
聊聊HDFS的許可權訪問控制
文章目錄
前言
我們都知道HDFS檔案系統的訪問控制由其內部目錄,檔案的許可權所控制,和Linux檔案系統一致。但是當出現HDFS和別的元件進行關聯使用時,我們是否還能做到預期的控制效果呢?比如Hive和HDFS的使用,Hive也有它自己獨立一套的使用者許可權體系。本文筆者來簡單聊聊HDFS的許可權訪問控制,我們不聊最簡單的情況,只聊那些在生產中實際可能會遇到的場景。
典型場景:許可權資訊不一致情況
檔案系統資訊在使用過程中是有可能出現新老資料檔案的許可權不一致問題,而此時訪問的使用者也可能是老使用者或者是全新的一個使用者。那麼這裡就有可能會出現許可權訪問的問題。舉個筆者在實際工作中遇到的一個問題:
在早期階段,涉及到資料開發的應用都用賬號data來跑,自然的,此賬號所建的檔案及目錄的owner都是data。但實際上它的真實使用者就是一個應用層面的專案賬號。用公共賬號看似方便了資料讀寫流程控制,但是它有許可權過大的風險,而且很容易發生越權操作行為。A使用者以data賬號身份操作執行了B使用者以data賬號寫出的資料檔案。因為都是data賬戶執行,操作不會被拒絕。
所以後續地,我們就會想到賬戶拆分,然實際使用者傳進來,然後建立其owner屬於自身的資料檔案目錄。那麼這個時候,就會出現,新老資料以及新老使用者共存的情況,如下所示:
old files: /user/data/A_files owner:data
new files: /user/A/A_files owner:A
當然我們說,拆分出來的使用者A訪問它自身新產生的資料是完全沒有問題。但是如果它想對歷史資料做寫動作時就會出現問題。
人工介入修改方案
這裡介紹一種不介入外部系統的方法來做許可權的相容性修正。大致思路如下:
獲取所有專案賬號和目錄的對映關係,然後對相應目錄更改owner屬性。而獲取專案賬號和目錄的關係可能就涉及到其它外部系統的元資料查詢動作了,比如Hive 的metastore。
外部許可權管理框架:Sentry和Ranger
對於上面提到的許可權資訊的不一致問題,有沒有更加系統的,完整的解決辦法呢?這裡筆者介紹2個業界流行的解決方案:Sentry和Ranger。
Sentry的外掛式許可權同步控制
這裡以HDFS和Hive的元資料許可權資訊同步統一為例。它的一個核心操作是在資料系統程式中載入入對應的plugin外掛程式,然後plugin程式來和Sentry Sever主程式做資訊互動。這個許可權資訊的同步過程,對於使用者來講是完全透明的。Sentry的架構如下,
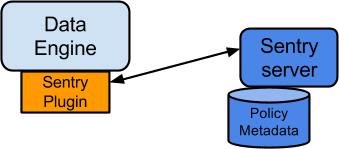
上面的DataEngine指的是具體的應用程序服務,如HDFS,Hive等等。
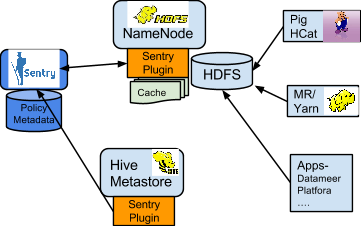
以HDFS和Hive之間的許可權同步為例,其過程如下圖所示:
Ranger的覆蓋式許可權訪問控制
相比於Sentry的許可權控制方式,另外一套體系Ranger採用的是一種優先覆蓋式的許可權訪問控制。還是以HDFS為例,首先一步,使用者需要完全覆蓋HDFS預設的那套ACL控制方法,然後載入入Ranger的相應類方法,也就是說更新下面類的值:
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value></value>
<description>
Name of class to use for delegating HDFS authorization.
</description>
</property>
然後後面所有的使用者對HDFS檔案的許可權檢測都會由對應的Ranger提供類內部來做,也就是我們提供的Ranger內部實現的提供類。而在這個載入類裡,Ranger為我們提供了靈活的策略控制,使用者可以自由配置訪問控制策略,然後外掛類會從持久化資訊中來拉取策略類。過程如下圖所示:
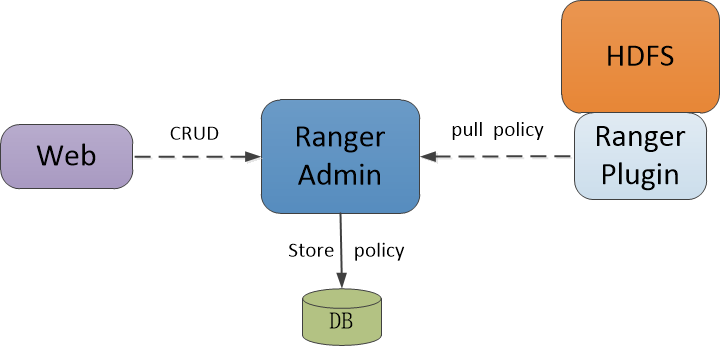
從這裡我們可以看出,2個框架的思路基本一致:通過載入額外定義的外掛程式來將系統預設的許可權訪問控制過程更新為自身系統定義的許可權訪問控制策略。
引用
[1].https://cwiki.apache.org/confluence/display/SENTRY/Sentry+Tutorial
[2].https://www.cnblogs.com/qiuyuesu/p/6774520.html