
caffe練習例項(4)——caffe實現caltech101資料集影象分類
caltech101(101類影象資料庫)資料集
資料集地址: http://www.vision.caltech.edu/Image_Datasets/Caltech101/Caltech101.html
然後點選Download 點選下載: 101_ObjectCategories.tar.gz (131Mbytes)如下圖1、圖2所示
圖1

圖2
2.將下載的tar.gz檔案上傳到 caffe/data目錄下執行命令:tar -xzvf file.tar.gz 解壓縮
caffe資料集的建立需要兩個檔案: train.txt 和 val.txt, 格式為 圖片路徑+類別編號
這裡用用執行gettxt.py自動生成train.txt和val.txt,gettxt.py的程式碼如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
root = os.getcwd() #獲取當前路徑
data = '101_ObjectCategories' #101資料集的資料夾名稱
path = os.listdir(root+'/'+ data) #顯示該路徑下所有檔案
path.sort()
vp = 0.1 #測試集合取總資料前10%
ftr = open('train.txt','w')
fva = open('val.txt','w')
i = 0
for line in path:
subdir = root+'/'+ data +'/'+line
childpath = os.listdir(subdir)
mid = int(vp*len(childpath))
for child in childpath[:mid]:
subpath = data+'/'+line+'/'+child;
d = ' %s' %(i)
t = subpath + d
fva.write(t +'\n')
for child in childpath[mid:]:
subpath = data+'/'+line+'/'+child;
d = ' %s' %(i)
t = subpath + d
ftr.write(t +'\n')
i=i+1
ftr.close() #關閉檔案流
fva.close()
3.執行gettxt.py結果如下圖3

圖3
4.轉換成lmdb格式
mkdir calt101net # 在caffe/examples下建立一個新資料夾
將caffe/examples/imagenet下的create_imagenet.sh 複製到calt101net中
vim修改caffe/examples/calt101net下的create_imagenet.sh ,原先裡面內容如圖4所示,修改完成後如圖5所示
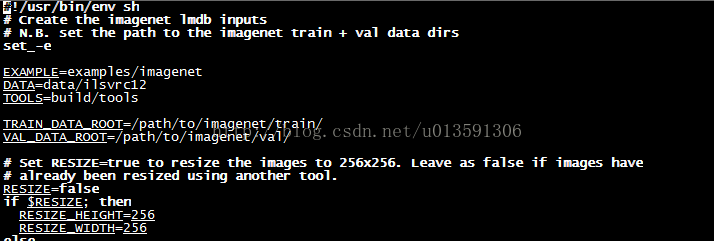

圖4
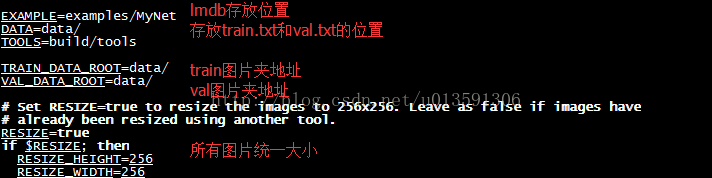
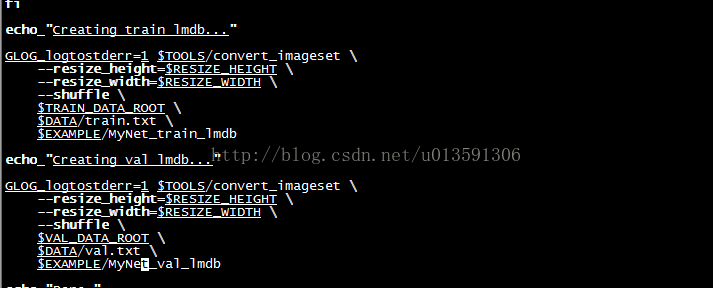
圖5
執行 ./examples/calt101net/create_imagenet.sh 生成lmdb檔案,執行結果如下圖6所示
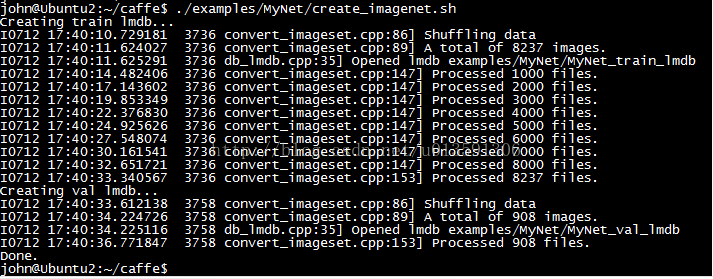
圖6
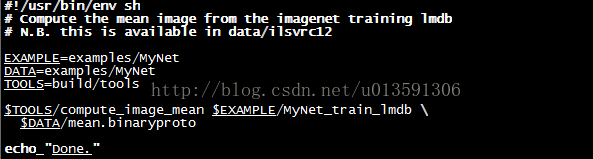
修改calt101net下的make_imagenet_mean.sh 並執行會根據lmdb檔案生成一個均值檔案

5.把caffe/models/bvlc_reference_caffenet/下的兩個檔案: solver.protoxt 和 train_val.protoxt[DAG網路]複製到calt101net中進行修改,首先修改examples/MyNet/train_caffenet.sh

然後修改solver.protoxt檔案內容

修改train_val.prototxt檔案內容,四項內容如下
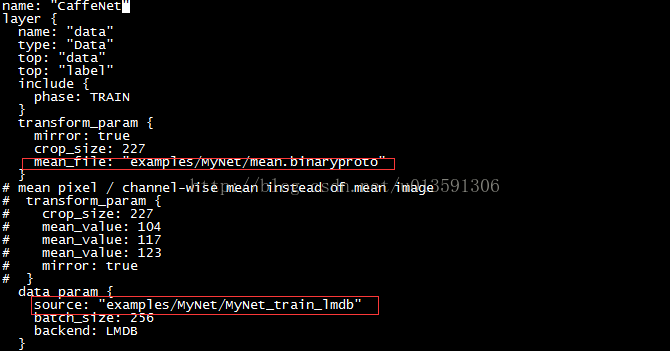
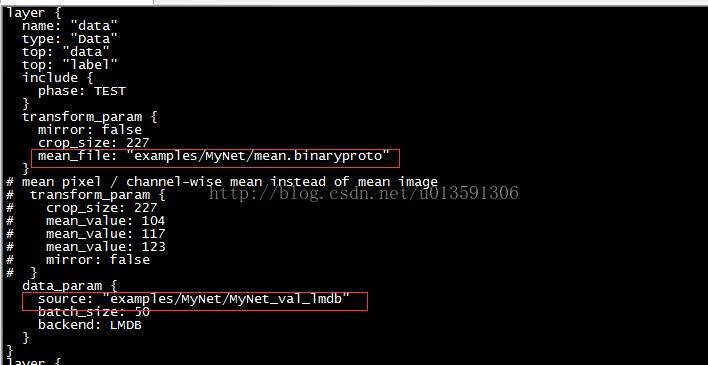
從0開始訓練和微調
./examples/MyNet/train_caffenet.sh