
R語言學習筆記-機器學習1-3章
在折騰完爬蟲還有一些感興趣的內容後,我最近在看用R語言進行簡單機器學習的知識,主要參考了《機器學習-實用案例解析》這本書。
這本書是目前市面少有的,純粹以R語言為基礎講解的機器學習知識,書中涉及11個案例。分12章。作者備註以及程式碼部分都講得比較深。不過或許因為出書較早,在資料處理方面,他使用更多的是plyr包,而我用下來,dplyr包效果更好。所以許多涉及資料處理的程式碼,其實可以用更簡潔的方法重寫。但是思路卻是實打實的精華。
我之前在某長途動車上啃完了前三章,兩個案例。但越往後讀,越覺得後面案例處理方法越複雜,更加晦澀了,需要更多時間消化,因此暫停下來,先把前兩個案例給理理順,消化一下結構點。
書中案例資料及程式碼均可在官方github中下載到,地址為https://github.com/johnmyleswhite/ML_for_Hackers
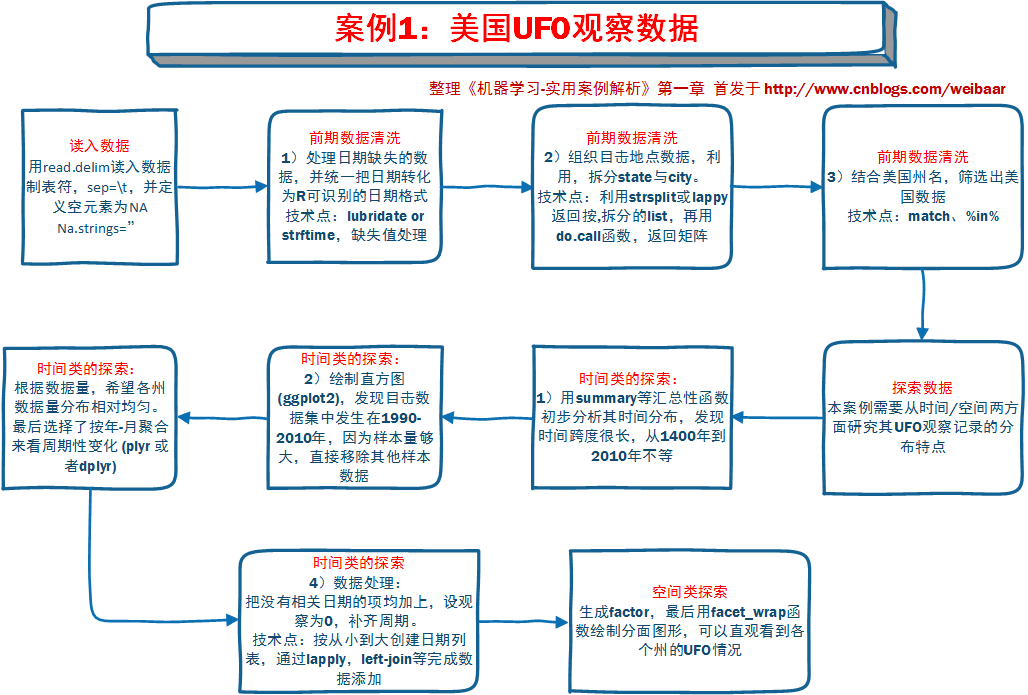
案例1:美國UFO觀察
該案例用的是一個含有60,000多條不明飛行物的目擊記錄和報告的資料集。需要回答UFO出現是否有周期性規律,以及地域規律兩個問題。主要涉及資料清洗環節。
在研讀後,我繪製的流程圖如下圖:
案例2:二分法判別垃圾郵件
該案例用的是來自於SpamAssasin的郵件,它分為垃圾郵件spam,易識別的正常郵件easy ham,不易識別的正常郵件hard ham三個型別。案例目的是做一個分類器,能夠通過詞頻特徵(如html等)快速識別郵件的型別。
使用的是樸素貝葉斯分類法。
繪製的流程圖及注意事項見下:

流程圖用visio 2013繪製。很喜歡它的手繪風流程圖,之前想嘗試一下其他流程圖軟體,比較下來,還是visio最好用啊……
接下來的本月目標
1)金融時間序列
2)機器學習4-7章
相關推薦
R語言學習筆記-機器學習1-3章
在折騰完爬蟲還有一些感興趣的內容後,我最近在看用R語言進行簡單機器學習的知識,主要參考了《機器學習-實用案例解析》這本書。 這本書是目前市面少有的,純粹以R語言為基礎講解的機器學習知識,書中涉及11個案例。分12章。作者備註以及程式碼部分都講得比較深。不過或許因為出書較早,在資料處理方面,他使用更多的是pl
學習筆記 | 機器學習-周志華 | 3
1.4 歸納偏好 版本空間中的多個假設可能會產生不同的輸出: 對於同一個樣本,產生不同結果。 這時,學習演算法本身的"偏好"就會起到關鍵的作用. 機器學習演算法在學習過程中對某種型別假設的偏好,稱為"歸納偏好" (inductive bias),或簡稱為"偏好"。 任何
學習筆記 | 機器學習-周志華 | 1
第一章 緒論 機器學習所研究的主要內容,是關於在計算機上從資料中產生 模型(model) 的演算法,即 “學習演算法”(learning algorithm) . 基本術語 假定我們收集了一批關於西瓜的資料,例如(色澤=青綠;根蒂=蜷縮;敲聲=濁響), (色澤=烏黑;根蒂:稍蜷;
【日常學習筆記】2019/1/3(Log4j與web安全)
Log4j日誌學習 log4j日誌輸出使用教程 https://www.cnblogs.com/sky230/p/5759831.html Spring+SpringMVC+MyBatis+easyUI整合優化篇(二)Log4j講解與整合 https://www.cnblogs.
機器學習基礎學習筆記——機器學習基礎介紹
機器學習基礎介紹 機器學習(Machine Learing,ML) 概念:多領域交叉學科,設計概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識
[學習筆記]機器學習——演算法及模型(五):貝葉斯演算法
傳統演算法(五) 貝葉斯演算法 一、貝葉斯定理 簡介 貝葉斯定理是18世紀英國數學家托馬斯·貝葉斯(Thomas Bayes)提出得重要概率論理論;貝葉斯方法源於他生前為解決一個“逆概”問題寫的一篇文章
學習筆記 | 機器學習-周志華 | 5
第二章 模型評估與選擇 2.1 經驗誤差與過擬合 "錯誤率" (error rate) ,即如果在 m 個樣本中有 α 個樣本分類錯誤,則錯誤率 E= α/m; 1 一 α/m 稱為**“精度” (accuracy)** ,即"精度 =1 - 錯誤率" 更一般地,
學習筆記 | 機器學習-周志華 | 4
習題 版本空間:存在著一個與訓練集一致的“假設集合”。 此時,只有1, 4兩個樣例。 求版本空間的步驟: ①寫出假設空間:先列出所有可能的樣本點(即特徵向量)(即每個屬性都取到所有的屬性值) ②對應著給出的已知資料集,將與正樣本不一致的、與負樣本一致的假設刪除。 ③得出與
學習筆記 | 機器學習-周志華 | 2
1.3 假設空間 歸納 (induction)與演繹 (deduction)是科學推理的兩大基本手段。 歸納:從特殊到一般的"泛化" (generalization)過程,即從具體的事實歸結出一般性規律。 演繹:從一般到特殊的"特化" (specializa
人工智障學習筆記——機器學習(13)LLE降維
一.概念 LLE:Locally linear embedding(區域性線性嵌入演算法)是一種非線性降維演算法,它能夠使降維後的資料較好地保持原有流形結構。LLE可以說是流形學習方法最經典的工作之一。和傳統的PCA,LDA等關注樣本方差的降維方法相比,LLE關注於降維時保
人工智障學習筆記——機器學習(4)支援向量機
一.概念 支援向量機(Support Vector Machine),簡稱SVM。是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及迴歸分析。 SVM的主要思想可以概括為兩點: 1.它是針對線性可分情況進行分析,對於線性不可分的情況
機器學習筆記——機器學習建議與誤差分析
建議 在實踐過程中我們經常會發現我們的建模不合適,那麼這種情況我們應該對我們模型的引數進行調整呢 評估假設 我們首先要做的就是對我們建立的模型進行評估,來判斷模型擬合是否合適。我們將利用訓練集求出來的網路引數θ應用在測試集上得到的誤差叫做測試集誤差,這個誤差越小代表建模越合適
人工智障學習筆記——機器學習(12)LDA降維
一.概念LDA:Linear Discriminant Analysis (也有叫做Fisher Linear Discriminant)。與PCA一樣,是一種線性降維演算法。不同於PCA只會選擇資料變化最大的方向,由於LDA是有監督的(分類標籤),所以LDA會主要以類別為
人工智障學習筆記——機器學習(11)PCA降維
一.概念 Principal Component Analysis(PCA):主成分分析法,是最常用的線性降維方法,它的目標是通過某種線性投影,將高維的資料對映到低維的空間中表示,即把原先的n個特徵用數目更少的m個特徵取代,新特徵是舊特徵的線性組合。並期望在所投影的維度上資
Hands on Machine Learning with Sklearn and TensorFlow學習筆記——機器學習概覽
一、什麼是機器學習? 計算機程式利用經驗E(訓練資料)學習任務T(要做什麼,即目標),效能是P(效能指標),如果針對任務T的效能P隨著經驗E不斷增長,成為機器學習。【這是湯姆米切爾在1997年定義】 大白話:類比於學生學習考試,你先練習一套有一套的模擬卷 (這就相當於訓練資料),在這幾
人工智障學習筆記——機器學習(7)FM/FFM
一.概念 FM(分解機模型)和FFM(基於域的分解機模型)是最近幾年提出的模型,主要用於預估CTR/CVR,憑藉其在資料量比較大並且特徵稀疏的情況下,仍然能夠得到優秀的效能和效果的特性,屢次在各大公司舉辦的CTR預估比賽中獲得不錯的戰績。 二.原理 FM(Factoriz
人工智障學習筆記——機器學習(15)t-SNE降維
一.概念 t-SNE(t分佈隨機鄰域嵌入)是一種用於探索高維資料的非線性降維演算法。它將多維資料對映到適合於人類觀察的兩個或多個維度。 t-SNE主要包括兩個步驟:第一、t-SNE構建一個高維物件之間的概率分佈,使得相似的物件有更高的概率被選擇,而不相似的物件有較低的概率被
Tensorflow學習筆記:機器學習必備API
前一節介紹了一些最基本的概念和使用方法。因為我個人的最終目的還是在深度學習上,所以一些深度學習和機器學習模組是必須要了解的,這其中包括了tf.train 、tf.contrib.learn、還
學習筆記——機器學習--多項式分佈及Softmax迴歸模型推導
在一個多分類問題,預測變數y y可以取k k個離散值中的任何一個,即y∈{1,2,⋯,k} y∈{1,2,⋯,k}。 例如:在一個郵件分類系統將郵件分為私人郵件,工作郵件和垃圾郵件。由於y y仍然是一個離散值,這種多分類問題,二分類模型在這裡不太適用。
斯坦福大學機器學習筆記——機器學習系統設計(誤差分析、查全率和查準率、F1值)
這次部落格我們主要討論機器學習系統設計的主要問題,以及怎樣巧妙的構建一個複雜的機器學習系統。 我們先用一個例子引入機器學習系統的設計: 以一個垃圾郵件分類器演算法為例: 對於該問題,我們首先要做的是怎樣選擇並且表達特徵向量x。我們可以選擇100個詞所構