,sigmoid激勵函式的區別
Leaky ReLU函式 人們為了解決Dead ReLU Problem,提出了將ReLU的前半段設為而非0。另外一種直觀的想法是基於引數的方法,即Parametric ReLU:,其中可由back propagation學出來。理論上來講,Leaky ReLU有ReLU的所有優點,外加不會有Dead Re
神經網路中的啟用函式(activation function)-Sigmoid, ReLu, TanHyperbolic(tanh), softmax, softplus
不管是傳統的神經網路模型還是時下熱門的深度學習,我們都可以在其中看到啟用函式的影子。所謂啟用函式,就是在神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。常見的啟用函式包括Sigmoid、TanHyperbolic(tanh)、ReLu、 sof
深度學習——神經網路中的activation
A:如果不用啟用函式(其實相當於啟用函式是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函式,很容易驗證,無論你神經網路有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了。引入非線性函式作為啟用函式,這樣深層神經網路就有意義了(不再是輸
傳統神經網路中常用的regularization方法
1、basic choice (1)通過一定的方式來縮小權重 (2)通過一定的方式將部分權重置為0 (3)weight-elimination regulizer 2、Early Stoppping Early stopping方法可以控制VC dimension
神經網路中隱層數和隱層節點數問題的討論
神經網路中隱層數和隱層節點數問題的討論 一 隱層數 一般認為,增加隱層數可以降低網路誤差(也有文獻認為不一定能有效降低),提高精度,但也使網路複雜化,從而增加了網路的訓練時間和出現“過擬合”的傾向。一般來講應設
變形卷積核、可分離卷積?卷積神經網路中十大拍案叫絕的操作
大家還是去看原文好,作者的文章都不錯: https://zhuanlan.zhihu.com/p/28749411 https://www.zhihu.com/people/professor-ho/posts 一、卷積只能在同一組進行嗎?-- Group convo
2013-2018卷積神經網路中十個最重要的概念與創新
本文作者Professor ho,原文載於其知乎主頁 一、卷積只能在同一組進行嗎?– Group convolution Group convolution 分組卷積,最早在AlexNet中出現,由於當時的硬體資源有限,訓練AlexNet時卷積操作不能全部放在同一個GPU處理,因此作
神經網路中訓練資料集、驗證資料集和測試資料集的區別
whats the difference between train, validation and test set, in neural networks? Answer: The training and validation sets are used during t
神經網路中的非線性啟用函式
目錄 0. 前言 1. ReLU 整流線性單元 2. 絕對值整流線性單元 3. 滲漏整流線性單元 4. 引數化整流線性單元 5. maxout 單元 6. logistic sigmoid 單元
訓練神經網路中最基本的三個概念和區別:Epoch, Batch, Iteration
epoch:訓練時,所有訓練資料集都訓練過一次。 batch_size:在訓練集中選擇一組樣本用來更新權值。1個batch包含的樣本的數目,通常設為2的n次冪,常用的包括64,128,256。 網路較小時選用256,較大時選用64。 iteration:訓練時,1個batch訓練影象通過網路訓
神經網路中依賴於上下文的處理的連續學習
Continuous Learning of Context-dependent Processing in Neural Networks 作者: Guanxiong Zeng, Yang Chen, Bo Cui and Shan Yu 5 Oct 2018 今天下午陳陽師兄
神經網路中反向傳播演算法(BP)
神經網路中反向傳播演算法(BP) 本文只是對BP演算法中的一些內容進行一些解釋,所以並不是嚴格的推導,因為我在推導的過程中遇見很多東西,當時不知道為什麼要這樣,所以本文只是對BP演算法中一些東西做點自己的合理性解釋,也便於自己理解。 要想看懂本文,要懂什麼是神經網路,對前向傳播以
神經網路中sigmoid 與代價函式
1.從方差代價函式說起 代價函式經常用方差代價函式(即採用均方誤差MSE),比如對於一個神經元(單輸入單輸出,sigmoid函式),定義其代價函式為: 其中y是我們期望的輸出,a為神經元的實際輸出【 a=σ(z), where z=wx+b 】。 在訓練神經網路過程中,我們通過梯度下降演算
卷積神經網路中感受野的理解和計算
什麼是感受野 “感受野”的概念來源於生物神經科學,比如當我們的“感受器”,比如我們的手受到刺激之後,會將刺激傳輸至中樞神經,但是並不是一個神經元就能夠接受整個面板的刺激,因為面板面積大,一個神經元可想而知肯定接受不完,而且我們同時可以感受到身上面板在不同的地方,如手、腳,的不同的刺激,如
【2014.10】神經網路中的深度學習綜述
本綜述的主要內容包括: 神經網路中的深度學習簡介 神經網路中面向事件的啟用擴充套件表示法 信貸分配路徑(CAPs)的深度及其相關問題 深度學習的研究主題 有監督神經網路/來自無監督神經網路的幫助 FNN與RNN中用於強化學習RL
神經網路中的值為1的偏置項b到底是什麼?
https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408 前言 很多人不明白為什麼要在神經網路、邏輯迴歸中要在樣本X的最前面加一個1,使得 X=[x1,x2,…,xn] 變成 X=