
前饋網路求導概論(一)·Softmax篇
Softmax是啥?
Hopfield網路的能量觀點
1982年的Hopfiled網路首次將統計物理學的能量觀點引入到神經網路中,
將神經網路的全域性最小值求解,近似認為是求解熱力學系統的能量最低點(最穩定點)。
為此,特地為神經網路定義了神經網路能量函式$E(x|Label)$,其中$x$為輸入。
$E(x|Label)=-\frac{1}{2}Wx \Delta Y \quad where \quad \Delta Y=y-label$ (省略Bias項)
值得注意的是,這套山寨牌能量函式只能求出區域性最小值,SVM用二次規劃函式替換掉之後才能求全域性最小值。
唯一的敗筆是,Hopfiled網路的輸出仍然採用了階躍函式Sign,走的還是Rosenblatt的老路子。
這個能量函式非常有趣,它在階躍函式狀態下永遠是遞減的,即便是W永遠是正的。(錯誤的隨機初始化也是OK的)。
原因如下:
I、當階躍函式輸出為1時,Wx為正,若產生Loss,$\Delta Y=1-(-1)=2$,顯然$\Delta YE(x|y)$為負。
II、當階躍函式輸出為-1時,Wx為負,若產生Loss,$\Delta Y=-1-(1)=-2$,顯然$\Delta YE(x|y)$還是為負。
III、若無LOSS,$\Delta Y=1-1$或$(-1)-(-1)$都為0,$\Delta E(x|y)$也為0。
概率與Boltzmann機
祖師爺Hinton在1985年創立了第一個隨機神經網路,首次將概率引入神經網路這個大玄學中。
值得一提的是,在當時概率圖模型也是被公認為玄學之一,很多研究者認為,信概率還不如信神經網路。(今天倒是反過來了)
Boltzmann機延續了Hopfiled能量函式的傳統,但是用一個奇葩的歸一化函式來產生概率,以取代相對不精確的階躍函式。
這個歸一化函式描述如下:
$P(y)=\frac{1}{1+e^{\frac{-(Wx+b)}{T}}}$
其中T為溫度係數,超引數之一,需要調參。
看起來怎麼那麼眼熟呢,扔掉T之後,這不就是Sigmoid函式麼。
可以看到,Boltzmann機為了表達概率,選用了Sigmoid函式作為神經網路的概率平滑產生器。
多變數概率與限制Boltzmann機
1986年由Smolensky創立的限制Boltzmann機將Hopfiled網路的輸出部折回,這樣就產生了多變數的輸出。
如何去表達此時多變數情況下的概率,能量模型—配分函式(Partition Function)解決了這一點:
$P(x)=\frac{e^{-E(x)}}{Z}=\frac{e^{-E(x)}}{\sum _{i}e^{-E(i)}}$
配分項Z是大家耳熟能詳的噁心之物,它的求解讓深度學習推遲了20年。
在深度學習被卡的20年間,配分項函式在多變數的判別模型中廣泛推廣,疑似是Softmax的雛形。
EBM(EnergyBased Model)
在LeCun的EBM教程Slides的介紹了配分判別函式,也就是今天的Softmax函式。
★The partition function ensures that undesired answers are given low probability
★For learning, we need to approximate the partition function (or its gradient with respect to the parameters)
順便將其批判了一番:
★Max likelihood learning gives high probability to good answers
★Problem: there are too many bad answers!
這部分的觀點可以參照PRML的序章關於貝葉斯擬合學習的討論,採用配分判別的Loss、基於極大似然的頻統方法
非常容易產生過擬合和弱泛化,貝葉斯學習和深度學習則引入先驗Prior在極大似然的統計基礎上做懲罰。
配分判別函式的定義如下:
$P(Y|X)=\frac{e^{-\beta}E(Y,X)}{\int_{y\in Y}e^{-\beta}E(y,X)}$
其中$\beta$為係數,扔掉之後就是Softmax函式。
SoftmaxLoss
$NLL = - \sum _{i}^{examples}\sum _{k}^{classes}l(y(i)=k)\cdot log[Softmax(X_{k}^{i})]$
不做過多介紹,見我的早期博文:Softmax迴歸
前向傳播求Loss的時候只要記住一點區別:
I、在Logistic迴歸中,對每個樣本,Loss-=$\log(1-Sigmoid)$或者Loss-=$\log(Sigmoid)$
II、在Softmax迴歸中,對每個樣本,Loss只減去對應Label的$\log(Softmax)$
比較I、II也可以看出來,Logistic迴歸的二選一隻是Softmax迴歸的N選一的特例。
泛型Softmax求導
儘管DeepLearning的基石是多樣本與平行計算,但是在泛型章節中不考慮多樣本情況。
求導描述將盡量與Caffe框架中的命名方式同步,以便於理解程式碼。
同時假定Softmax Axis上,命中Label的下標為k。
SoftmaxLoss
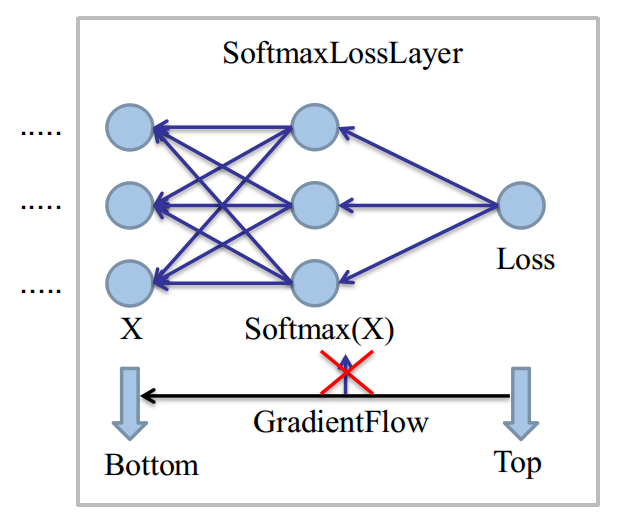
上圖是在當單樣本情況下,直接取Softmax Axis而畫的,現在我們假設這是一個N=3的分類問題。(0,1,2)
同時取Class=2作為當前樣本,命中的Label,即k=2。
由於Loss只和命中的分類有關,有:
$Softmax(X_{k})=\frac{e^{X_{k}}}{\sum _{i}e^{X_{i}}}$
則NLL (Negative-Log-Likelihood)為:
$NLL=-\log(Softmax(X_{k}))=-\log(\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}})\\ \quad \\ \qquad \qquad \qquad \qquad \qquad \qquad \; \; \,=\log(\sum _{i}e^{X_{i}})-log(e^{X_{k}}) \\ \quad \\ \qquad \qquad \qquad \qquad \qquad \qquad \; \; \, =\log(\sum _{i}e^{X_{i}})-X_{k}$
此時對於神經元$X_{k}$,有如下兩種求導方案:
I、 $BottomDiff(k)=\frac{\partial NLL}{\partial Softmax(X_{k})}\frac{\partial Softmax(X_{k})}{\partial X_{k}}$
II、 $BottomDiff(k)=\frac{\partial NLL}{\partial X_{k}}$
其中,第一種是沒有必要的,一般而言,Softmax的中間導數幾乎不會用到。
除非我們讓Softmax後面不接Loss,接其它的層,下一節會講這種特殊情況,求導相當複雜。
現在考慮更一般的神經元$X_{i}$,對NLL求導:
$\frac{\partial \log(\sum _{i}e^{X_{i}})-X_{k}}{\partial X_{i}}=\left\{\begin{matrix}\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}} - 1 \quad (i\neq k) \\ \\\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}} \quad (i=k)\\ \\0 \quad (if \;ignore\;i)\end{matrix}\right.$
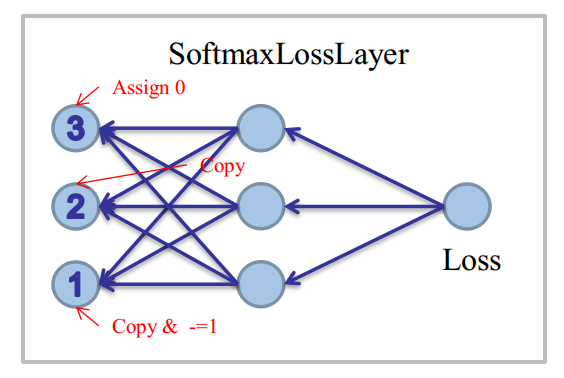
程式設計時:
對於①條件:先Copy一下Softmax的結果(即prob_data)到bottom_diff,再對k位置的unit減去1
對於②條件:直接Copy一下Softmax的結果(即prob_data)到bottom_diff
對於③條件:找到ignore位置的unit,強行置為0。
圖示如下:
Softmax
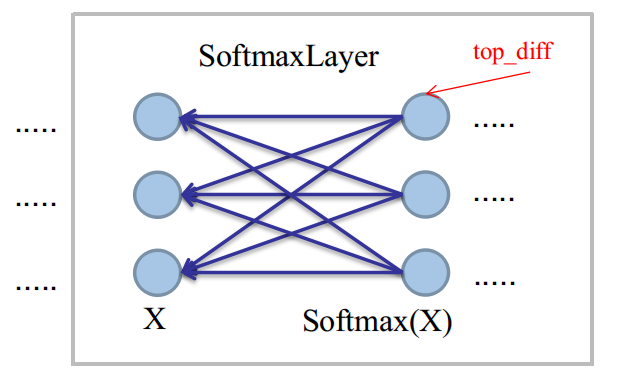
在SoftmaxLayer中,我們將會遇到最普遍的反向傳播任務:已知top_diff,求bottom_diff。
為了表述方便,設已知的top_diff的偏導表示式為:$\frac{\partial l}{Softmax(X)}$,則:
$BottomDiff(i)=\sum _{j}\frac{\partial l}{\partial Softmax(X_{j})}\frac{\partial Softmax(X_{j})}{\partial X_{i}}$
這是單獨對Softmax求導的最麻煩之處,由於全連線性,輸入神經元$X_{i}$將被全部的輸出神經元汙染。
更一般的,我們將其寫成:
$BottomDiff(i)=\frac{\partial l}{\partial Softmax(X)}\frac{\partial Softmax(X)}{\partial X_{i}}$。
考慮$\frac{\partial Softmax(X_{j})}{\partial X_{i}}$,有:
$\frac{\partial Softmax(X_{j})}{\partial X_{i}}=\left\{\begin{matrix}-Softmax(X_{j})*Softmax(X_{i})+Softmax(X_{i}) \quad i=j\\ \\ -Softmax(X_{j})*Softmax(X_{i}) \quad i\neq j\end{matrix}\right.$
聯合兩部分後,有:
$\sum \left\{\begin{matrix}-Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}*Softmax(X_{i})+Softmax(X_{i})*\frac{\partial l}{\partial Softmax(X_{j})} \quad i=j\\ \\ -Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}*Softmax(X_{i}) \quad i\neq j\end{matrix}\right.$
提取公共項部分:
$BottomDiff(i)=Softmax(X_{i})\left \langle \sum {j}\left \{-Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}\right \}+\frac{\partial l}{\partial Softmax(X_{i}) })\right \rangle\\ \quad \\ \qquad \qquad \qquad \; \; \; =TopData(i)\left \langle - \sum {j}\left \{TopData(j)*TopDiff(j)\right \}+TopDiff(i) \right \rangle\\ \quad \\ \qquad \qquad \qquad \; \; \; =TopData(i)\left \langle - \left \{TopData \bullet TopDiff \right \} +TopDiff(i) \right \rangle$
Caffe中做了以下兩點額外的優化:
I、由於對所有$X_{i}$,都要計算相同的點積項$\sum {j}\left \{TopData(j)*TopDiff(j)\right \}$,
一個簡單優化是用GEMM做一次矩陣廣播,這樣,對每個樣本的Softmax Axis軸上的多個單元,只需點積一次。
II、由於top_data與bottom_diff的shape相同,最外層top_data可基於全樣本來乘,這在CUDA環境中,可以有效提升瞬時並行度。
空間Softmax求導
Fully Convolutional Networks for Semantic Segmentation
Caffe中將二軸Softmax(Batchsize/Softmax)擴充套件到了nD軸Softmax,用於全卷積網路。
這部分程式碼由此paper兩位作者Jonathan Long&Evan Shelhamer加入,Github的History如下:

空間Soffmax是為了Dense Pixel Prediction(密集點預測)而生的,對於一張300x500的輸入影象,
一次Softmax將產生300*500=15W個Loss,這屬於神經網路——畫素級理解,是目前最難的CV任務。
空間Softmax取消了Softmax前的InnerProduct做的Flatten,因為必須保證空間軸資訊。
一個語義分割的圖示如下:

GroundTruth、Outer_Num、Inner_Num
傳統機器學習中的樣本單數值Label,在ComputerVision中擴充套件為多數值Label後,即變成GroundTruth。
Caffe中採用以下格式來規範儲存與讀取:
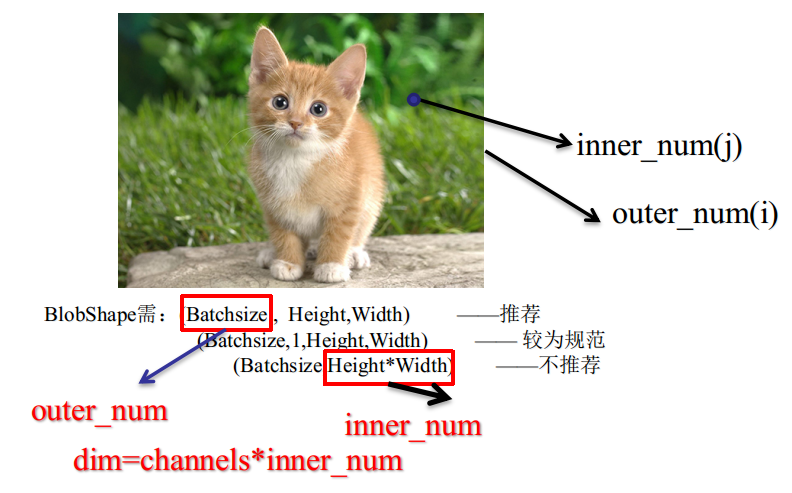
對於GroundTruth的$outer:inner=(i,j)$位置,即第$i$個樣本,空間$j$位置的Label,對應的Softmax向量如下:
$PixelExample=\left\{\begin{matrix}BottomData/BottomDiff(i*dim+0*inner+j) \quad class=0 \\
\quad \\ BottomData/BottomDiff(i*dim+1*inner+j) \quad class=1\\ \\ BottomData/BottomDiff(i*dim+2*inner+j) \quad class=2\\ \\...... \\ \\ BottomData/BottomDiff(i*dim+c*inner+j) \quad class=c\end{matrix}\right.$
這樣,對於outer_num數量的輸入影象,就變成了outer_num*inner_num個畫素樣本。
值得注意的是,目前最新的研究表明,在畫素級的理解中,batch_size大於1是沒有意義的,會嚴重減慢收斂速度。
輸入單張影象時,SGD做密集點預測,不會導致偏離最終的區域性最值點,因為15W的Loss近似可以看成batch_size=15,0000
空間Softmax(without GroundTruth)
從上節可知,空間軸(e.g. Height/Width)的引入,可看成是倍化了batch_size軸。
故在SoftmaxLayer中,對單樣本影象的輸入,需要多引入一次迴圈模擬多樣本,迴圈量即inner_num。
對於泛型Softmax中的點積運算,由計算單點積值,需要變化至求一組$TopData \bullet TopDiff$:
同樣設$outer:inner=(i,j)$,那麼$j$位置的兩組點積向量分別如下:
$\bullet \left\{\begin{matrix}TopData/TopDiff(i*dim+0*inner+j) \quad class=0\\ \\ .........\\ \\ TopData/TopDiff(i*dim+c*inner+j) \quad class=c\\ \end{matrix}\right.$
由於點積的元素每次都要跳躍inner_num個位置,可利用BLAS庫做StridedDot運算,點積增量設為inner_num即可。
I、在GEMM矩陣廣播優化中,原來只需要將單點積值廣播成[classes,1]的矩陣,順次在Softmax-Axis軸上減去,即:
從$TopDiff(i*dim)$的一段減去,由於無空間軸時,dim=classes,TopDiff的shape為[batch_size,classes],
矩陣的值恰好填充到下一樣本的開頭。
擴充套件空間軸時,則需要減去[classes,inner_num]個值,注意由於此時的shape為[batch_size,classes,inner_num],
如果你要線性覆蓋,則需要先覆蓋class=0的inner_num個值,所以一定要保證廣播矩陣的shape為[classes,inner_num]。
然後再做一次向量減法。由於BLAS的GEMM運算支援$C=\beta C+\alpha AB $,可一步完成。
II、在最外圍的top_data乘算中,由於top_data與bottom_diff的shape相同,擴充套件空間軸無需調整程式碼。
相關推薦
前饋網路求導概論(一)·Softmax篇
Softmax是啥? Hopfield網路的能量觀點 1982年的Hopfiled網路首次將統計物理學的能量觀點引入到神經網路中, 將神經網路的全域性最小值求解,近似認為是求解熱力學系統的能量最低點(最穩定點)。 為此,特地為神經網路定義了神經網路能量函式$E(x|Label)$,其中$x$為輸入。
深度學習一:深度前饋網路
# 簡述 - **深度前饋網路(deep feedforward network)**, 又叫**前饋神經網路(feedforward neural network)**和**多層感知機(multilayer perceptron, MLP)** . - 深度前饋網路之所以被稱為**網路**(networ
深度學習基礎--前饋模型/前饋網路
前饋模型/前饋網路 所謂的前饋是相對於迴圈模型而言的一種分類! 前饋模型的優點 迴圈模型似乎是比前饋模型更靈活、更具表現力的模型,畢竟,前饋網路提出了強條件獨立性假設,而迴圈模型並沒有加上這樣的限制。不過即使前饋模型的表現力較差,仍有幾個原因使得研究者可能更傾向於使用前饋
deep learning:深度前饋網路
深度學習是監督學習的一個分支。 簡單來說就是當線性模型無法解決問題時,引入的一種方法。 它綜合多種線行模型來從x空間——>學習到h空間,h空間為可用線行模型解決的空間 深度前饋網路(deep feedforward network)又叫多層感知機,是深度學習最典型的模型。 引入
機器學習 --- 深度前饋網路
對於某些問題,其特徵的表述極其困難,比如人臉的識別,其影響因素可能涉及到角度,光影,顏色,形狀等。深度學習旨在將原複雜的對映關係分解成一系列巢狀的簡單對映。 一、深度前饋網路簡要 深度前饋網路又稱多層感知機(MLP),對於分類器,函式 將輸入
【Ian Goodfellow課件】深度前饋網路
本課件主要內容包括: 路線圖 XOR問題不是線性可分的 線性整流的啟用函式 網路示意圖 求解XOR問題 基於梯度的學習 條件分佈與交叉熵 混合密度輸出 隱藏單元 組成結構基礎 泛
深度學習花書學習筆記 第六章 深度前饋網路
深度前饋網路又稱多層感知機、前饋神經網路。即只有從x向y方向的傳播,最終輸出y。 主要包括輸入層、隱藏層和輸出層。神經網路的模型可以解決非線性問題。 計算網路的引數通過反向傳播;如果每一層隱藏層都只有wx+b的運算,則多層累加變為w1*(w2*(w3*x))+a = W*
神經網路求導
本篇本來是想寫神經網路反向傳播演算法,但感覺光寫這個不是很完整,所以就在前面將相關的求導內容一併補上。所謂的神經網路求導,核心是損失函式對線性輸出 \(\mathbf{z} \;\; (\mathbf{z} = \mathbf{Wa} + \mathbf{b})\) 求導,即反向傳播中的 \(\delta =
TensorFlow入門(二)簡單前饋網路實現 mnist 分類
歡迎轉載,但請務必註明原文出處及作者資訊。 兩層FC層做分類:MNIST 在本教程中,我們來實現一個非常簡單的兩層全連線網路來完成MNIST資料的分類問題。 輸入[-1,28*28],
《Deep Learning》譯文 第六章 深度前饋網路 從異或函式說起
6.1 從異或函式說起 為了使前饋網路的概念更具體化,我們先從一個簡單地例子說起,這個例子中,我們使用前饋網路解決一個簡單的任務:學習異或函式。 眾所周知,異或(XOR)操作是一種針對二進位制值的二目操作符。當兩個運算元不同
AI聖經-深度學習-讀書筆記(六)-深度前饋網路
深度前饋網路(DFN) 0 簡介 (1)DFN:深度前饋網路,或前饋神經網路(FFN),或多層感知機(MLP) (2)目標 近似某個函式 f∗f∗。例如,定義一個對映y=f(x;θ)y=f(x;θ),並且學習θθ的值,使它能夠得到最佳的函式近似。
TensorFlow入門 簡單前饋網路實現 mnist 分類
import tensorflow as tf # 設定按需使用GPU config = tf.ConfigProto() config.gpu_options.allow_growth = True sess = tf.InteractiveSession(config=
矩陣求導(一)
矩陣求導術(上) 矩陣求導的技術,在統計學、控制論、機器學習等領域有廣泛的應用。鑑於我看過的一些資料或言之不詳、或繁亂無緒,本文來做個科普,分作兩篇,上篇講標量對矩陣的求導術,下篇講矩陣對矩陣的求導術。本文使用小寫字母x表示標量,粗體小寫字母x 表示向量,
《deep learning》學習筆記(6)——深度前饋網路
6.1 例項:學習 XOR 通過學習一個表示來解決 XOR 問題。圖上的粗體數字標明瞭學得的函式必須在每個點輸出的值。(左) 直接應用於原始輸入的線性模型不能實現 XOR 函式。當 x 1 = 0 時,模型的輸出必須隨著 x 2 的增大而增大。當 x
卷積神經網路系列之softmax loss對輸入的求導推導
我們知道卷積神經網路(CNN)在影象領域的應用已經非常廣泛了,一般一個CNN網路主要包含卷積層,池化層(pooling),全連線層,損失層等。雖然現在已經開源了很多深度學習框架(比如MxNet,Caffe等),訓練一個模型變得非常簡單,但是你對損失函式求梯度是怎
神經網路softmax啟用函式的求導過程
在使用softmax函式作為輸出層啟用函式的神經網路中,進行反向傳播時需要計算損耗函式相對於Z的導數,即 。網上有很多公式推導,但都太“數學”化了,看著比較抽象。所以總結下自己理解的比較簡單的推導過程。 首先,為了直觀理解,我們假設Z為一個3x1的向量,通過soft max
深度學習基礎--不同網路種類--前饋深度網路(feed-forwarddeep networks, FFDN)
深度神經網路可以分為3類: 1)前饋深度網路(feed-forwarddeep networks, FFDN) 2)反饋深度網路(feed-back deep networks, FBDN) 3)雙向深度網路(bi-directionaldeep networks, BDDN
斯坦福CS231n assignment1:softmax損失函式求導
斯坦福CS231n assignment1:softmax損失函式求導 在前文斯坦福CS231n assignment1:SVM影象分類原理及實現中我們講解了利用SVM模型進行影象分類的方法,本文我們講解影象分類的另一種實現,利用softmax進行影象分類。
softmax交叉熵損失函式求導
softmax 函式 softmax(柔性最大值)函式,一般在神經網路中, softmax可以作為分類任務的輸出層。其實可以認為softmax輸出的是幾個類別選擇的概率,比如我有一個分類任務,要分為三個類,softmax函式可以根據它們相對的大小,輸出三個類別選取的概率