
使用RNN進行影象分類
基礎介紹
如何使用RNN進行mnist的分類呢?其實對應到RNN裡面就是個Sequence Classification問題.
先看下CS231n中關於RNN部分的一張圖:
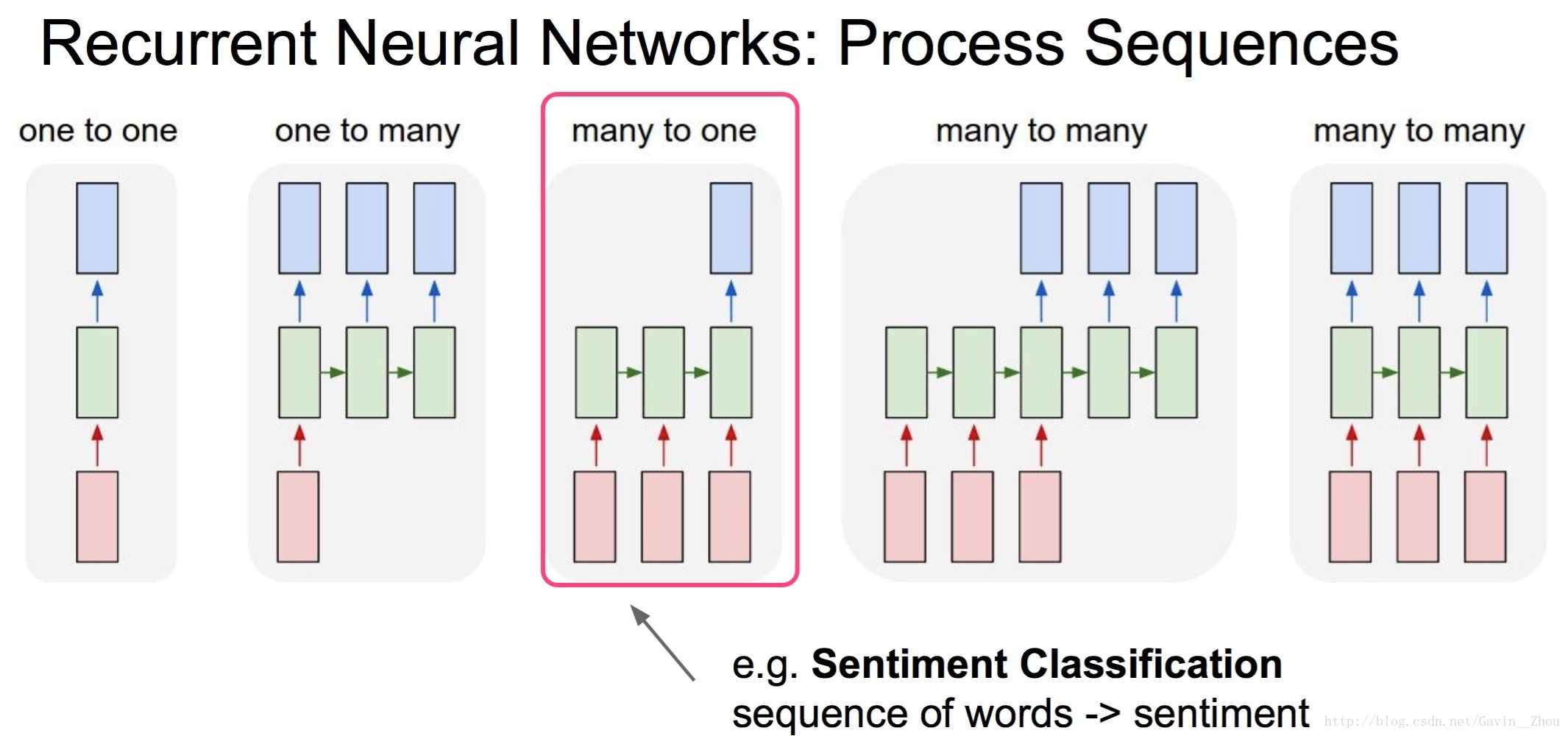
其實影象的分類對應上圖就是個many to one的問題. 對於mnist來說其影象的size是28*28,如果將其看成28個step,每個step的size是28的話,是不是剛好符合上圖. 當我們得到最終的輸出的時候將其做一次線性變換就可以加softmax來分類了,其實挺簡單的.
具體實現
對於常見的RNN cell的使用總結:

獲取資料
很簡單,tf自帶都幫我們寫好了,直接呼叫就行了.
import 如何不存在data/mnist這個目錄,其會自己下載mnist資料,要是你的網路不行也可以自己去mnist的網站下載然後將資料放在目錄下就可以了.
tf貼心到什麼程度呢?連batch generator都幫我們寫好了,直接用next_batch就可以獲得下一個batch的資料.
train_x, train_y = mnist_data.train.images, mnist_data.train.labels test_x, test_y = mnist_data.test.images, mnist_data.test.labels batch_x, batch_y = mnist.train.next_batch(batch_size)
training examples是55000, test examples是10000,validation examples是5000.
定義網路
我們使用3層的GRU,hidden units是200的帶dropout的RNN來作為mnist分類的網路,具體程式碼如下:
cells = list()
for _ in range(num_layers):
cell = tf.nn.rnn_cell.GRUCell(num_units=num_hidden)
cell = tf.nn.rnn_cell.DropoutWrapper(cell=cell, output_keep_prob=1.0 因為mnist太簡單,這個簡單的網路其實已經可以搞定mnist的分類問題,後期的test acc可以到0.985(within 3 epoches).
訓練和測試
分類嘛,還是使用cross entropy作為loss,然後計算下錯誤率是多少,程式碼如下:
batch_size = 64, lr = 0.001
# placeholders
input_x = tf.placeholder(tf.float32, shape=(None, 28, 28))
input_y = tf.placeholder(tf.float32, shape=(None, 10))
dropout = tf.placeholder(tf.float32)
input_logits = model(input_x, input_y, dropout)
# loss and error rate op
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=input_logits, labels=input_y))
train_op = tf.train.RMSPropOptimizer(0.001).minimize(loss)
input_prob = tf.nn.softmax(input_logits)
error_count = tf.not_equal(tf.arg_max(input_prob, 1), tf.arg_max(input_y, 1))
error_rate_op = tf.reduce_mean(tf.cast(error_count, tf.float32))input_x和input_y表示輸入的image和label,model就是上面定義的3層GRU模型;可以使用tf.summary來使用tensorboard檢視訓練時的error rate和loss等資訊.
訓練程式碼:
for step in range(total_steps):
train_x, train_y = mnist_data.train.next_batch(default_batch_size)
train_x = train_x.reshape(-1, 28, 28)
feed_dict = {input_x: train_x,
input_y: train_y,
dropout: default_dropout}
_, summary = session.run([train_op, merge_summary_op], feed_dict=feed_dict)
# write logs
summary_writer.add_summary(summary, global_step=epoch*total_steps+step)測試程式碼:
# test
if step > 0 and (step % test_freq == 0):
avg_error = 0
for test_step in range(total_test_steps):
test_x, test_y = mnist_data.test.next_batch(default_batch_size)
test_x = test_x.reshape(-1, 28, 28)
feed_dict = {input_x: test_x,
input_y: test_y,
dropout: 0}
test_error = session.run(error_rate_op, feed_dict=feed_dict)
avg_error += test_error / total_test_steps
print('epoch: %d, steps: %d, avg_test_error: %.4f' % (epoch, step, avg_error))結果
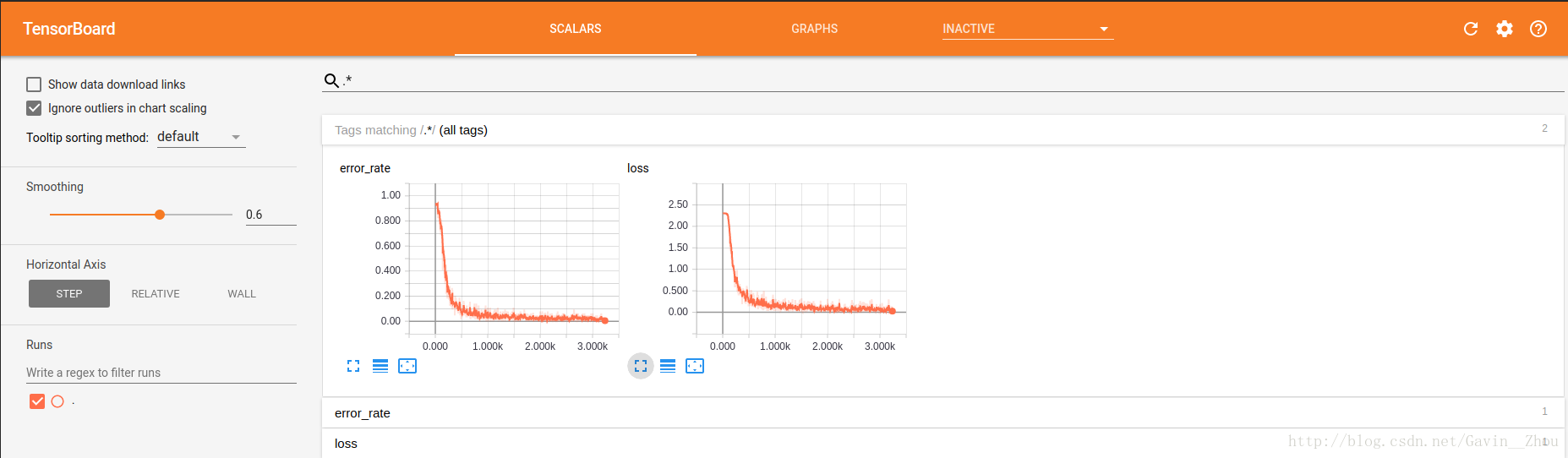
訓練時的loss和error_rate:
測試的error_rate:
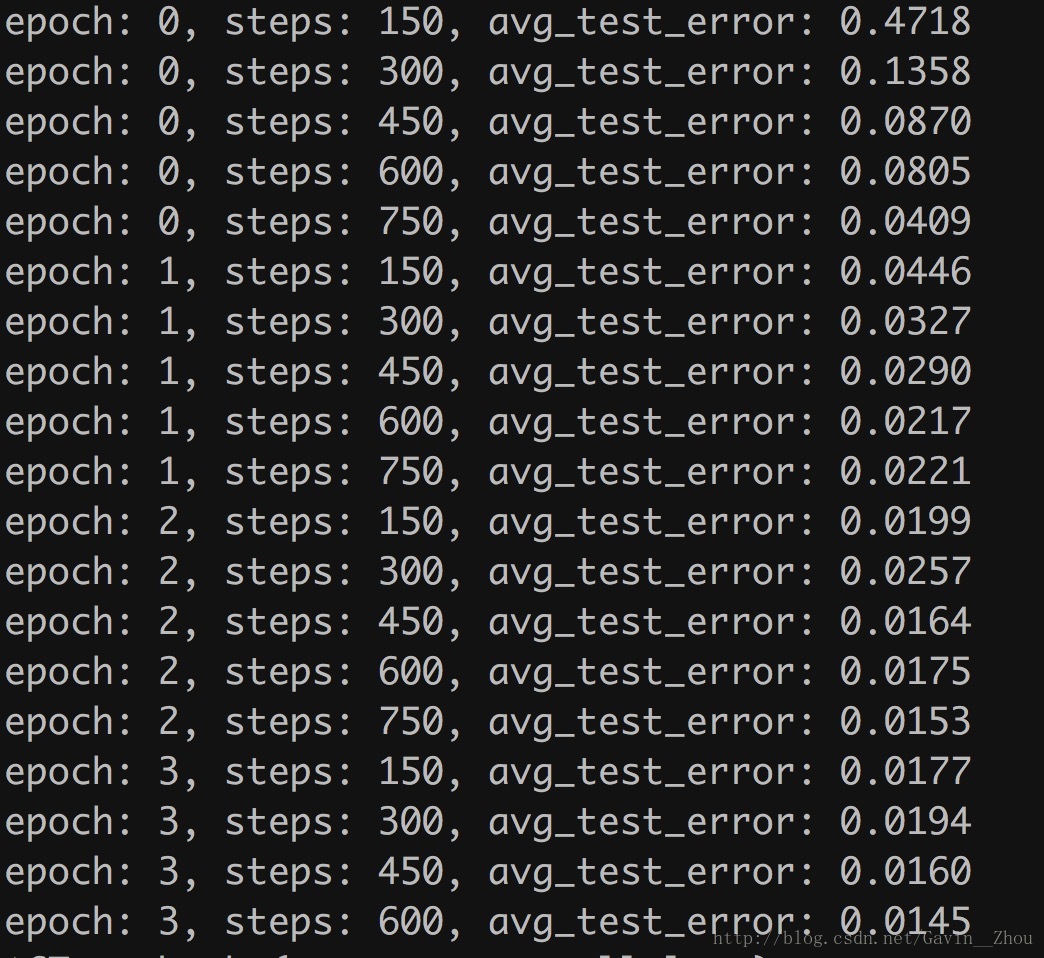
我只跑了3個epoch,錯誤率基本降低到1.5%左右,亦即正確率在98.5%左右,多跑幾個epoch可能錯誤率還能繼續降低,不過對於我們這個demo來說已經夠了.
相關推薦
使用RNN進行影象分類
基礎介紹 如何使用RNN進行mnist的分類呢?其實對應到RNN裡面就是個Sequence Classification問題. 先看下CS231n中關於RNN部分的一張圖: 其實影象的分類對應上圖就是個many to one的問題. 對於mni
【機器學習--SVM+Hog特徵描述進行影象分類】
Hog特徵描述子作為深度學習之前比較火的人工特徵描述子,往往和svm結合應用於行人檢測等分類領域,在機器學習中仍具有比較好的應用。 具體在opencv使用步驟如下: Hog特徵的資料集與標籤資料集製作處理。 訓練svm分類器 載入分類器進行預測 手寫數字的識別是
tensorflow 學習:用CNN進行影象分類
# -*- coding: utf-8 -*- from skimage import io,transform import glob import os import tensorflow as tf import numpy as np import time path='e:/flower/'
使用Keras預訓練模型ResNet50進行影象分類
Keras提供了一些用ImageNet訓練過的模型:Xception,VGG16,VGG19,ResNet50,InceptionV3。在使用這些模型的時候,有一個引數include_top表示是否包含模型頂部的全連線層,如果包含,則可以將影象分為ImageNet中的1000
用Inception-V3模型進行影象分類
Inception-V3模型簡介 本例使用預訓練好的深度神經網路Inception-v3模型來進行影象分類。Inception-v3模型在一臺配有 8 Tesla K40 GPUs,大概價值$3
基於tensorflow + Vgg16進行影象分類識別
1. VGG-16介紹 vgg是在Very Deep Convolutional Networks for Large-Scale Image Recognition期刊上提出的。模型可以達到92.7%的測試準確度,在ImageNet的前5位。它的資料集包括1
opencv輸出特徵資料、libsvm進行影象分類輸出置信度、matlab輸出ROC曲線
前言: 在研究分類問題時,可能會遇到需要分類器返回樣本屬於每一類的概率,而不是直接輸出該樣本的類別的情況。因為之前一直使用OpenCV庫進行開發,所以也想在opencv的ml模組尋找是否有對應功能的SVM分類器,無果。最後發現最新的LIBSVM庫提供類似功能的函式。於是,藉
tensorflow 1.0 學習:用Google訓練好的模型來進行影象分類
谷歌在大型影象資料庫ImageNet上訓練好了一個Inception-v3模型,這個模型我們可以直接用來進來影象分類。下載地址:github:https://github.com/taey16/tf/tree/master/imagenet下載完解壓後,得到幾個檔案:其中的c
tensorflow 1.0 學習:用別人訓練好的模型來進行影象分類
谷歌在大型影象資料庫ImageNet上訓練好了一個Inception-v3模型,這個模型我們可以直接用來進來影象分類。 下載完解壓後,得到幾個檔案: 其中的classify_image_graph_def.pb 檔案就是訓練好的Inception-v3模型。 imagenet_synset_to_h
Label-image進行影象分類
使用TensorFlow自帶的例項程式完成分類任務,現將整個實現過程記錄如下: 左圖為輸入圖,右圖為輸出結果在label檔案內的位置(位置-1=索引) 工程檔案簡介 1. 根據在Gi
The More You Know: Using Knowledge Graphs for Image Classification ——用知識圖譜進行影象分類論文閱讀筆記
Abstract 使人類區別於現代基於學習的計算機視覺演算法的一個特徵是獲得關於世界的知識並使用該知識推理關於視覺世界的能力。人類可以瞭解物體的特徵以及它們之間發生的關係,從而學習各種各樣的視覺概念,並且可以通過很少的例子學習。本文研究了知識圖譜形式的結構化先驗知
基於tensorflow + Vgg16進行影象分類識別的實驗
影象分類識別目前已經得到了很大的飛躍,特別是15年微軟提出的resnet已經超越人類,能夠對影象中的物體進行更好的識別。 為了初步瞭解一下影象分類識別的過程,學習了一下大牛的主頁,發現還是很有意思的。而且從imagenet的角度來說,這個經度還是可以接受的。 本實驗主
Tensorflow用別人訓練好的模型進行影象分類(可執行)
【先說一下自己想說的】:昨晚上找了很久才搞定,程式碼和給的檔案根本不匹配,轉載也不驗證一下就轉。弄得我花了一整天!(我就為了加個單擊圖片顯示可能的標籤這麼個功能我……我容易嗎……555) 原帖:http://www.cnblogs.com/denny402/p/694258
Tensorflow學習(7)用別人訓練好的模型進行影象分類
其中的classify_image_graph_def.pb 檔案就是訓練好的Inception-v3模型。 imagenet_synset_to_human_label_map.txt是類別檔案。 隨機找一張圖片:如 對這張圖片進行識別,看它屬於
tensorflow學習筆記十一:用別人訓練好的模型來進行影象分類
谷歌在大型影象資料庫ImageNet上訓練好了一個Inception-v3模型,這個模型我們可以直接用來進來影象分類。下載完解壓後,得到幾個檔案:其中的classify_image_graph_def.pb 檔案就是訓練好的Inception-v3模型。imagenet_sy
[深度學習框架] Keras上使用RNN進行mnist分類
import numpy as np np.random.seed(1337) # for reproducibility from keras.datasets import mnist from keras.utils import np_utils from ke
用PyTorch實現一個卷積神經網路進行影象分類
1. 回顧 在進入這一篇部落格的內容之前,我們先確保已經成功安裝好PyTorch,可以參考我之前的一篇部落格“Ubuntu12.04下PyTorch詳細安裝記錄”: http://blog.csdn.net/wblgers1234/article/details/729020161接下來,我們用設計一個簡單
Windows下caffe用fine-tuning訓練好的caffemodel來進行影象分類
小菜準備了幾張驗證的圖片存放路徑為caffe根目錄下的 examples/images/, 如果我們想用一個微調訓練好的caffemodel來對這張圖片進行分類,那該怎麼辦呢?下面小菜來詳細介紹一下這一任務的步驟。一般可以同兩種方式進行測試,分別是基於c++介
Android端使用TensorFlow進行影象分類
最近一直在看TensorFlow的視訊教程,它是Google的一個機器學習的跨平臺開源框架,可以移植到Android、ios等移動端裝置執行。GitHub上面有許多關於TensorFlow開發demo,這讓極客開發者們心情躁動,躍躍欲試。今天主要與大家探討下運用T
Keras入門(五)搭建ResNet對CIFAR-10進行影象分類
本文將會介紹如何利用Keras來搭建著名的ResNet神經網路模型,在CIFAR-10資料集進行影象分類。 資料集介紹 CIFAR-10資料集是已經標註好的影象資料集,由Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton三人收集,其訪問網址為:https: