
概率分佈之間的距離度量以及python實現(四)
1、f 散度(f-divergence)
KL-divergence 的壞處在於它是無界的。事實上KL-divergence 屬於更廣泛的 f-divergence 中的一種。
如果P和Q被定義成空間中的兩個概率分佈,則f散度被定義為:

一些通用的散度,如KL-divergence, Hellinger distance, 和total variation distance,都是f散度的一種特例。只是f函式的取值不同而也。
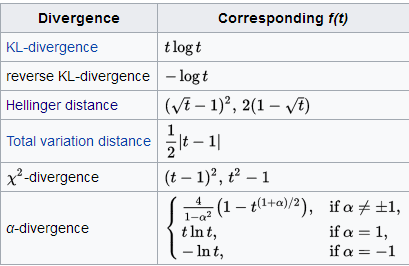
在python中的實現 :
import numpy as np import scipy.stats p=np.asarray([0.65,0.25,0.07,0.03]) q=np.array([0.6,0.25,0.1,0.05]) def f(t): return t*np.log(t) #方法一:根據公式求解 f1=np.sum(q*f(p/q)) #方法二:呼叫scipy包求解 f2=scipy.stats.entropy(p, q)
2、Hellinger distance
1 定義
1.1 度量理論
為了從度量理論的角度定義Hellinger距離,我們假設P和Q是兩個概率測度,並且它們對於第三個概率測度λ來說是絕對連續的,則P和Q的Hellinger距離的平方被定義如下:

這裡的dP / dλ

1.2 基於Lebesgue度量的概率理論
為了在經典的概率論框架下定義Hellinger距離,我們通常將λ定義為Lebesgue度量,此時dP / dλ 和 dQ / dλ就變為了我們通常所說的概率密度函式。如果我們把上述概率密度函式分別表示為 f 和 g ,那麼可以用以下的積分形式表示Hellinger距離:
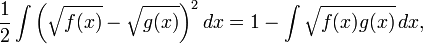
上述等式可以通過展開平方項得到,注意到任何概率密度函式在其定義域上的積分為1。
根據柯西-施瓦茨不等式(Cauchy-Schwarz inequality),Hellinger距離滿足如下性質:
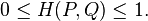
1.3 離散概率分佈
對於兩個離散概率分佈 P=(p1,p2,...,pn)和 Q=(q1,q2,...,qn),它們的Hellinger距離可以定義如下:
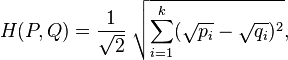
上式可以被看作兩個離散概率分佈平方根向量的歐式距離,如下所示:
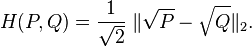
也可以寫成:
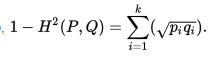
在python中的實現:
import numpy as np p=np.asarray([0.65,0.25,0.07,0.03]) q=np.array([0.6,0.25,0.1,0.05]) #方法一: h1=1/np.sqrt(2)*np.linalg.norm(np.sqrt(p)-np.sqrt(q)) #方法二: h2=np.sqrt(1-np.sum(np.sqrt(p*q)))
3、巴氏距離(Bhattacharyya Distance)
在統計中,Bhattacharyya距離測量兩個離散或連續概率分佈的相似性。它與衡量兩個統計樣品或種群之間的重疊量的Bhattacharyya係數密切相關。Bhattacharyya距離和Bhattacharyya係數以20世紀30年代曾在印度統計研究所工作的一個統計學家A. Bhattacharya命名。同時,Bhattacharyya係數可以被用來確定兩個樣本被認為相對接近的,它是用來測量中的類分類的可分離性。
對於離散概率分佈 p和q在同一域 X,巴氏距離被定義為:

其中BC(p,q)是Bhattacharyya係數:
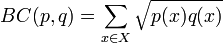
對於連續概率分佈,Bhattacharyya係數被定義為:

從公式可以看出,Bhattacharyya係數BC(P,Q)可以和前面的Hellinger距離聯絡起來,此時Hellinger距離可以被定義為:

因此,求得巴氏係數之後,就可以求得巴氏距離和Hellinger距離。
在python中的實現:
import numpy as np p=np.asarray([0.65,0.25,0.07,0.03]) q=np.array([0.6,0.25,0.1,0.05]) BC=np.sum(np.sqrt(p*q)) #Hellinger距離: h=np.sqrt(1-BC) #巴氏距離: b=-np.log(BC)
4、MMD距離(Maximum mean discrepancy)
最大均值差異(Maximum mean discrepancy),度量在再生希爾伯特空間中兩個分佈的距離,是一種核學習方法。兩個隨機變數的距離為:

其中k(.)是對映,用於把原變數對映到高維空間中。X,Y表示兩種分佈的樣本,F表示對映函式集。
基於兩個分佈的樣本,通過尋找在樣本空間上的對映函式K,求不同分佈的樣本在K上的函式值的均值,通過把兩個均值作差可以得到兩個分佈對應於K的mean discrepancy。尋找一個K使得這個mean discrepancy有最大值,就得到了MMD。最後取MMD作為檢驗統計量(test statistic),從而判斷兩個分佈是否相同。如果這個值足夠小,就認為兩個分佈相同,否則就認為它們不相同。更加簡單的理解就是:求兩堆資料在高維空間中的均值的距離。
近年來,MMD越來越多地應用在遷移學習中。在遷移學習環境下訓練集和測試集分別取樣自分佈p和q,兩類樣本集不同但相關。我們可以利用深度神經網路的特徵變換能力,來做特徵空間的變換,直到變換後的特徵分佈相匹配,這個過程可以是source domain一直變換直到匹配target domain。匹配的度量方式就是MMD。
在python中的實現,根據核函式不同,公式可能不一樣,根據公式程式設計即可。
5、Wasserstein distance
Wasserstein 距離,也叫Earth Mover's Distance,推土機距離,簡稱EMD,用來表示兩個分佈的相似程度。
Wasserstein distance 衡量了把資料從分佈“移動成”分佈
時所需要移動的平均距離的最小值(類似於把一堆土從一個形狀移動到另一個形狀所需要做的功的最小值)
EMD是2000年IJCV期刊文章《The Earth Mover's Distance as a Metric for Image Retrieval》提出的一種直方圖相似度量(作者在之前的會議論文中也已經提到,不過鑑於IJCV的權威性和完整性,建議參考這篇文章)。
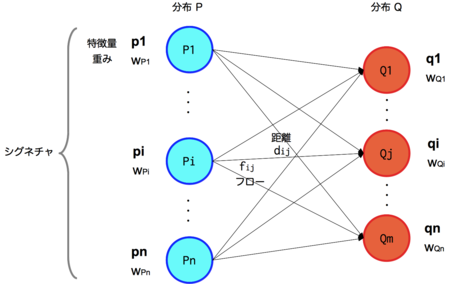
假設有兩個工地P和Q,P工地上有m堆土,Q工地上有n個坑,現在要將P工地上的m堆土全部移動到Q工地上的n個坑中,所做的最小的功。
每堆土我們用一個二元組來表示(p,w),p表示土堆的中心,w表示土的數量。則這兩個工地可表示為:

每個土堆中心pi到每個土坑中心qj都會有一個距離dij,則構成了一個m*n的距離矩陣。

那麼問題就是我們希望找到一個流(flow),當然也是個矩陣[fij],每一項fij代表從pi到qj的流動數量,從而最小化整體的代價函式:
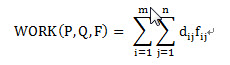
問題描述清楚了:就是把P中的m個坑的土,用最小的代價搬到Q中的n個坑中,pi到qj的兩個坑的距離由dij來表示。fij是從pi搬到qj的土的量;dij是pi位置到qj位置的代價(距離)。要最小化WORK工作量。EMD是把這個工作量歸一化以後的表達,即除以對fij的求和。
EMD公式:
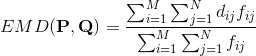
更多關於EMD的理解請參考:
在python中的實現:呼叫opencv
import numpy as np import cv #p、q是兩個矩陣,第一列表示權值,後面三列表示直方圖或數量 p=np.asarray([[0.4,100,40,22], [0.3,211,20,2], [0.2,32,190,150], [0.1,2,100,100]],np.float32) q=np.array([[0.5,0,0,0], [0.3,50,100,80], [0.2,255,255,255]],np.float32) pp=cv.fromarray(p) qq=cv.fromarray(q) emd=cv.CalcEMD2(pp,qq,cv.CV_DIST_L2)
最後計算出來的emd:
emd = 160.542770相關推薦
概率分佈之間的距離度量以及python實現(四)
1、f 散度(f-divergence) KL-divergence 的壞處在於它是無界的。事實上KL-divergence 屬於更廣泛的 f-divergence 中的一種。 如果P和Q被定義成空間中的兩個概率分佈,則f散度被定義為: 一些通用的散度,如KL-divergence, Helling
概率分佈之間的距離度量以及python實現
原文連結:https://www.cnblogs.com/wt869054461/p/7156397.html 1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面
概率分佈之間的距離度量以及python實現(三)
概率分佈之間的距離,顧名思義,度量兩組樣本分佈之間的距離 。 1、卡方檢驗 統計學上的χ2統計量,由於它最初是由英國統計學家Karl Pearson在1900年首次提出的,因此也稱之為Pearson χ2,其計算公式為 (i=1,2,3,…,k) 其中,Ai為i水平的觀察頻數,Ei為i水平
距離度量以及python實現(二)
block eight spatial related sim tar 平移 spa spl 接上一篇:http://www.cnblogs.com/denny402/p/7027954.html 7. 夾角余弦(Cosine) 也可以叫余弦相似度。
距離度量以及python實現(一)
1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離: (2)三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
距離度量與python實現
1. 歐氏距離(Euclidean Distance) 歐氏距離是最易於理解的一種距離計算方法,源自歐氏空間中兩點間的距離公式。 (1)二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離: (2)三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離: (3)兩
神經網路學習(4)————自組織特徵對映神經網路(SOM)以及python實現
一、自組織競爭學習神經網路模型(無監督學習) (一)競爭神經網路 在競爭神經網路中,一層是輸入層,一層輸出層,輸出層又稱為競爭層或者核心層。在一次輸入中,權值是隨機給定的,在競爭層每個神經元獲勝的概率相同,但是最後會有一個興奮最強的神經元。興奮最強的神經元戰勝了其他神
神經網路學習(3)————BP神經網路以及python實現
一、BP神經網路結構模型 BP演算法的基本思想是,學習過程由訊號的正向傳播和誤差的反向傳播倆個過程組成,輸入從輸入層輸入,經隱層處理以後,傳向輸出層。如果輸出層的實際輸出和期望輸出不符合
神經網路學習(2)————線性神經網路以及python實現
一、線性神經網路結構模型 在結構上與感知器非常相似,只是神經元啟用函式不同,結構如圖所示: 若網路中包含多個神經元節點,就可形成多個輸出,這種神經網路可以用一種間接的方式解決線性不可分的問題,方法是用多個線性含糊對區域進行劃分,神經結構和解決異或問題如圖所示: &nbs
文字相似度bm25演算法的原理以及Python實現(jupyter notebook)
今天我們一起來學習一下自然語言處理中的bm25演算法,bm25演算法是常見的用來計算query和文章相關度的相似度的。其實這個演算法的原理很簡單,就是將需要計算的query分詞成w1,w2,…,wn,然後求出每一個詞和文章的相關度,最後將這些相關度進行累加,最終就可以的得到文字相似度計算
決策樹(ID3 C4,5 減枝 CART演算法)以及Python實現
演算法簡述 在《統計學習方法》中,作者的if-then的描述,簡單一下子讓人理解了決策樹的基本概念。 決策樹,就是一個if-then的過程。 本文主要學習自《統計學習方法》一書,並努力通過書中數學推導來
PCA演算法的數學原理以及Python實現
部落格中的筆記: 降維當然意味著資訊的丟失,不過鑑於實際資料本身常常存在的相關性,我們可以想辦法在降維的同時將資訊的損失儘量降低。 根據相關性來講資訊的損失量降到最低 更正式的說,向量(x,y)實際上表示線性組合: x(1,0)?+y(0,1)? 不難證明所有二
SVM引數引數介紹以及python實現GA對SVM引數的優化
最近開始玩起了機器學習,以前都是用matlab做一些機器學習的東西,畢竟要真正放到工程上應用還是python用起來比較好,所以今天就開始學習下使用SVM進行迴歸(分類)預測。 SVM 使用的一般步驟是: 1)準備資料集,轉化為 SVM支援的資料格式 : [label] [ind
RC4原理以及python實現
簡介 RC4(來自Rivest Cipher 4的縮寫)是一種流加密演算法,金鑰長度可變。它加解密使用相同的金鑰,一個位元組一個位元組地加密。因此也屬於對稱加密演算法。突出優點是在軟體裡面很容易實現。 加密流程 包含兩個處理過程:一是祕鑰排程演算法(KSA),用於之亂S盒的初
分類——樸素貝葉斯分類器以及Python實現
核心思想: 根據訓練資料獲取模型的後驗概率,對應後驗概率越大的類即預測類。 演算法簡介: 模型: 先驗概率:p(y=Ck)p(y=Ck) 條件概率:p(X=x|y=Ck)p(X=x|y=Ck) 後驗概率:p(y=Ck|X=x)p(y=Ck|X=
NG機器學習總結-(四)邏輯迴歸以及python實現
在第一篇部落格NG機器學習總結一中,我們提到了監督學習通常一般可以分為兩類:迴歸和分類。線性迴歸屬於迴歸問題,例如房價的預測問題。而判斷一封郵件是否是垃圾郵件、腫瘤的判斷(良性還是惡性)、線上交易是否欺詐都是分類問題,當然這些都是二分類的問題。 Email:Spam /
機器學習演算法 之邏輯迴歸以及python實現
下面分為兩個部分: 1. 邏輯迴歸的相關原理說明 2. 通過python程式碼來實現一個梯度下降求解邏輯迴歸過程 邏輯迴歸(Logistic Regression) 首先需要說明,邏輯迴歸屬於分類演算法。分類問題和迴歸問題的區別在於,分類問題的輸出是離散
NG機器學習總結-(三)線性迴歸以及python實現
在前面已經簡單介紹了迴歸問題(預測房價),其實在統計學中,線性迴歸(Linear Regression)是利用被稱為線性迴歸方程的最小平方函式(Cost Function)對一個或多個自變數和因變數之間關係進行建模的一種迴歸分析。這種函式式一個或多個被稱為迴歸係數的模型引數的
聚類——譜聚類演算法以及Python實現
譜聚類(spectral cluster)可以視為一種改進的Kmeans的聚類演算法。常用來進行影象分割。缺點是需要指定簇的個數,難以構建合適的相似度矩陣。優點是簡單易實現。相比Kmeans而言,處理高維資料更合適。 核心思想 構建樣本點的相似度矩陣(圖
聚類——MeanShift演算法以及Python實現
均值漂移演算法(MeanShift)是一種旨在發現團(blobs)的聚類演算法 核心思想 尋找核密度極值點並作為簇的質心,然後根據最近鄰原則將樣本點賦予質心 演算法簡介 核密度估計 根據樣本分佈估計在樣本空間的每一點的密度。估計某點的密度時,核密度估計方法會考慮