
距離度量以及python實現(一)
1. 歐氏距離(Euclidean Distance)
歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。
(1)二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離:
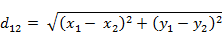
(2)三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
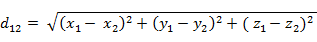
(3)兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的歐氏距離:
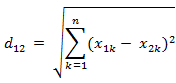
(4)也可以用表示成向量運算的形式:

python中的實現:
方法一:
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根據公式求解 d1=np.sqrt(np.sum(np.square(x-y))) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdist X=np.vstack([x,y]) d2=pdist(X)
2. 曼哈頓距離(Manhattan Distance)
從名字就可以猜出這種距離的計算方法了。想象你在曼哈頓要從一個十字路口開車到另外一個十字路口,駕駛距離是兩點間的直線距離嗎?顯然不是,除非你能穿越大樓。實際駕駛距離就是這個“曼哈頓距離”。而這也是曼哈頓距離名稱的來源, 曼哈頓距離也稱為城市街區距離
(1)二維平面兩點a(x1,y1)與b(x2,y2)間的曼哈頓距離
(2)兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的曼哈頓距離
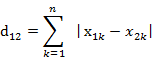
python中的實現 :
import numpy as np x=np.random.random(10) y=np.random.random(10) #方法一:根據公式求解 d1=np.sum(np.abs(x-y)) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X,'cityblock')
3. 切比雪夫距離 ( Chebyshev Distance )
國際象棋玩過麼?國王走一步能夠移動到相鄰的8個方格中的任意一個。那麼國王從格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走試試。你會發現最少步數總是max(
| x2-x1 | , | y2-y1 | ) 步 。有一種類似的一種距離度量方法叫切比雪夫距離。
(1)二維平面兩點a(x1,y1)與b(x2,y2)間的切比雪夫距離
![]()
(2)兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的切比雪夫距離
![]()
這個公式的另一種等價形式是
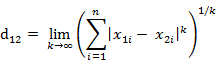
看不出兩個公式是等價的?提示一下:試試用放縮法和夾逼法則來證明。
在python中的實現:
import numpy as np x=np.random.random(10) y=np.random.random(10) #方法一:根據公式求解 d1=np.max(np.abs(x-y)) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdist X=np.vstack([x,y]) d2=pdist(X,'chebyshev')
4. 閔可夫斯基距離(Minkowski Distance)
閔氏距離不是一種距離,而是一組距離的定義。
(1) 閔氏距離的定義
兩個n維變數a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:

也可寫成
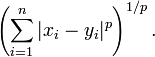
其中p是一個變引數。
當p=1時,就是曼哈頓距離
當p=2時,就是歐氏距離
當p→∞時,就是切比雪夫距離
根據變引數的不同,閔氏距離可以表示一類的距離。
(2)閔氏距離的缺點
閔氏距離,包括曼哈頓距離、歐氏距離和切比雪夫距離都存在明顯的缺點。
舉個例子:二維樣本(身高,體重),其中身高範圍是150~190,體重範圍是50~60,有三個樣本:a(180,50),b(190,50),c(180,60)。那麼a與b之間的閔氏距離(無論是曼哈頓距離、歐氏距離或切比雪夫距離)等於a與c之間的閔氏距離,但是身高的10cm真的等價於體重的10kg麼?因此用閔氏距離來衡量這些樣本間的相似度很有問題。
簡單說來,閔氏距離的缺點主要有兩個:(1)將各個分量的量綱(scale),也就是“單位”當作相同的看待了。(2)沒有考慮各個分量的分佈(期望,方差等)可能是不同的。
python中的實現:
import numpy as np x=np.random.random(10) y=np.random.random(10) #方法一:根據公式求解,p=2 d1=np.sqrt(np.sum(np.square(x-y))) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdist X=np.vstack([x,y]) d2=pdist(X,'minkowski',p=2)
5. 標準化歐氏距離 (Standardized Euclidean distance )
(1)標準歐氏距離的定義
標準化歐氏距離是針對簡單歐氏距離的缺點而作的一種改進方案。標準歐氏距離的思路:既然資料各維分量的分佈不一樣,好吧!那我先將各個分量都“標準化”到均值、方差相等吧。均值和方差標準化到多少呢?這裡先複習點統計學知識吧,假設樣本集X的均值(mean)為m,標準差(standard
deviation)為s,那麼X的“標準化變數”表示為:
![]()
標準化後的值 = ( 標準化前的值 - 分量的均值 ) /分量的標準差
經過簡單的推導就可以得到兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的標準化歐氏距離的公式:

如果將方差的倒數看成是一個權重,這個公式可以看成是一種加權歐氏距離(Weighted Euclidean distance)。
python中的實現:
import numpy as np x=np.random.random(10) y=np.random.random(10) X=np.vstack([x,y]) #方法一:根據公式求解 sk=np.var(X,axis=0,ddof=1) d1=np.sqrt(((x - y) ** 2 /sk).sum()) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdist d2=pdist(X,'seuclidean')
6. 馬氏距離(Mahalanobis Distance)
(1)馬氏距離定義
有M個樣本向量X1~Xm,協方差矩陣記為S,均值記為向量μ,則其中樣本向量X到u的馬氏距離表示為:
![]()
而其中向量Xi與Xj之間的馬氏距離定義為:
![]()
若協方差矩陣是單位矩陣(各個樣本向量之間獨立同分布),則公式就成了:
![]()
也就是歐氏距離了。
若協方差矩陣是對角矩陣,公式變成了標準化歐氏距離。
python 中的實現:
import numpy as np x=np.random.random(10) y=np.random.random(10) #馬氏距離要求樣本數要大於維數,否則無法求協方差矩陣 #此處進行轉置,表示10個樣本,每個樣本2維 X=np.vstack([x,y]) XT=X.T #方法一:根據公式求解 S=np.cov(X) #兩個維度之間協方差矩陣 SI = np.linalg.inv(S) #協方差矩陣的逆矩陣 #馬氏距離計算兩個樣本之間的距離,此處共有10個樣本,兩兩組合,共有45個距離。 n=XT.shape[0] d1=[] for i in range(0,n): for j in range(i+1,n): delta=XT[i]-XT[j] d=np.sqrt(np.dot(np.dot(delta,SI),delta.T)) d1.append(d) #方法二:根據scipy庫求解 from scipy.spatial.distance import pdist d2=pdist(XT,'mahalanobis')
馬氏優缺點:
1)馬氏距離的計算是建立在總體樣本的基礎上的,這一點可以從上述協方差矩陣的解釋中可以得出,也就是說,如果拿同樣的兩個樣本,放入兩個不同的總體中,最後計算得出的兩個樣本間的馬氏距離通常是不相同的,除非這兩個總體的協方差矩陣碰巧相同;
2)在計算馬氏距離過程中,要求總體樣本數大於樣本的維數,否則得到的總體樣本協方差矩陣逆矩陣不存在,這種情況下,用歐式距離計算即可。
3)還有一種情況,滿足了條件總體樣本數大於樣本的維數,但是協方差矩陣的逆矩陣仍然不存在,比如三個樣本點(3,4),(5,6)和(7,8),這種情況是因為這三個樣本在其所處的二維空間平面內共線。這種情況下,也採用歐式距離計算。
4)在實際應用中“總體樣本數大於樣本的維數”這個條件是很容易滿足的,而所有樣本點出現3)中所描述的情況是很少出現的,所以在絕大多數情況下,馬氏距離是可以順利計算的,但是馬氏距離的計算是不穩定的,不穩定的來源是協方差矩陣,這也是馬氏距離與歐式距離的最大差異之處。
優點:它不受量綱的影響,兩點之間的馬氏距離與原始資料的測量單位無關;由標準化資料和中心化資料(即原始資料與均值之差)計算出的二點之間的馬氏距離相同。馬氏距離還可以排除變數之間的相關性的干擾。缺點:它的缺點是誇大了變化微小的變數的作用。
參考:
相關推薦
距離度量以及python實現(一)
1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離: (2)三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
距離度量以及python實現(二)
block eight spatial related sim tar 平移 spa spl 接上一篇:http://www.cnblogs.com/denny402/p/7027954.html 7. 夾角余弦(Cosine) 也可以叫余弦相似度。
概率分佈之間的距離度量以及python實現
原文連結:https://www.cnblogs.com/wt869054461/p/7156397.html 1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面
概率分佈之間的距離度量以及python實現(三)
概率分佈之間的距離,顧名思義,度量兩組樣本分佈之間的距離 。 1、卡方檢驗 統計學上的χ2統計量,由於它最初是由英國統計學家Karl Pearson在1900年首次提出的,因此也稱之為Pearson χ2,其計算公式為 (i=1,2,3,…,k) 其中,Ai為i水平的觀察頻數,Ei為i水平
概率分佈之間的距離度量以及python實現(四)
1、f 散度(f-divergence) KL-divergence 的壞處在於它是無界的。事實上KL-divergence 屬於更廣泛的 f-divergence 中的一種。 如果P和Q被定義成空間中的兩個概率分佈,則f散度被定義為: 一些通用的散度,如KL-divergence, Helling
距離度量與python實現
1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離: (2)三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離: (3)兩
資料歸一化以及Python實現方式
資料歸一化: 資料的標準化是將資料按比例縮放,使之落入一個小的特定區間,去除資料的單位限制,將其轉化為無量綱的純數值,便於不同單位或量級的指標能夠進行比較和加權。 為什麼要做歸一化: 1)加快梯度下降求最優解的速度 如果兩個特徵的區間相差非常大,其所
200.1 Python實現一筆畫完輔助
1.1構思 源:微信小程式 轉:騰訊手遊助手 使程式識別方塊(黑色方塊、白色方塊、起點方塊) 進行計算出路(利用遞迴窮舉法) 1.2 識別演算法 利用:圖片.getpixel((x,y)) 獲取目標介面的顏色分佈:顏色字典 利用黑色方塊、白色
神經網路學習(4)————自組織特徵對映神經網路(SOM)以及python實現
一、自組織競爭學習神經網路模型(無監督學習) (一)競爭神經網路 在競爭神經網路中,一層是輸入層,一層輸出層,輸出層又稱為競爭層或者核心層。在一次輸入中,權值是隨機給定的,在競爭層每個神經元獲勝的概率相同,但是最後會有一個興奮最強的神經元。興奮最強的神經元戰勝了其他神
神經網路學習(3)————BP神經網路以及python實現
一、BP神經網路結構模型 BP演算法的基本思想是,學習過程由訊號的正向傳播和誤差的反向傳播倆個過程組成,輸入從輸入層輸入,經隱層處理以後,傳向輸出層。如果輸出層的實際輸出和期望輸出不符合
神經網路學習(2)————線性神經網路以及python實現
一、線性神經網路結構模型 在結構上與感知器非常相似,只是神經元啟用函式不同,結構如圖所示: 若網路中包含多個神經元節點,就可形成多個輸出,這種神經網路可以用一種間接的方式解決線性不可分的問題,方法是用多個線性含糊對區域進行劃分,神經結構和解決異或問題如圖所示: &nbs
文字相似度bm25演算法的原理以及Python實現(jupyter notebook)
今天我們一起來學習一下自然語言處理中的bm25演算法,bm25演算法是常見的用來計算query和文章相關度的相似度的。其實這個演算法的原理很簡單,就是將需要計算的query分詞成w1,w2,…,wn,然後求出每一個詞和文章的相關度,最後將這些相關度進行累加,最終就可以的得到文字相似度計算
決策樹(ID3 C4,5 減枝 CART演算法)以及Python實現
演算法簡述 在《統計學習方法》中,作者的if-then的描述,簡單一下子讓人理解了決策樹的基本概念。 決策樹,就是一個if-then的過程。 本文主要學習自《統計學習方法》一書,並努力通過書中數學推導來
設計模式之單例模式與工廠模式的Python實現(一)
1. 單例模式 單例模式(Singleton Pattern)是一種常用的軟體設計模式,該模式的主要目的是確保某一個類只有一個例項存在。當你希望在整個系統中,某個類只能出現一個例項時,單例物件就能派上用場。 比如,某個伺服器程式的配置資訊存放在一個檔案中,客戶端通過一個 AppConfig 的類來讀取配置檔案
PCA演算法的數學原理以及Python實現
部落格中的筆記: 降維當然意味著資訊的丟失,不過鑑於實際資料本身常常存在的相關性,我們可以想辦法在降維的同時將資訊的損失儘量降低。 根據相關性來講資訊的損失量降到最低 更正式的說,向量(x,y)實際上表示線性組合: x(1,0)?+y(0,1)? 不難證明所有二
通過微信,python實現一鍵查詢天氣+火車票+飛機票+快遞物流!
前言: 今天我們來進一步地實現更高階點的功能——查天氣+火車+飛機+快遞!!!當,這裡只是把他們集中在一起了,通過微信itchat的自動回覆功能,實現回覆關鍵字,返回自動查詢結果的效果! 學習Python中有不明白推薦加入交流群
用python實現一段程式碼,它的功能是將自己列印
今天看到一道有趣的面試題,用python實現一段程式碼,然後將自己列印,其實很簡單 import sys 首先匯入 sys 模組 f_name = sys.argv[0] sys.argv[ ]第一個元素是程式本身,sys.argv[0]
SVM引數引數介紹以及python實現GA對SVM引數的優化
最近開始玩起了機器學習,以前都是用matlab做一些機器學習的東西,畢竟要真正放到工程上應用還是python用起來比較好,所以今天就開始學習下使用SVM進行迴歸(分類)預測。 SVM 使用的一般步驟是: 1)準備資料集,轉化為 SVM支援的資料格式 : [label] [ind
Python實現一個數組除以一個數
如果直接用python的一個list除以一個數,會報錯: a = [1.0, 1.0, 1.0] c = a/3 print(c) TypeError: unsupported operand ty
RC4原理以及python實現
簡介 RC4(來自Rivest Cipher 4的縮寫)是一種流加密演算法,金鑰長度可變。它加解密使用相同的金鑰,一個位元組一個位元組地加密。因此也屬於對稱加密演算法。突出優點是在軟體裡面很容易實現。 加密流程 包含兩個處理過程:一是祕鑰排程演算法(KSA),用於之亂S盒的初