
opencv輸出特徵資料、libsvm進行影象分類輸出置信度、matlab輸出ROC曲線
前言:
在研究分類問題時,可能會遇到需要分類器返回樣本屬於每一類的概率,而不是直接輸出該樣本的類別的情況。因為之前一直使用OpenCV庫進行開發,所以也想在opencv的ml模組尋找是否有對應功能的SVM分類器,無果。最後發現最新的LIBSVM庫提供類似功能的函式。於是,藉助LIBSVM,實現了樣本的概率估計。(引用自http://blog.csdn.net/u011853479/article/details/51326132)
1.1 libsvm:到http://www.csie.ntu.edu.tw/~cjlin/libsvm/ 下載,我用的是libsvm-3.22.zip,下載後直接解壓縮到任意位置,我解壓到E:\Codes\libsvm-3.22下。
1.2 python:到http://www.python.org/download/ 下載(該地址可能需要FQ),我下的是python-2.7.3.msi,雙擊該檔案安裝到預設位置,我安裝到C:\Python27下。將該路徑新增到系統環境變數中。新增方法:右鍵點選 我的電腦 -> 屬性 -> 高階系統設定 -> 環境變數,在 系統變數 裡找到 path, 點選 編輯,在彈出框最後加上 C:\Python27;(注意用分號與之前的項隔開) 之後重啟電腦。
1.3 gunplot:到http://www.gnuplot.info/ 下載,我下的是gp460-win32-setup.exe,雙擊該檔案安裝到預設位置,我安裝到C:\Program Files (x86)
1.4. 生成訓練資料和測試資料,分別存為train和test兩個文字檔案,拷貝到libsvm-3.12\tools下。
1.5. 進入libsvm-3.12\tools下,用寫字板開啟easy.py,將裡面gnuplot_exe = 後的路徑改為gnuplot的安裝路徑,對於我的情況:
gnuplot_exe = r"C:\Program Files (x86)\gnuplot\bin\gnuplot.exe"。同樣,用寫字板開啟grid.py,修改gnuplot_pathname = r'C:\Program Files (x86)\gnuplot\bin\gnuplot.exe'。修改這兩個檔案時都要注意,要修改else下的gnuplot_exe,而不是if not is_win32下的。另外要注意,如果修改完後easy.py或grid.py預設開啟程式變成了寫字板,要把它改回成python.exe
1.6. 在命令列cd到該路徑libsvm-3.12\tools下,命令列輸入easy.py train test,敲回車,程式會自動執行scale,引數尋優,生成svm模型train.model,用該模型對test資料進行預測,並給出準確度。(截圖如下)
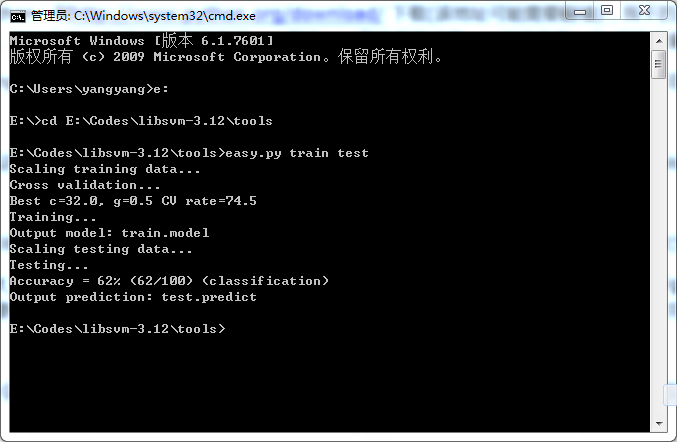
2、輸出置信度
2.1 利用交叉驗證找到最優的懲罰因子C和RBF核函式中的引數gamma
步驟如下:
進入libsvm-tools的路徑下,輸入 python.exe(加上所在路徑) easy.py train(訓練資料),如下所示:

2.2 訓練資料(對於分類來說就是opencv輸出的特徵資料)
進入進入libsvm-windows的路徑下,輸入 svm-train.exe -c 512.0 -g 0.3125 -b 1 train(訓練資料,加上所在路徑) train.model(生成訓練模型),如下所示:(注:‘-b 1 ’是為了輸出置信度)

2.3 測試資料(對於分類來說就是opencv輸出的特徵資料)
進入進入libsvm-windows的路徑下,輸入 svm-predict.exe -b 1 test(測試資料,加上所在路徑) train.model(訓練模型,加上所在路徑) predict.model(生成預測資料),如下圖所示:

注:如果訓練資料過多可能會出現“wrong input in format 8684”,具體什麼意思,我沒搞清楚。
3、畫ROC曲線(二類、多類均可以)
所需資料:預測資料和測試資料
score = predict.model(:,1); %‘1’是所需類對應的列數
[x,y]=perfcurve(test_labels,score,1); %test_labels是輸入資料,‘1’是對應的類的標籤
plot(x,y,'-r');
legend('hog','location','best');
xlabel('假陽性率(False
Positive Rate)'); ylabel('真陽性率(True
positive rate)')