
TensorsFlow學習筆記3----面向機器學習初學者的MNIST教程(MNIST For ML Beginners)
記錄關鍵內容與學習感受。未完待續。。
面向機器初學者的MNIST教程(MNIST For ML Beginners)
—–適用於對機器學習和tensorflow初學者。而這裡MNIST就好比學語言時候的列印hello world。
—–MNIST是一個簡單的計算機視覺資料集,它包括各種手寫數字的影象,比如:

—–它也包含每張影象對應的標籤,告訴我們這是哪個數字,上面四張影象的標籤分別是5、0、4、1。
—–在本教程中,我們訓練一個模型觀察影象來預測這個數字是多少。我們的目標並不是訓練一個真正複雜的模型,這個模型可以實現最先進效能。儘管後面我們會給你原始碼去實現這件事,但是我們主要是介紹如何使用tensorflow。所以,我們會從一個簡單的數學模型學起,softmax regression。
—–對應於這個教程的實際程式碼非常短,所有有意思的內容只在三行程式碼中。然後去理解這些程式碼背後的意義是十分重要的,包括tensorflow是如何運作,機器學習核心概念。因為,本教程會詳細介紹這些程式碼。
1、關於教程
——你可以以下面幾種不同的方法使用這篇教程。
- 每讀一行解釋,就在Python環境中複製貼上一行程式碼。
- 在閱讀解釋前或者後,執行這個mnist_softmax.py的Python檔案,並使用這個教程來理解你不明白的那幾行程式碼。
—–我們在篇教程中完成:
- 學習MNIST資料集和softmax regression。
- 基於觀察影象中的每個畫素,建立一個函式,也就是這個模型來識別數字。
- 使用tensorflow,通過“看”成千上萬的例子,訓練這個模型來識別數字。
- 利用測試資料檢查模型的精確度。
2、MNIST資料集
—–MNIST資料由Yann LeCun’s website提供。你可以將這兩行程式碼複製貼上到你的程式碼中,或者下載資料集,然後執行這兩行程式碼,就會自動下載和讀取這個資料集。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)—–寫到這裡,為了執行這兩段程式碼,可謂出了各種錯誤。AttributeError: ‘module’ object has no attribute ‘_base’,大坑。如下:


—–起初以為是路徑不對的原因,修改如下:

—–竟然出現語法錯誤。繼續修改,還不行:
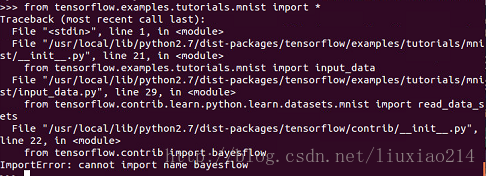
—–繼續修改,還是不行,已崩潰,先不管。

—–最後問題解決,當第一次出現錯誤時,就提醒了是“呼叫這個html5lib的一個模組的時候,沒找到_base”,於是升級html5 Python lib 庫,結果還是不行,最後發現有人遇到過著這個問題,需要降級為1.08b,終於解決了,折騰過程如下:
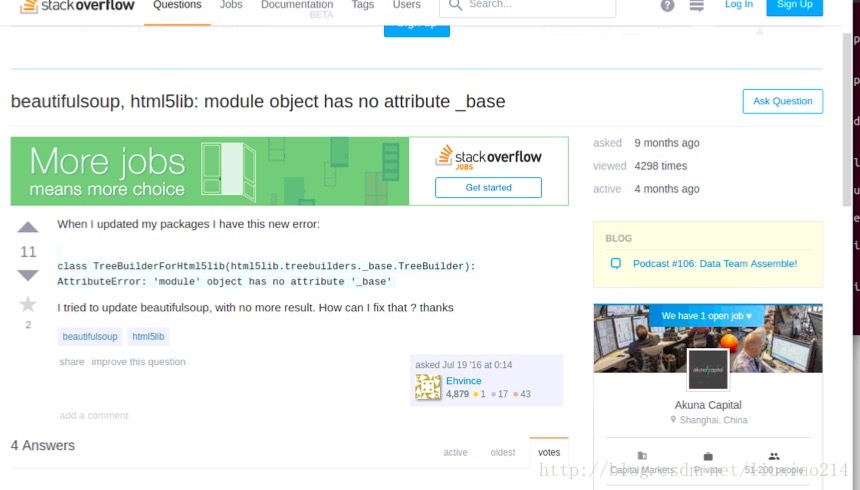
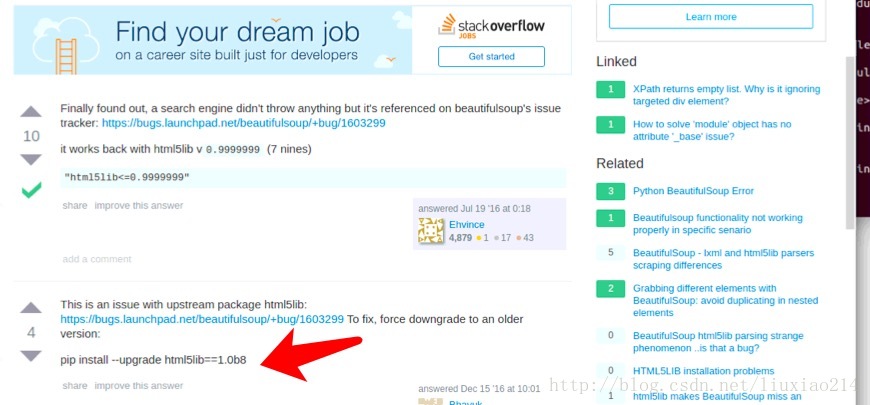
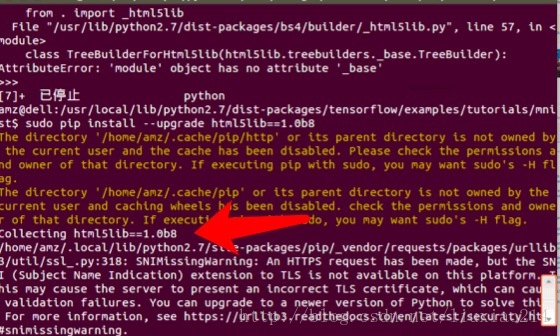

—–模組匯入終於成功了,第二句程式碼,又又又出錯了。IOError: [Errno socket error] [Errno110][Connecton timed out]如下:
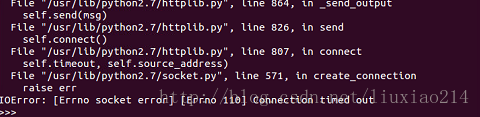
—–這時不要怕,外國網站嘛,總有那麼幾次連不上,多試幾次,就可以了。成功結果如下:
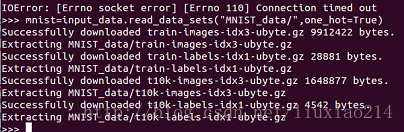
—–這個資料集分成三部分,55000個數據點用來訓練資料(mnist.train),10000個點用來測試資料(mnist.test),5000個點用來驗證資料(mnist.validation),這種切分很重要:這在機器學習中很有效率,我們分開我們不需要學習的資料,這樣確保我們真正學到了泛化。
—–正如前面提到的,每個MNIST資料點有兩個部分,一個手寫數字的影象和與之相關的標籤,我們可以稱影象為x,標籤為y。訓練集和測試集都包含了影象和與之相關的標籤,例如訓練集的影象是mnist.train.images,訓練標籤是mnist.train.labels。
—–每張影象都是28x28畫素的,我們可以用一個數字陣列來表示這張影象。
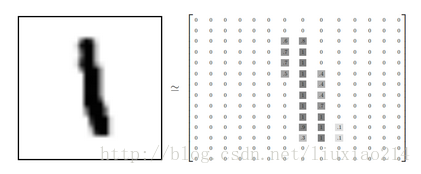
—–我們把這個陣列展開成一個向量,長度是28x28=784。如何展開這個陣列並不重要,只要保持每個影象展開的方式一樣就可以。從這個角度看,MNIST影象就是784維向量空間中的一堆點,並且有比較複雜的結構。(警告:計算密集型視覺化)
—–展開影象數字陣列會丟失影象二維結構的資訊,這顯然不好,最好的計算機視覺方法挖掘並利用這些資訊,我們會在稍後的教程中提到。但是,我們在這裡用的簡單的方法,softmax regression(後面會給出定義),不會利用這些結構資訊。
—–在MNIST訓練資料集上,mnist.train.images是一個形狀為[55000,784]的tensor(一個n維陣列)。第一個維度是用來索引影象列表中影象的位置,第二個維度是索引每個影象中的每個畫素點。在這個tensor中的每個元素,表示某個某影象中的某個畫素點的強度值,在0和1之間。
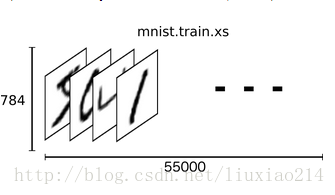
—–在MNIST中的每個影象都有一個與之對應的標籤,用0到9的數字描述影象中代表的數字。
—–為了用於這個教程,我們希望我們的標籤都是one-hot vectors形式的,一個one-hot向量除了某一個維度是1以外,其他維度都是0。所以在這種情況下,數字n表示成一個只有在第n維度(從0開始)數字為1的10維向量。例如,數字3的向量表示為[0,0,1,0,0,0,0,0,0,0]。因此,mnist.train.labels是一個 [55000, 10]的數字矩陣。
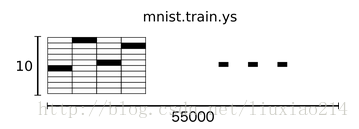
—–現在,我們開始真正構造我們的模型。
3、softmax迴歸
—–我們知道MNIST中的每個影象都是0到9之間的一個手寫數字,因此給定一個影象,只有10中可能性。我們希望做到的是,看到一張影象,我們給出是每個數字的可能性大小。例如,我們的模型可能看到一張手寫數字是9的影象,有80%的概率確定它是9,有5%的概率確定它是8(因為8和9都有相同的上半部分:小圈),然後是給更小的概率確定它是其他數字。
—–這是使用softmax regression(一個自然簡單的模型)一個經典的案例。如果你想給一個物件假定是其他幾個不同事物的概率,softmax模型就可以做到,因為softmax給我們一個0到1之間的值的列表,這些值加起來剛好是1。即使是後面我們訓練更為複雜的模型時,最後一層也是用到了softmax層。
—–softmax regression分為兩步:第一步我們把我們的輸入影象是某個特定數字類別的證據加起來,第二步將這個證據轉化成概率。
—–首先第一步,為了得到給定一張影象是某個特定數字類別的證據,對每個畫素值進行加權求和,如果這個畫素有很高的強度說明這個影象不屬於該類,則這個權值是負數,相反,如果這個畫素能夠有力地證明這個影象屬於該類,則權值為正數。
—–下面的圖片展示了模型學習到的每一個畫素對應特定數字類的權值。紅色代表負數權值,藍色代表正數權值。

—–我們也添加了一些額外的證據稱之為偏置值(bias),基本上,我們是想有能力說,有些事情是更獨立於輸入的,即輸入往往會帶有一些干擾量。對於給定輸入影象x,它是數字類別i的證據結果是:
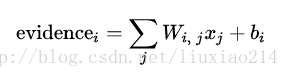
—–在這裡,Wi表示類i的權值,bi表示類i的偏置值,j表示對給定輸入影象x的畫素求和的索引,然後我們利用softmax函式將這個證據轉換成我們預測的概率y:
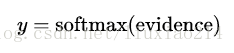
—–在這裡softmax可以看做成一個激勵函式或者連線函式,把我們線性函式的輸出轉化成我們想要的形式,也就是關於10個數字類的概率分佈。你可以這樣想,將證據轉化成我們的輸入是某個數字類的概率。這個softmax函式這樣定義:
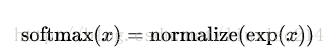
—–如果你展開等式右邊的式子,你可以得到:
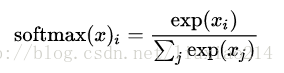
—–但是把softmax定義成前一種形式更有用:把輸入值當成冪指數求值,再正則化這些結果值。這個冪運算表示,更大的證據對應於更大的假設模型裡面的乘數權重值。反之,擁有更少的證據表示假設模型裡面擁有更小的乘數係數。假設模型裡的權值不可以是0和負數。接著,softmax正則化這些權值,使他們加起來是1,構造一個有效的概率分佈。
—–你可以用下面的圖來理解softmax regression。對於大量的輸入x,對x進行加權求值,再加上偏置值,得到的輸出作為softmax函式的輸入:
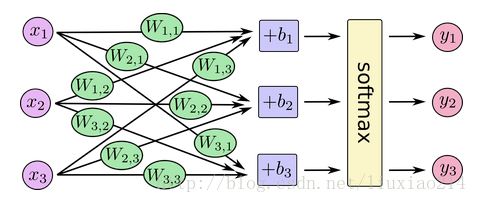
—–如果我們把它寫成一個等式,我們會得到:
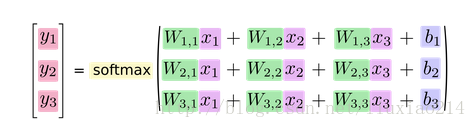
—–我們可以向量化這個過程,用矩陣乘法和向量相加。這有助於提高計算效率。(也是一種更有效的思考方式)
—–更進一步,我們可以寫成:
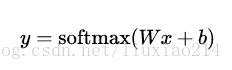
—–現在,把這些轉換成tensorflow可以使用的東西。
4、實現迴歸
—–為了在Python中做更有效的數字計算,我們經常會使用函式庫,如NumPy,來做一些複雜的操作,如使用非Python語言用更有效的程式碼來計算矩陣乘法。不幸的是,從外部運算切換回Python仍然是一個巨大的開銷。如果你想用GPU計算,開銷會更大,如果使用分散式計算,也會花費大量資源傳輸資料。
—–tensorflow把複雜的計算放在Python之外來完成,為了避免前面所說的開銷也做了進一步的改善。並不是在Python之外單獨執行單一複雜的操作,tensorflow先讓我們用圖來描述一系列可互動的操作,然後最後全部一起在Python之外執行。(這種類似的運作方式在不少機器學習庫中可以看到)
—–為了使用tensorflow,首先我們需要匯入它,如下:
import tensorflow as tf—–我們通過操作符號變數來描述這些可互動操作,例如,建立一個:
x = tf.placeholder(tf.float32,[None,784])—–x不是一個特定的值,而是一個佔位符placeholder,當我們用tensorflow計算時我們來輸入這個值。我們希望可以輸入任意數量的MNIST影象,每一個圖都被展開成784維的向量。我們用2維的浮點數tensor來表示這些圖,這個tensor的形狀是[None, 784]。(Node表示這個tensor的第一個維度可以是任意長度)
—–我們的模型也需要權重和偏置值,我們可以想象,把訓練這些當成額外的輸入,但是tensorflow有更好的辦法去處理它:Variable。一個Variable代表一個可修飾的tensor,存在於tensorflow中用於描繪可互動操作的圖中。在計算中可以被使用,甚至被修改。在機器學習應用中,一般會有的模型引數就是Variables。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))—–我們想通過tf.Variables賦予Variable不用的初值來建立不同的Variables:在這種情況下,我們用全為0的tensor來初始化W和b。因為我們還要學習W和b,所以如何初始化它們是無關緊要的。
—–注意到W的形狀是[784, 10],這是因為我們想要用784維的影象向量來乘以它以得到一個10維的證據向量,每一維對應不同的類別。b的形狀是[10],因此我們可以直接將他加在輸出上。
—–現在我們可以實現這個模型了,用下面的一行程式碼:
y = tf.nn.softmax(tf.matmul(x,w)+b)—–首先我們用tf.matmul(x,w)來表示將x與W乘起來。對應於之前方程式中的乘法Wx,這裡的x是一個擁有多個輸入的2維tensor。我們接著再加上b把它應用到tf.nn.softmax中。
—–至此,我們只用了一行程式碼來定義模型,幾行程式碼來設定變數。這是因為tensorflow的設計不僅使得softmax regression變得特別簡單,而且使用特別靈活的方式來描述其他各種類別的數值運算,從機器學習模型到物理模擬模型。一旦被定義好,我們的模型就可以在不同的裝置上執行:計算機的GPU,CPU,甚至是手機。
5、訓練
—–為了訓練我們的模型,我們需要定義一個指標來表示模型的好壞。實際上,在機器學習中,這個指標稱之為cost或者loss,這代表著我們的模型離理想輸出差距有多遠。我們要盡力最小化這個error,error矩陣越小,模型就越好。
—–一個定義模型loss非常常見,非常好的函式就是交叉熵(cross-entropy)。交叉熵產生於資訊理論中的資訊壓縮編碼技術,但後來成為從博弈論到機器學習很多領域中的重要技術手段,它定義為:
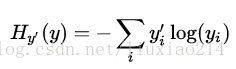
—–其中y就是我們預測的概率分佈,y’是真正的分佈(帶有數字標籤的one-hot向量)。比較粗糙的理解起來,交叉熵是用來衡量我們的預測用於描述真相的低效性。更詳細的關於交叉熵的介紹超出本教程,最好參考understanding。
—–為了實現交叉熵,我們需要一個新的佔位符來輸入正確答案:
y_ = tf.placeholder(tf.float32,[None,10])—–接著,我們需要實現交叉熵函式,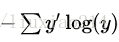
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices=[1]))—–首先,tf.log計算y每個元素的對數,接著我們把y’中的每個元素和tf.log(y)對應的每個元素相乘。然後tf.reduce_sum將y的第二維的每個元素加起來,這是因為reduction_indices=[1]。最後,tf.reduce_mean計算同批次中所有例子的平均值。
—–(注意到原始碼中,我們並不用這個計算公式,這是因為用數字表示不穩定,實際上我們用tf.nn.softmax_cross_entropy_with_logits來處理非規格化對數(例如我們呼叫softmax_cross_entropy_with_logits來處理tf.matmul(x, W) + b)),這是因為用內部計算softmax激勵更數字穩定。在你的程式碼中,考慮使用tf.nn.(sparse_)而不是softmax_cross_entropy_with_logits。)
——現在已經知道我們想要模型做什麼,這很容易用tensorflow來訓練它。因為tensorflow知道你整個計算圖,它可以自動的使用後向傳播演算法來有效地決定你的variables是如何影響你想要最小化的那個loss。接著tensorflow會採用你選定的優化演算法來修改variables以減少loss。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)—–在這種情況下,我們要求tensorflow使用梯度下降法以0.5的學習速率來最下化交叉熵。梯度下降演算法是一個簡單的演算法,tensorflow通過調整variables的方向來最小化損失。但是tensorflow也提供了很多其他優化演算法,只要簡單的呼叫一行程式碼就可以使用其他的演算法。
—–tensorflow實際做的是,在後臺,它會在你的計算圖中新增一些操作用來實現反向傳播演算法和梯度下降演算法。然後它返回給你的只是一個單一的操作,當執行這個操作時,它利用梯度下降訓練模型,微調變數來減少損失。
—–現在,我們已經設定好模型來訓練。在我們執行之前做的最後一件事,我們必須建立一個操作來初始化之前建立的變數。注意這只是定義操作而不是執行它。
init = tf.global_variables_initializer()—–現在我們在一個會話中執行模型,並且執行初始化變數的操作。
sess = tf.Session()
sess.run(init)—–開始訓練模型,我們將迴圈訓練1000次。
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys})—–在迴圈的每一步中,從我們的訓練資料集中隨機獲取100個批處理資料點,我們用這些資料點來替代之前的佔位符作為引數執行train_step。
—–使用一小部分隨機資料進行訓練稱為隨機訓練,在這裡,更確切的說是隨機梯度下降訓練。理想情況下,我們希望用所有資料來進行每一步訓練,因為這樣能給我們很好的訓練結果,但開銷太大了。因此每次我們使用不同的子資料集,這樣做可以減少開銷,並且最大化地做到一樣好。
6、評估模型
—–我們的模型做的怎麼樣?
—–首先,找出那些我們預測到的正確標籤。tf.argmax是一個非常有用的函式,它能給出某個tensor實體在某一維上面數值最大的值的下標也就是索引值。例如,tf.argmax(y,1)是我們的模型認為的對每一個輸入最接近的標籤,tf.argmax(y_,1)是真正的標籤,我們可以用tf.equal來檢查我們預測的是否符合事實(由於標籤向量就是由0、1構成的,最大值的下標也就是1所在的下標,而1的下標就是標籤)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))—–這行程式碼會給我們一組布林值,為了確定正確預測項的比例,我們把布林值轉化為浮點數,然後取平均值。例如,[True, False, True, True]將變成[1,0,1,1],平均值是0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))—–最終,在我們測試資料集上獲取正確率:
print(sess.run(accuracy,feed_dict={x:mnist.test.images, y_:mnist.test.labels}))—–最終結果應該是大約92%。
—–這是好的嗎?事實上,並不是,這非常差。這是因為我們用了一個非常簡單的模型。做一些小的改進,我們就可以達到97%。最好的模型可以達到99.7%的準確度(更多資訊可以點選list of results)。
—–更重要的是我們從這個模型中學到什麼。如果你對這個結果感到失望,下一個教程我們將做的更好,用tensorflow構建更加複雜的模型。
7、實際執行
—–以上,最終實際執行程式碼和結果如下:
—–第一次嘗試:
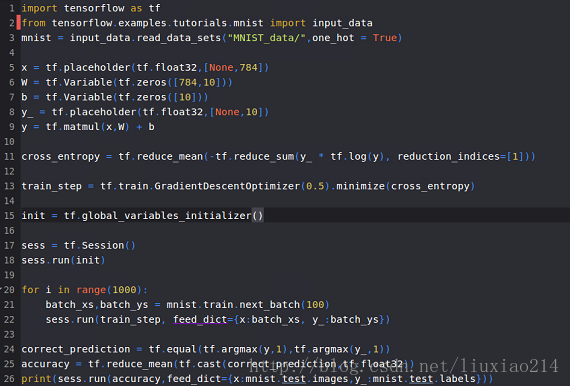
——結果,正確率,呵呵呵:
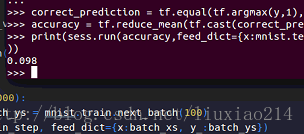
——不敢相信,查看了官網程式碼後發現,自己用了不穩定的計算交叉熵的方法,要用內部計算函式,於是,改動:
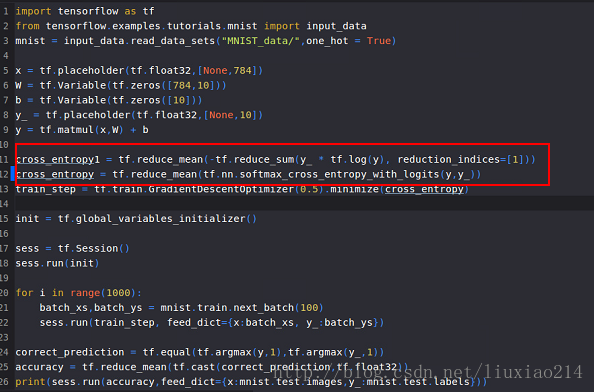
—–這裡出現一個問題,ValueError: Only call softmax_cross_entropy_with_logits with named arguments (labels=…, logits=…, …),如下:
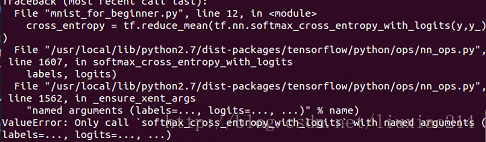
—–這是由於沒有指定引數名的原因,改正如下:
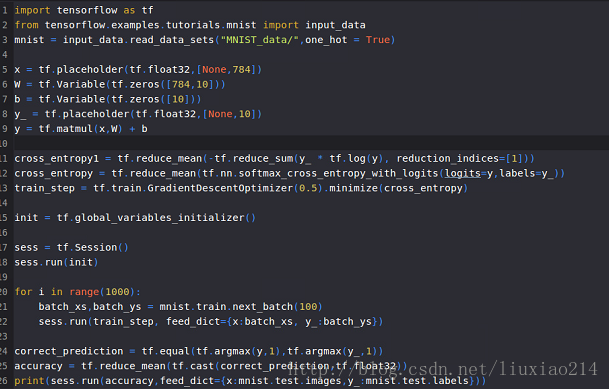
—–最後執行結果:
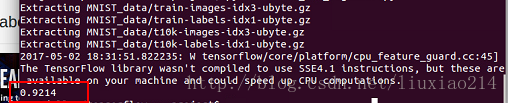
——以上,終於跑完第一個例程。
相關推薦
TensorsFlow學習筆記3----面向機器學習初學者的MNIST教程(MNIST For ML Beginners)
記錄關鍵內容與學習感受。未完待續。。 面向機器初學者的MNIST教程(MNIST For ML Beginners) —–適用於對機器學習和tensorflow初學者。而這裡MNIST就好比學語言時候的列印hello world。 —–MNIS
TensorFlow官方教程學習筆記之2-用於機器學習初學者學習的MNIST資料集(MNIST For ML Beginners)
1.資料集 MNIST是機器視覺入門級的資料集 2.演算法 1)核心 迴歸(Regression)演算法: 2)代價函式 交叉熵(cross-entropy): 3)優化 梯度下降法 3.程式碼 # Copyright 2
斯坦福2014機器學習筆記七----應用機器學習的建議
訓練集 image 是的 bsp 推斷 學習曲線 正則 偏差 wid 一、綱要 糾正較大誤差的方法 模型選擇問題之目標函數階數的選擇 模型選擇問題之正則化參數λ的選擇 學習曲線 二、內容詳述 1、糾正較大誤差的方法 當我們運用訓練好了的模型來做預測時
吳恩達機器學習筆記 —— 11 應用機器學習的建議
切分 image 們的 正則化 如果 mage 樣本 獲得 建議 http://www.cnblogs.com/xing901022/p/9356783.html 本篇講述了在機器學習應用時,如何進行下一步的優化。如訓練樣本的切分驗證?基於交叉驗證的參數與特征選擇?在訓
機器學習筆記(一)初識機器學習
機器學習:目前沒有統一的定義 現有定義: 1.samuel(1950): 在沒有明確設定的情況下,使計算機具有學習能力。 2.TOM(更新的定義):計算機程式從經驗E(Experience)中學習,解決某一任務T(Task),進行某一效能度量P(Performance),通過P測定在T上的表現因經驗
【機器學習--學習筆記】大規模機器學習
此處對比批量梯度下降、隨機梯度下降、小批量梯度下降演算法的優缺點 演算法 批量梯度下降(Batch Gradient Descent, BGD) 隨機梯度下降(Stochastic Gradient Descent, SGD)
機器學習筆記1:機器學習定義與分類
機器學習定義與分類 Andrew Ng機器學習課程學習筆記1 定義 Arthur Samuel (1959) Machine Learning: Field of study that gives computers the ability to l
機器學習筆記10——應用機器學習演算法的建議
目前,我們對機器學習的演算法也有了一定的瞭解,這一節將會給大家一些建議,關於如何有效的使用機器學習演算法。對於相同的演算法,不同的人會使其發揮不同的效果,所以,這一節的主題就是教大家如何用機器學習演算法解決具體問題。 主要內容 學習演算法的除錯診斷方法
機器學習筆記1:機器學習的動機與應用
目標:機器學習有意義;機器學習的應用;所有人有能力進行機器學習的研究。 預備知識:隊、列、二叉樹、線性代數 預備軟體:Octave、Matlab 機器學習:1959年由Arthur提出:在不直接對對問題賦予計算機學習能力的一個領域。寫一個下棋,和自己下棋,程式自己和自己
吳恩達機器學習筆記 —— 18 大規模機器學習
本章講了梯度下降的幾種方式:batch梯度下降、mini-batch梯度下降、隨機梯度下降。也講解了如何利用mapreduce或者多cpu的思想加速模型的訓練。 有的時候資料量會影響演算法的結果,如果樣本資料量很大,使用梯度下降優化引數時,一次調整引數需要計算全量的樣本,非常耗時。 如果訓練集和驗證集
學習筆記:楊輝三角形上莫隊(組合數莫隊)(LULU胡策)
與唐林康的決戰在即,麵筋哥需要一件壓場子的終極武器。 麵筋哥手上有 M 個麵筋,能量值分別為 1-M 的整數。現在麵筋哥想要利用這些麵筋制 作他的終極武器:Ex 麵筋棒。Ex 麵筋棒是一種能夠發射強大劍氣的能量武器。它由一些面 筋按次序連線而成。Ex 麵筋棒可能會發射失敗,麵筋哥無法承受
Matlab中del2()函式學習筆記,邊緣點的處理詳細步驟(通過分析底層函式)
最近卡在離散拉普拉斯運算元del2這個函式上了,在網上查了好久,關於del2函式邊緣點的處理公式都不對(通過與del2函式結果驗證的),因為自己要用硬體加速演算法,碰巧有拉帕拉斯運算元,所以必須要知道每個點的具體運算。。。。 死磕了一個晚上
機器學習筆記(3):多類邏輯回歸
display images 可能 https 都沒有 -s labels 明顯 交叉 仍然是 動手學嘗試學習系列的筆記,原文見:多類邏輯回歸 — 從0開始 。 這篇的主要目的,是從一堆服飾圖片中,通過機器學習識別出每個服飾圖片對應的分類是什麽(比如:一個看起來
python 3.x 學習筆記9 (面向對象)
表現 技術發展 計算 多種實現 類方法 run spa col 對數 1.面向對象 面向對象是一種對現實世界理解和抽象的方法,是計算機編程技術發展到一定階段後的產物。 2.類(class): 一個類即是對一類擁有相同屬性的對象的抽象、藍圖、原型。在類中定義了這些
sklearn 學習筆記-3 機器學習理論基礎
本章主要知識點: 過擬合和欠擬合的概念 模型的成本及成本函式的含義 評價一個模型的好壞的標準 學習曲線,以及用學習曲線來對模型進行診斷 通用模型優化方法 其他模型評價標準 ##3.1過擬合和欠擬合 過擬合就是模型能很好的擬合訓練樣
機器學習筆記(3) 隨機森林
random forest 和 extra-trees是對decison tree做ensemble而得到最終模型的兩種演算法. 閱讀本文前需要先了解一下 機器學習筆記1:決策樹 機器學習筆記2:整合學習 random_forest 決策樹在節點劃分上,在隨機的特徵子集中尋找最優劃分
深入理解Java虛擬機器學習筆記3-執行緒安全和鎖優化
併發處理是壓榨計算機運算能力最有力的工具。 1.執行緒安全 當多個執行緒訪問一個物件時,如果不用考慮這些執行緒執行時環境下排程和交替執行,也不需要進行額外的同步,或者在呼叫方進行任何其他的協調操作,呼叫這個物件的行為都可以獲取正確的結果,那麼這個物件是執行緒安全的。 2
機器學習筆記3:邏輯迴歸
機器學習筆記3:邏輯迴歸 Andrew Ng機器學習課程學習筆記3 邏輯迴歸就是分類問題,比如把郵件標示為垃圾郵件和正常郵件,判斷腫瘤是良性的還是惡性的. Sigmoid function 線性迴歸方程中,hθ(x) 的取值y是連續的,而邏輯迴歸中輸出則是離散的。以兩個類別
機器學習筆記(3):多類邏輯迴歸
仍然是 動手學嘗試學習系列的筆記,原文見:多類邏輯迴歸 — 從0開始 。 這篇的主要目的,是從一堆服飾圖片中,通過機器學習識別出每個服飾圖片對應的分類是什麼(比如:一個看起來象短袖上衣的圖片,應該歸類到T-Shirt分類) 示例程式碼如下,這篇的程式碼略複雜,分成幾個步驟解讀: 一、下載資料,並顯示圖
Stanford機器學習筆記-3.Bayesian statistics and Regularization
3. Bayesian statistics and Regularization Content 3. Bayesian statistics and Regularization. 3.1 Underfitting and overfitting. 3.2 Bayesian