
人工智障學習筆記——機器學習(7)FM/FFM
一.概念
FM(分解機模型)和FFM(基於域的分解機模型)是最近幾年提出的模型,主要用於預估CTR/CVR,憑藉其在資料量比較大並且特徵稀疏的情況下,仍然能夠得到優秀的效能和效果的特性,屢次在各大公司舉辦的CTR預估比賽中獲得不錯的戰績。
二.原理
FM(Factorization Machine)是由Konstanz大學Steffen Rendle(現任職於Google)於2010年最早提出的,旨在解決稀疏資料下的特徵組合問題,相比SVM的二階多項式核而言,FM在樣本稀疏的情況下是有優勢的;而且,FM的訓練/預測複雜度是線性的,而二項多項式核SVM需要計算核矩陣,核矩陣複雜度就是N平方。
FFM(Field-aware Factorization Machine)最初的概念來自Yu-Chin Juan(阮毓欽,畢業於中國臺灣大學,現在美國Criteo工作)與其比賽隊員,是他們借鑑了來自Michael Jahrer的論文中的field概念提出了FM的升級版模型。通過引入field的概念,FFM把相同性質的特徵歸於同一個field
假設樣本的 n 個特徵屬於 f 個field,那麼FFM的二次項有 nf個隱向量。而在FM模型中,每一維特徵的隱向量只有一個。FM可以看作FFM的特例,是把所有特徵都歸屬到一個field時的FFM模型。根據FFM的field敏感特性,可以匯出其模型方程。

其中,fj 是第 j 個特徵所屬的field。如果隱向量的長度為 k,那麼FFM的二次引數有 nfk 個,遠多於FM模型的 nk 個。此外,由於隱向量與field相關,FFM二次項並不能夠化簡,其預測複雜度是 O(kn2)O(kn2)。
三.演算法
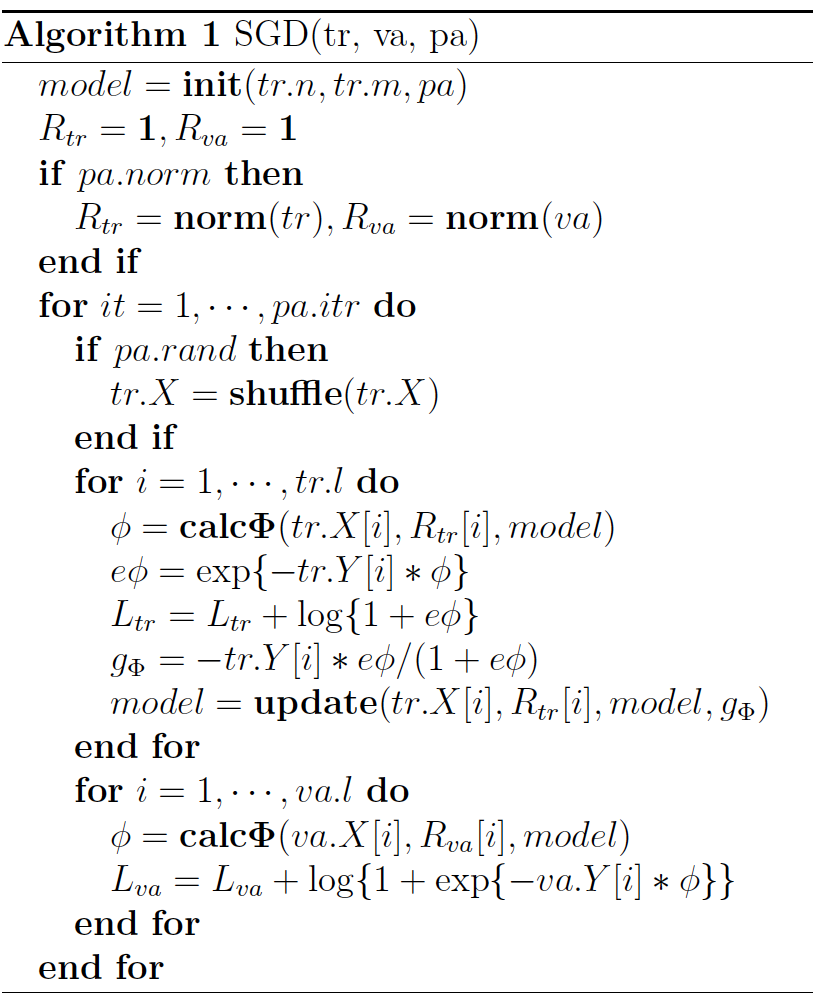
演算法程式碼:(原始碼見最後)
ffm_model ffm_train_on_disk(string tr_path, string va_path, ffm_parameter param) { problem_on_disk tr(tr_path); problem_on_disk va(va_path); ffm_model model = init_model(tr.meta.n, tr.meta.m, param); //cout << "ffm_train_on_disk:" << endl; //for (int i = 0; i < 10; i++) //{ // cout << "model.W[i] "<<i<<" "<<*(model.W+i) << endl; //} bool auto_stop = param.auto_stop && !va_path.empty(); ffm_long w_size = get_w_size(model); vector<ffm_float> prev_W(w_size, 0); if(auto_stop) prev_W.assign(w_size, 0); ffm_double best_va_loss = numeric_limits<ffm_double>::max(); cout.width(4); cout << "iter"; cout.width(13); cout << "tr_logloss"; if(!va_path.empty()) { cout.width(13); cout << "va_logloss"; } cout.width(13); cout << "tr_time"; cout << endl; Timer timer; auto one_epoch = [&] (problem_on_disk &prob, bool do_update) { ffm_double loss = 0; vector<ffm_int> outer_order(prob.meta.num_blocks); iota(outer_order.begin(), outer_order.end(), 0); random_shuffle(outer_order.begin(), outer_order.end()); for(auto blk : outer_order) { ffm_int l = prob.load_block(blk); vector<ffm_int> inner_order(l); iota(inner_order.begin(), inner_order.end(), 0); random_shuffle(inner_order.begin(), inner_order.end()); #if defined USEOMP #pragma omp parallel for schedule(static) reduction(+: loss) #endif for(ffm_int ii = 0; ii < l; ii++) { ffm_int i = inner_order[ii]; ffm_float y = prob.Y[i]; ffm_node *begin = &prob.X[prob.P[i]]; ffm_node *end = &prob.X[prob.P[i+1]]; ffm_float r = param.normalization? prob.R[i] : 1; ffm_double t = wTx(begin, end, r, model); ffm_double expnyt = exp(-y*t); loss += log1p(expnyt); //cout << ii <<"/"<< l <<" "<< i<<" " << y << " " << r ; //cout <<" " << t << " " << expnyt << endl; if(do_update) { ffm_float kappa = -y*expnyt/(1+expnyt); wTx(begin, end, r, model, kappa, param.eta, param.lambda, true); } } } return loss / prob.meta.l; }; //cout << "ffm_train_on_disk one_epoch" << endl; for(ffm_int iter = 1; iter <= param.nr_iters; iter++) { timer.tic(); ffm_double tr_loss = one_epoch(tr, true); timer.toc(); cout.width(4); cout << iter; cout.width(13); cout << fixed << setprecision(5) << tr_loss; if(!va.is_empty()) { ffm_double va_loss = one_epoch(va, false); cout.width(13); cout << fixed << setprecision(5) << va_loss; if(auto_stop) { if(va_loss > best_va_loss) { memcpy(model.W, prev_W.data(), w_size*sizeof(ffm_float)); cout.width(13); cout << fixed << setprecision(1) << timer.get() << endl; cout << endl << "Auto-stop. Use model at " << iter - 1 << "th iteration." << endl; break; } else { memcpy(prev_W.data(), model.W, w_size*sizeof(ffm_float)); best_va_loss = va_loss; } } } cout.width(13); cout << fixed << setprecision(1) << timer.get() << endl; } return model; }
其中wTx函式(非USESSE情況):
inline ffm_float wTx( ffm_node *begin, ffm_node *end, ffm_float r, ffm_model &model, ffm_float kappa=0, ffm_float eta=0, ffm_float lambda=0, bool do_update=false) { ffm_int align0 = 2 * get_k_aligned(model.k); ffm_int align1 = model.m * align0; ffm_float t = 0; for(ffm_node *N1 = begin; N1 != end; N1++) { //cout << "model.W "<<model.W << endl; ffm_int j1 = N1->j; ffm_int f1 = N1->f; ffm_float v1 = N1->v; if(j1 >= model.n || f1 >= model.m) continue; for(ffm_node *N2 = N1+1; N2 != end; N2++) { ffm_int j2 = N2->j; ffm_int f2 = N2->f; ffm_float v2 = N2->v; if(j2 >= model.n || f2 >= model.m) continue; ffm_float *w1 = model.W + (ffm_long)j1*align1 + f2*align0; ffm_float *w2 = model.W + (ffm_long)j2*align1 + f1*align0; ffm_float v = v1 * v2 * r; if(do_update) { ffm_float *wg1 = w1 + kALIGN; ffm_float *wg2 = w2 + kALIGN; for(ffm_int d = 0; d < align0; d += kALIGN * 2) { ffm_float g1 = lambda * w1[d] + kappa * w2[d] * v; ffm_float g2 = lambda * w2[d] + kappa * w1[d] * v; wg1[d] += g1 * g1; wg2[d] += g2 * g2; w1[d] -= eta / sqrt(wg1[d]) * g1; w2[d] -= eta / sqrt(wg2[d]) * g2; } } else { for(ffm_int d = 0; d < align0; d += kALIGN * 2) t += w1[d] * w2[d] * v; } } } return t; }
原始碼的一些問題:
問題1.ffm_node *end = &prob.X[prob.P[i+1]]下標越界問題
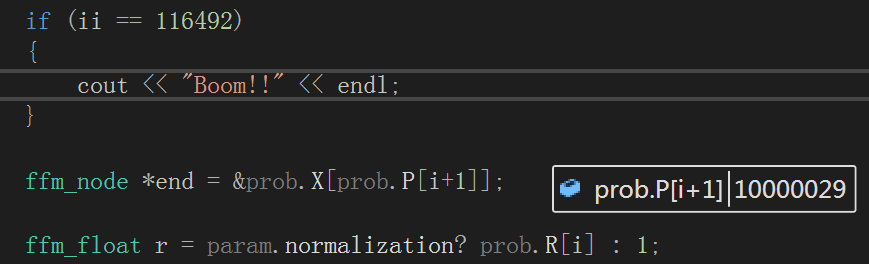

解決方法:
初始化時設定為(P[l]+1)
P.resize(l+1);
f.read(reinterpret_cast<char*>(P.data()), sizeof(ffm_long) * (l+1));
X.resize(P[l]+1);
f.read(reinterpret_cast<char*>(X.data()), sizeof(ffm_node) * (P[l]+1)); ffm_long nnz = P[l];
meta.l += l;
f_bin.write(reinterpret_cast<char*>(&l), sizeof(ffm_int));
f_bin.write(reinterpret_cast<char*>(Y.data()), sizeof(ffm_float) * l);
f_bin.write(reinterpret_cast<char*>(R.data()), sizeof(ffm_float) * l);
f_bin.write(reinterpret_cast<char*>(P.data()), sizeof(ffm_long) * (l+1));
f_bin.write(reinterpret_cast<char*>(X.data()), sizeof(ffm_node) * (nnz+1));問題2.ffm_model model = init_model(tr.meta.n, tr.meta.m, param);時model.K資料接不到
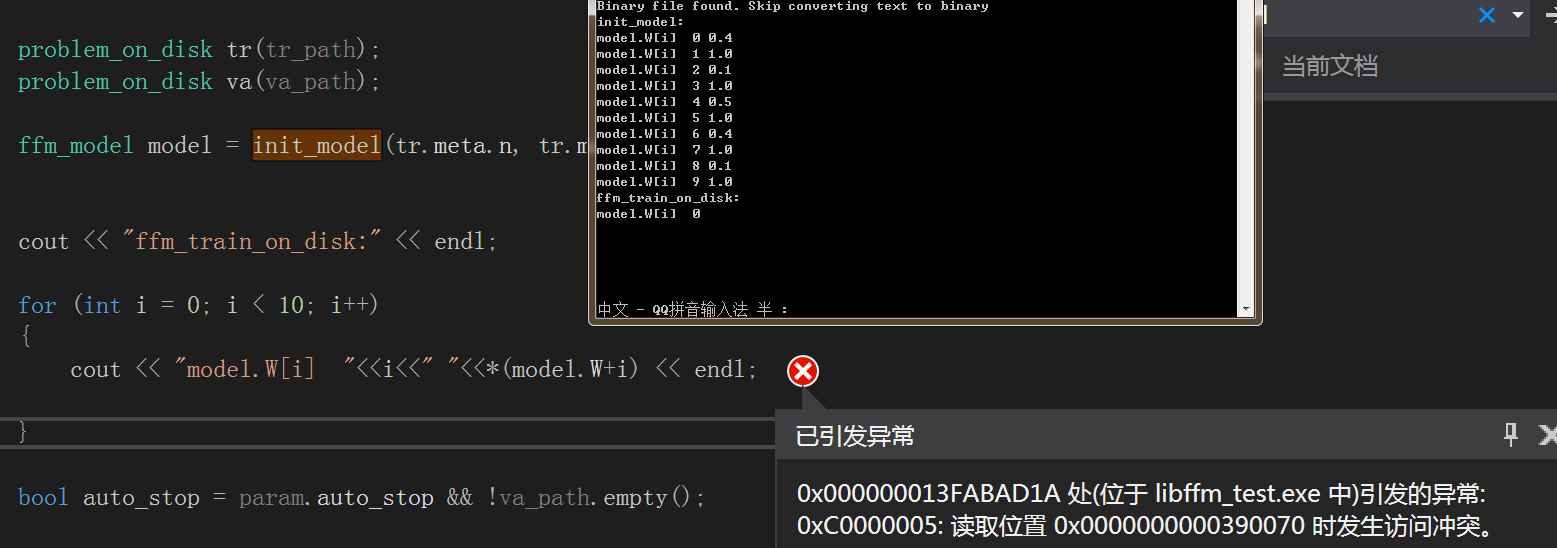
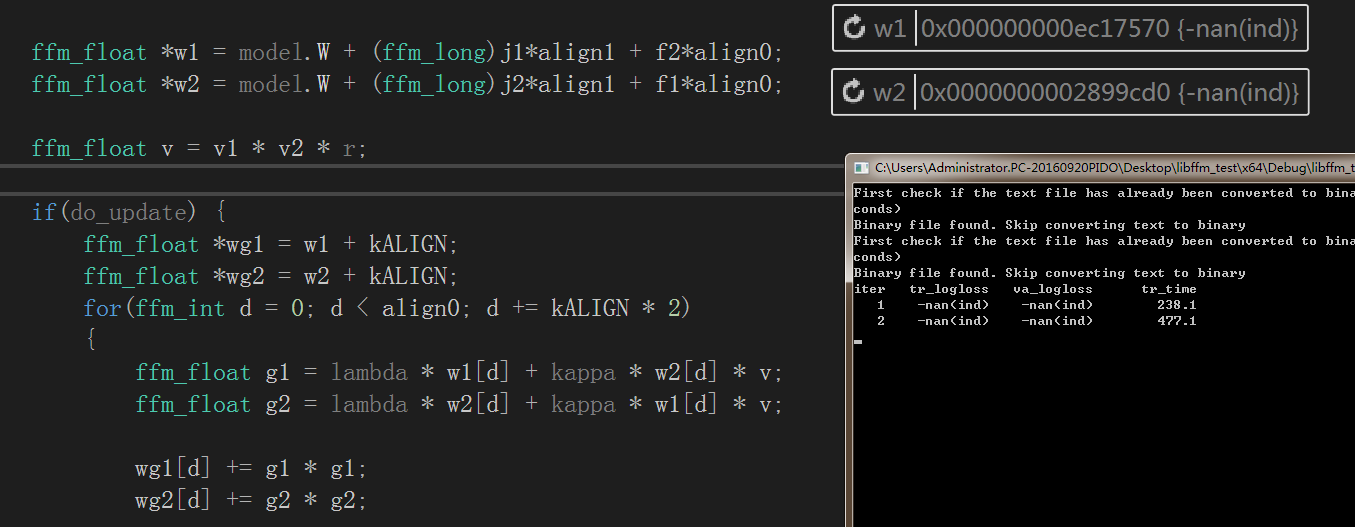
解決方法:
由於函式結束時解構函式會釋放該記憶體資料,只能先停用解構函式
struct ffm_model {
ffm_int n; // number of features
ffm_int m; // number of fields
ffm_int k; // number of latent factors
ffm_float *W = nullptr;
bool normalization;
//~ffm_model();
};/*
ffm_model::~ffm_model() {
if(W != nullptr) {
#ifndef USESSE
free(W);
#else
#ifdef _WIN32
_aligned_free(W);
#else
free(W);
#endif
#endif
W = nullptr;
}
}
*/train測試截圖
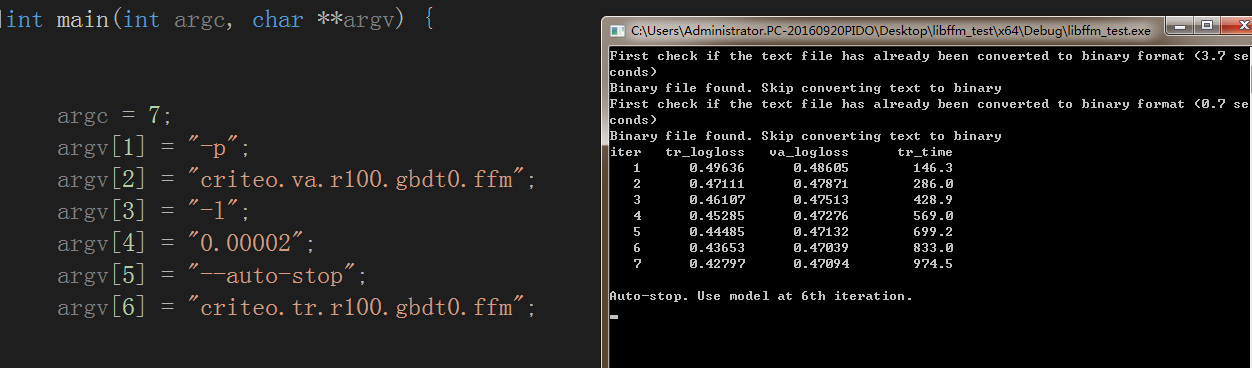
以及輸出model(二進位制檔案)
不過你們不要輕易開啟,看看大小就可以了。

四.總結
在DSP的場景中,FFM主要用來預估站內的CTR和CVR。在訓練FFM的過程中,有許多小細節值得特別關注。
第一,樣本歸一化。FFM預設是進行樣本資料的歸一化,即 pa.normpa.norm 為真;若此引數設定為假,很容易造成資料inf溢位,進而引起梯度計算的nan錯誤。因此,樣本層面的資料是推薦進行歸一化的。
第二,特徵歸一化。CTR/CVR模型採用了多種型別的源特徵,包括數值型和categorical型別等。但是,categorical類編碼後的特徵取值只有0或1,較大的數值型特徵會造成樣本歸一化後categorical類生成特徵的值非常小,沒有區分性。例如,一條使用者-商品記錄,使用者為“男”性,商品的銷量是5000個(假設其它特徵的值為零),那麼歸一化後特徵“sex=male”(性別為男)的值略小於0.0002,而“volume”(銷量)的值近似為1。特徵“sex=male”在這個樣本中的作用幾乎可以忽略不計,這是相當不合理的。因此,將源數值型特徵的值歸一化到
[0,1][0,1] 是非常必要的。
第三,省略零值特徵。從FFM模型的表示式(4)(4)可以看出,零值特徵對模型完全沒有貢獻。包含零值特徵的一次項和組合項均為零,對於訓練模型引數或者目標值預估是沒有作用的。因此,可以省去零值特徵,提高FFM模型訓練和預測的速度,這也是稀疏樣本採用FFM的顯著優勢。
五.相關學習資源
六.原始碼下載
注:提供了FFM-predict.cpp預測和FFM-train.cpp訓練兩個介面
相關推薦
人工智障學習筆記——機器學習(7)FM/FFM
一.概念 FM(分解機模型)和FFM(基於域的分解機模型)是最近幾年提出的模型,主要用於預估CTR/CVR,憑藉其在資料量比較大並且特徵稀疏的情況下,仍然能夠得到優秀的效能和效果的特性,屢次在各大公司舉辦的CTR預估比賽中獲得不錯的戰績。 二.原理 FM(Factoriz
人工智障學習筆記——機器學習(13)LLE降維
一.概念 LLE:Locally linear embedding(區域性線性嵌入演算法)是一種非線性降維演算法,它能夠使降維後的資料較好地保持原有流形結構。LLE可以說是流形學習方法最經典的工作之一。和傳統的PCA,LDA等關注樣本方差的降維方法相比,LLE關注於降維時保
人工智障學習筆記——機器學習(4)支援向量機
一.概念 支援向量機(Support Vector Machine),簡稱SVM。是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及迴歸分析。 SVM的主要思想可以概括為兩點: 1.它是針對線性可分情況進行分析,對於線性不可分的情況
人工智障學習筆記——機器學習(12)LDA降維
一.概念LDA:Linear Discriminant Analysis (也有叫做Fisher Linear Discriminant)。與PCA一樣,是一種線性降維演算法。不同於PCA只會選擇資料變化最大的方向,由於LDA是有監督的(分類標籤),所以LDA會主要以類別為
人工智障學習筆記——機器學習(11)PCA降維
一.概念 Principal Component Analysis(PCA):主成分分析法,是最常用的線性降維方法,它的目標是通過某種線性投影,將高維的資料對映到低維的空間中表示,即把原先的n個特徵用數目更少的m個特徵取代,新特徵是舊特徵的線性組合。並期望在所投影的維度上資
人工智障學習筆記——機器學習(15)t-SNE降維
一.概念 t-SNE(t分佈隨機鄰域嵌入)是一種用於探索高維資料的非線性降維演算法。它將多維資料對映到適合於人類觀察的兩個或多個維度。 t-SNE主要包括兩個步驟:第一、t-SNE構建一個高維物件之間的概率分佈,使得相似的物件有更高的概率被選擇,而不相似的物件有較低的概率被
【科普】不止於RPA,人工智能應用之——機器學習
什麽 一個人 index 廣泛 比喻 rom 服務 int 技術分享 藝賽旗RPA全面免費下載中點擊下載http://www.i-search.com.cn/index.html?from=line27 人工智能(Artificial Intelligence),英文縮寫為
機器學習基礎學習筆記——機器學習基礎介紹
機器學習基礎介紹 機器學習(Machine Learing,ML) 概念:多領域交叉學科,設計概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識
[學習筆記]機器學習——演算法及模型(五):貝葉斯演算法
傳統演算法(五) 貝葉斯演算法 一、貝葉斯定理 簡介 貝葉斯定理是18世紀英國數學家托馬斯·貝葉斯(Thomas Bayes)提出得重要概率論理論;貝葉斯方法源於他生前為解決一個“逆概”問題寫的一篇文章
學習筆記 | 機器學習-周志華 | 5
第二章 模型評估與選擇 2.1 經驗誤差與過擬合 "錯誤率" (error rate) ,即如果在 m 個樣本中有 α 個樣本分類錯誤,則錯誤率 E= α/m; 1 一 α/m 稱為**“精度” (accuracy)** ,即"精度 =1 - 錯誤率" 更一般地,
學習筆記 | 機器學習-周志華 | 4
習題 版本空間:存在著一個與訓練集一致的“假設集合”。 此時,只有1, 4兩個樣例。 求版本空間的步驟: ①寫出假設空間:先列出所有可能的樣本點(即特徵向量)(即每個屬性都取到所有的屬性值) ②對應著給出的已知資料集,將與正樣本不一致的、與負樣本一致的假設刪除。 ③得出與
學習筆記 | 機器學習-周志華 | 3
1.4 歸納偏好 版本空間中的多個假設可能會產生不同的輸出: 對於同一個樣本,產生不同結果。 這時,學習演算法本身的"偏好"就會起到關鍵的作用. 機器學習演算法在學習過程中對某種型別假設的偏好,稱為"歸納偏好" (inductive bias),或簡稱為"偏好"。 任何
學習筆記 | 機器學習-周志華 | 2
1.3 假設空間 歸納 (induction)與演繹 (deduction)是科學推理的兩大基本手段。 歸納:從特殊到一般的"泛化" (generalization)過程,即從具體的事實歸結出一般性規律。 演繹:從一般到特殊的"特化" (specializa
學習筆記 | 機器學習-周志華 | 1
第一章 緒論 機器學習所研究的主要內容,是關於在計算機上從資料中產生 模型(model) 的演算法,即 “學習演算法”(learning algorithm) . 基本術語 假定我們收集了一批關於西瓜的資料,例如(色澤=青綠;根蒂=蜷縮;敲聲=濁響), (色澤=烏黑;根蒂:稍蜷;
機器學習筆記——機器學習建議與誤差分析
建議 在實踐過程中我們經常會發現我們的建模不合適,那麼這種情況我們應該對我們模型的引數進行調整呢 評估假設 我們首先要做的就是對我們建立的模型進行評估,來判斷模型擬合是否合適。我們將利用訓練集求出來的網路引數θ應用在測試集上得到的誤差叫做測試集誤差,這個誤差越小代表建模越合適
Hands on Machine Learning with Sklearn and TensorFlow學習筆記——機器學習概覽
一、什麼是機器學習? 計算機程式利用經驗E(訓練資料)學習任務T(要做什麼,即目標),效能是P(效能指標),如果針對任務T的效能P隨著經驗E不斷增長,成為機器學習。【這是湯姆米切爾在1997年定義】 大白話:類比於學生學習考試,你先練習一套有一套的模擬卷 (這就相當於訓練資料),在這幾
R語言學習筆記-機器學習1-3章
在折騰完爬蟲還有一些感興趣的內容後,我最近在看用R語言進行簡單機器學習的知識,主要參考了《機器學習-實用案例解析》這本書。 這本書是目前市面少有的,純粹以R語言為基礎講解的機器學習知識,書中涉及11個案例。分12章。作者備註以及程式碼部分都講得比較深。不過或許因為出書較早,在資料處理方面,他使用更多的是pl
Tensorflow學習筆記:機器學習必備API
前一節介紹了一些最基本的概念和使用方法。因為我個人的最終目的還是在深度學習上,所以一些深度學習和機器學習模組是必須要了解的,這其中包括了tf.train 、tf.contrib.learn、還
學習筆記——機器學習--多項式分佈及Softmax迴歸模型推導
在一個多分類問題,預測變數y y可以取k k個離散值中的任何一個,即y∈{1,2,⋯,k} y∈{1,2,⋯,k}。 例如:在一個郵件分類系統將郵件分為私人郵件,工作郵件和垃圾郵件。由於y y仍然是一個離散值,這種多分類問題,二分類模型在這裡不太適用。
斯坦福大學機器學習筆記——機器學習系統設計(誤差分析、查全率和查準率、F1值)
這次部落格我們主要討論機器學習系統設計的主要問題,以及怎樣巧妙的構建一個複雜的機器學習系統。 我們先用一個例子引入機器學習系統的設計: 以一個垃圾郵件分類器演算法為例: 對於該問題,我們首先要做的是怎樣選擇並且表達特徵向量x。我們可以選擇100個詞所構