
超引數的選擇、格點搜尋與交叉驗證
超引數的選擇
1. 超引數有哪些
與超引數對應的是引數。引數是可以在模型中通過BP(反向傳播)進行更新學習的引數,例如各種權值矩陣,偏移量等等。超引數是需要進行程式設計師自己選擇的引數,無法學習獲得。
常見的超引數有模型(SVM,Softmax,Multi-layer Neural Network,…),迭代演算法(Adam,SGD,…),學習率(learning rate)(不同的迭代演算法還有各種不同的超引數,如beta1,beta2等等,但常見的做法是使用預設值,不進行調參),正則化方程的選擇(L0,L1,L2),正則化係數,dropout的概率等等。
2. 確定調節範圍
超引數的種類多,調節範圍大,需要先進行簡單的測試確定調參範圍。
2.1. 模型
模型的選擇很大程度上取決於具體的實際問題,但必須通過幾項基本測試。
首先,模型必須可以正常執行,即程式碼編寫正確。可以通過第一個epoch的loss估計,即估算第一個epoch的loss,並與實際結果比較。注意此過程需要設定正則項係數為0,因為正則項引入的loss難以估算。
其次,模型必須可以對於小資料集過擬合,即得到loss接近於0,accuracy接近於1的模型。否則應該嘗試其他或者更復雜的模型。
最後,如果val_acc與acc相差很小,可能是因為模型複雜度不夠,需要嘗試更為複雜的模型。
2.2. 學習率
loss基本不變:學習率過低
loss震動明顯或者溢位:學習率過高
根據以上兩條原則,可以得到學習率的大致範圍。
2.3. 正則項係數
val_acc與acc相差較大:正則項係數過小
loss逐漸增大:正則項係數過大
根據以上兩條原則,可以得到正則項係數的大致範圍。
3. 交叉驗證
對於訓練集再次進行切分,得到訓練集以及驗證集。通過訓練集訓練得到的模型,在驗證集驗證,從而確定超引數。(選取在驗證集結果最好的超引數)
3.1. 先粗調,再細調
先通過數量少,間距大的粗調確定細調的大致範圍。然後在小範圍內部進行間距小,數量大的細調。
3.2. 嘗試在對數空間內進行調節
即在對數空間內部隨機生成測試引數,而不是在原空間生成,通常用於學習率以及正則項係數等的調節。出發點是該超引數的指數項對於模型的結果影響更顯著;而同階的資料之間即便原域相差較大,對於模型結果的影響反而不如不同階的資料差距大。
3.3. 隨機搜尋引數值,而不是格點搜尋
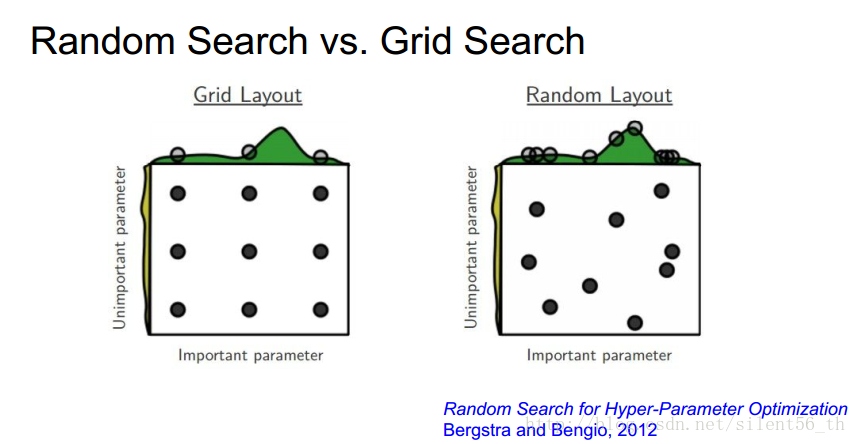
通過隨機搜尋,可以更好的發現趨勢。圖中所示的是通過隨機搜尋可以發現數據在某一維上的變化更加明顯,得到明顯的趨勢。
網格搜尋
網格搜尋(Grid Search)名字非常大氣,但是用簡答的話來說就是你手動的給出一個模型中你想要改動的所用的引數,程式自動的幫你使用窮舉法來將所用的引數都執行一遍。決策樹中我們常常將最大樹深作為需要調節的引數;AdaBoost中將弱分類器的數量作為需要調節的引數。
評分方法
為了確定搜尋引數,也就是手動設定的調節的變數的值中,那個是最好的,這時就需要使用一個比較理想的評分方式(這個評分方式是根據實際情況來確定的可能是accuracy、f1-score、f-beta、pricise、recall等)
交叉驗證
有了好的評分方式,但是只用一次的結果就能說明某組的引數組合比另外的引數組合好嗎?這顯然是不嚴謹的。所以就有了交叉驗證這一概念。下面以K折交叉驗證為例介紹這一概念。
綜合格點搜素與交叉驗證得到GridSearchCV
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
注意:scoring=None 預設為None, cv=None預設為None
| Parameters: |
estimator : estimator object.
param_grid : dict or list of dictionaries
scoring : string, callable, list/tuple, dict or None, default: None
fit_params : dict, optional
n_jobs : int, default=1
pre_dispatch : int, or string, optional
iid : boolean, default=True
cv : int, cross-validation generator or an iterable, optional
refit : boolean, or string, default=True
verbose : integer
error_score : ‘raise’ (default) or numeric
return_train_score : boolean, optional
|
||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attributes: |
cv_results_ : dict of numpy (masked) ndarrays
best_estimator_ : estimator or dict
best_score_ : float
best_params_ : dict
best_index_ : int
scorer_ : function or a dict
n_splits_ : int
|
這裡附上scoring對應的評分準則
Examples
>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import GridSearchCV
>>> iris = datasets.load_iris()
>>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
>>> svc = svm.SVC()
>>> clf = GridSearchCV(svc, parameters)
>>> clf.fit(iris.data, iris.target)
...
GridSearchCV(cv=None, error_score=...,
estimator=SVC(C=1.0, cache_size=..., class_weight=..., coef0=...,
decision_function_shape='ovr', degree=..., gamma=...,
kernel='rbf', max_iter=-1, probability=False,
random_state=None, shrinking=True, tol=...,
verbose=False),
fit_params=None, iid=..., n_jobs=1,
param_grid=..., pre_dispatch=..., refit=..., return_train_score=...,
scoring=..., verbose=...)
>>> sorted(clf.cv_results_.keys())
...
['mean_fit_time', 'mean_score_time', 'mean_test_score',...
'mean_train_score', 'param_C', 'param_kernel', 'params',...
'rank_test_score', 'split0_test_score',...
'split0_train_score', 'split1_test_score', 'split1_train_score',...
'split2_test_score', 'split2_train_score',...
'std_fit_time', 'std_score_time', 'std_test_score', 'std_train_score'...]相關推薦
超引數的選擇、格點搜尋與交叉驗證
超引數的選擇 1. 超引數有哪些 與超引數對應的是引數。引數是可以在模型中通過BP(反向傳播)進行更新學習的引數,例如各種權值矩陣,偏移量等等。超引數是需要進行程式設計師自己選擇的引數,無法學習獲得。 常見的超引數有模型(SVM,Softmax,Multi-lay
Python機器學習庫sklearn網格搜尋與交叉驗證
網格搜尋一般是針對引數進行尋優,交叉驗證是為了驗證訓練模型擬合程度。sklearn中的相關API如下: (1)交叉驗證的首要工作:切分資料集train/validation/test A.)沒指定資料切分方式,直接選用cross_val_scor
超引數的選擇與交叉驗證
1. 超引數有哪些 與超引數對應的是引數。引數是可以在模型中通過BP(反向傳播)進行更新學習的引數,例如各種權值矩陣,偏移量等等。超引數是需要進行程式設計師自己選擇的引數,無法學習獲得。 常見的超引數有模型(SVM,Softmax,Multi-layer Neural Network,…),迭代
改善深層神經網路:超引數除錯、正則化以及優化_課程筆記_第一、二、三週
所插入圖片仍然來源於吳恩達老師相關視訊課件。仍然記錄一下一些讓自己思考和關注的地方。 第一週 訓練集與正則化 這周的主要內容為如何配置訓練集、驗證集和測試集;如何處理偏差與方差;降低方差的方法(增加資料量、正則化:L2、dropout等);提升訓練速度的方法:歸一化訓練集;如何合理的初始化權
吳恩達改善深層神經網路引數:超引數除錯、正則化以及優化——優化演算法
機器學習的應用是一個高度依賴經驗的過程,伴隨著大量的迭代過程,你需要訓練大量的模型才能找到合適的那個,優化演算法能夠幫助你快速訓練模型。 難點:機器學習沒有在大資料發揮最大的作用,我們可以利用巨大的資料集來訓練網路,但是在大資料下訓練網路速度很慢; 使用快速的優化演算法大大提高效率
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二週
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二課 1. Mini-batch Batch vs Mini-batch gradient descent Batch就是將所有的訓練資料都放到網路裡面進行訓練,計算量大,硬體要求高。一次訓練只能得到一個梯
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 第一週
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 課程筆記 第一週 深度學習裡面的實用層面 1.1 測試集/訓練集/開發集 原始的機器學習裡面訓練集,測試集和開發集一般按照6:2:2的比例來進行劃分。但是傳統的機器學習
改善深層神經網路——超引數除錯、Batch正則化和程式框架(7)
目錄 1.超引數除錯 深度神經網路需要除錯的超引數(Hyperparameters)較多,包括: α:學習因子 β:動量梯度下降因子 :Adam演算法引數 #layers:神經網路層數
【scikit-learn】交叉驗證及其用於引數選擇、模型選擇、特徵選擇的例子
[0.95999999999999996, 0.95333333333333337, 0.96666666666666656, 0.96666666666666656, 0.96666666666666679, 0.96666666666666679, 0.96666666666666679, 0.9666
吳恩達《深度學習-改善深層神經網路》3--超引數除錯、正則化以及優化
1. 系統組織超參除錯Tuning process1)深度神經網路的超參有學習速率、層數、隱藏層單元數、mini-batch大小、學習速率衰減、β(優化演算法)等。其重要性各不相同,按重要性分類的話: 第一類:最重要的引數就是學習速率α 第二類:隱藏層單元數、min
《吳恩達深度學習工程師系列課程之——改善深層神經網路:超引數除錯、正則化以及優化》學習筆記
本課程分為三週內容: 深度學習的使用層面 優化演算法 超引數除錯、Batch正則化和程式框架 WEEK1 深度學習的使用層面 1.建立神經網路時選擇: 神經網路層數 每層隱藏單元的個數 學習率為多少 各層採用的啟用函式為哪些 2
deeplearning.ai第二課第三週:超引數除錯、BN層
1 超引數除錯 不同的超引數有不同的重要程度。比如,學習率一般最重要,momentum中的 β \beta
scikit-learn中交叉驗證及其用於引數選擇、模型選擇、特徵選擇的例子
內容概要 訓練集/測試集分割用於模型驗證的缺點 K折交叉驗證是如何克服之前的不足 交叉驗證如何用於選擇調節引數、選擇模型、選擇特徵 改善交叉驗證 1. 模型驗證回顧 進行模型驗證的一個重要目的是要選出一個最合適的模型,對於監督學習而言,我們希望模型
吳恩達deeplearning.ai課程《改善深層神經網路:超引數除錯、正則化以及優化》____學習筆記(第一週)
____tz_zs學習筆記第一週 深度學習的實用層面(Practical aspects of Deep Learning)我們將學習如何有效運作神經網路(超引數調優、如何構建資料以及如何確保優化演算法快速執行)設定ML應用(Setting up your ML applic
Coursera吳恩達《優化深度神經網路》課程筆記(3)-- 超引數除錯、Batch正則化和程式設計框架
上節課我們主要介紹了深度神經網路的優化演算法。包括對原始資料集進行分割,使用mini-batch gradient descent。然後介紹了指數加權平均(Exponentially weighted averages)的概念以及偏移校正(bias corr
第2次課改善深層神經網路:超引數優化、正則化以及優化
1. 除錯處理 超引數重要性排序 學習速率(learning rate)α 動量權重β=0.9,隱藏層節點數,mini-batch size 層數,learning rate decay Adam優化演算法的引數β1=0.9,β2=0.999,ϵ=10
吳恩達deep learning筆記第二課 改善深層神經網路:超引數除錯、正則化以及優化
學習吳恩達DL.ai第二週視訊筆記。 1.深度學習實用層面 在訓練集和驗證集來自相同分佈的前提下,觀察訓練集的錯誤率和驗證集的錯誤率來判斷過擬合(high variance高方差)還是欠擬合(high bias高偏差). 比如訓練集錯誤率1%,驗證集11%則過擬合(
C++整型、浮點型與字符串型相互轉換
小數位數 tde 參考 std str using atof char size 前言 整型、浮點型與字符串的相互轉換可以用自帶的函數來實現,本人使用的是vs2015,所以下面有些函數需要改變一下,請看下面的總結。 正文 一、整型轉字符串型 1. int轉為字符串
機器學習系列之偏差、方差與交叉驗證
一、偏差與方差 在機器學習中,我們用訓練資料集去訓練(學習)一個model(模型),通常的做法是定義一個Loss function(誤差函式),通過將這個Loss(或者叫error)的最小化過程,來提高模型的效能(performance)。然而我們學習一個模型的目的是為了解決實際的問題(或者說是
機器學習:驗證數據集與交叉驗證
問題: 很好 oss 時有 相對 循環 val 超參數 mage # 問題:如果將所有的數據集都作為訓練數據集,則對於訓練出的模型是否發生了過擬合會不自知,因為過擬合情況下,模型在訓練數據集上的誤差非常的小,使人覺得模型效果很好,但實際上可能泛化能力不足; # 方案:將