
第二章:單變數線性迴歸
阿新 • • 發佈:2019-01-12
目錄
單變數線性迴歸(Univariate linear regression)
介紹
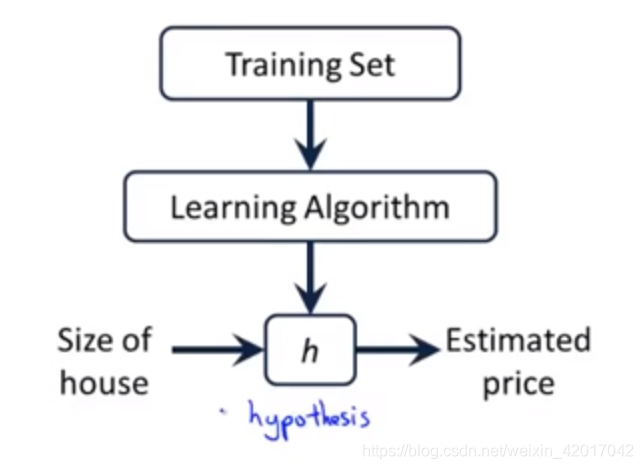
一個數據集也被稱為一個訓練集
- 資料集的表示
m :資料集樣本容量
(x,y) :一個樣本,x為輸入,y為輸出
:第i個樣本的輸入 , :第i個樣本的輸出 - 學習演算法的任務就是根據訓練集來輸出一個函式,這個函式能夠根據input來預測output
定義代價函式(平方誤差代價函式:square error cost function )
其中
為我們要求出的預測函式。
我們要做的事是求出 使得代價函式最小。 - ** 梯度下降法**( Gradient Descent)
給出一個函式 梯度下降法可以求得其取最小值時,引數 的值。- 過程(此處的梯度下降法為“Batch” Gradient Descent,每一步更新都會遍歷整個資料集,還有其他的梯度下降法)
repeat until convergence {
}
被稱為學習率(learning rate),它決定了梯度下降的速度 - 同時更新
- 梯度下降法單變數時的直觀解釋
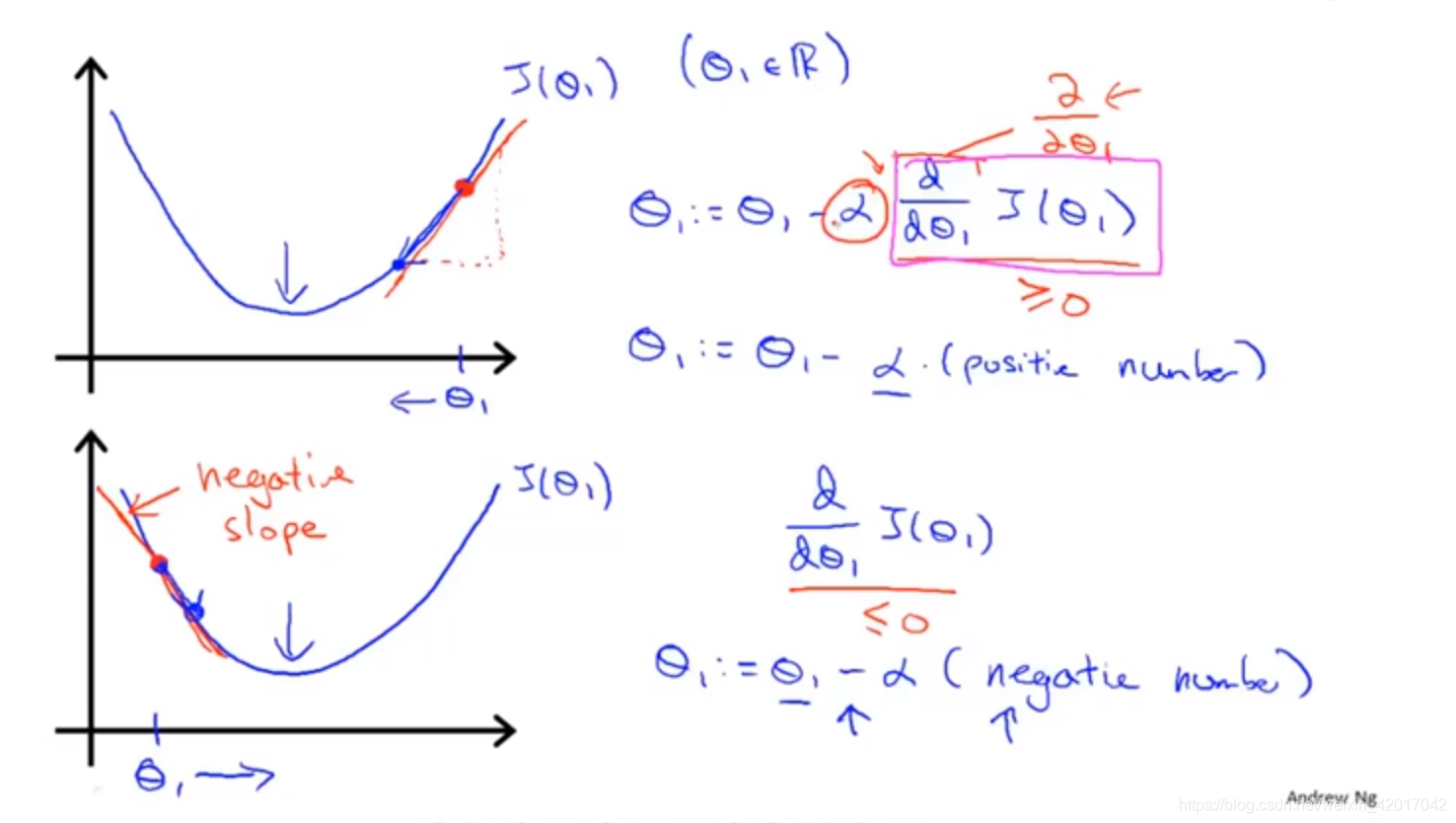
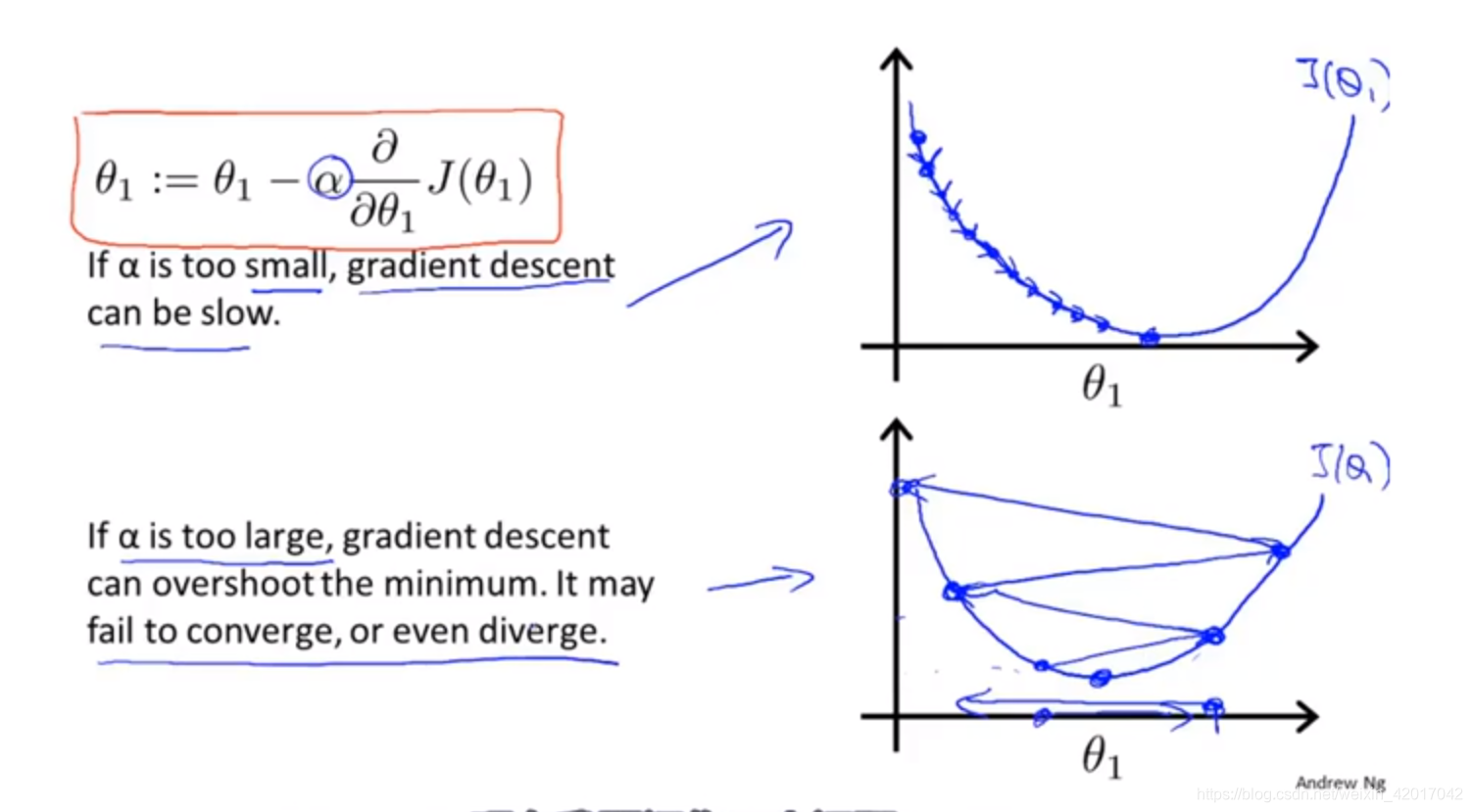
- 學習率
的直觀解釋
- 過程(此處的梯度下降法為“Batch” Gradient Descent,每一步更新都會遍歷整個資料集,還有其他的梯度下降法)
線性迴歸的梯度下降
根據公式,求偏導代入即可
