
吳恩達機器學習筆記 —— 18 大規模機器學習
本章講了梯度下降的幾種方式:batch梯度下降、mini-batch梯度下降、隨機梯度下降。也講解了如何利用mapreduce或者多cpu的思想加速模型的訓練。
有的時候資料量會影響演算法的結果,如果樣本資料量很大,使用梯度下降優化引數時,一次調整引數需要計算全量的樣本,非常耗時。
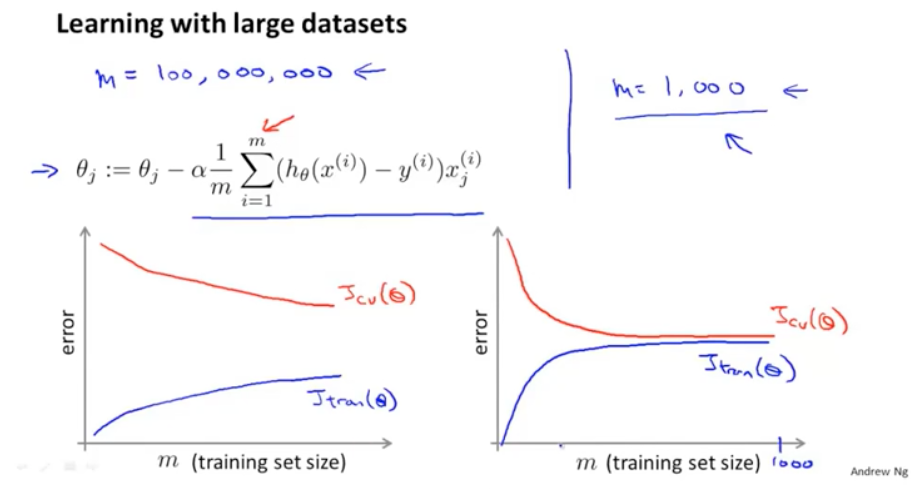
如果訓練集和驗證集的誤差像左邊的圖形這樣,就可以證明隨著資料量的增加,將會提高模型的準確度。而如果像右邊的圖,那麼增加樣本的數量就沒有什麼意義了。
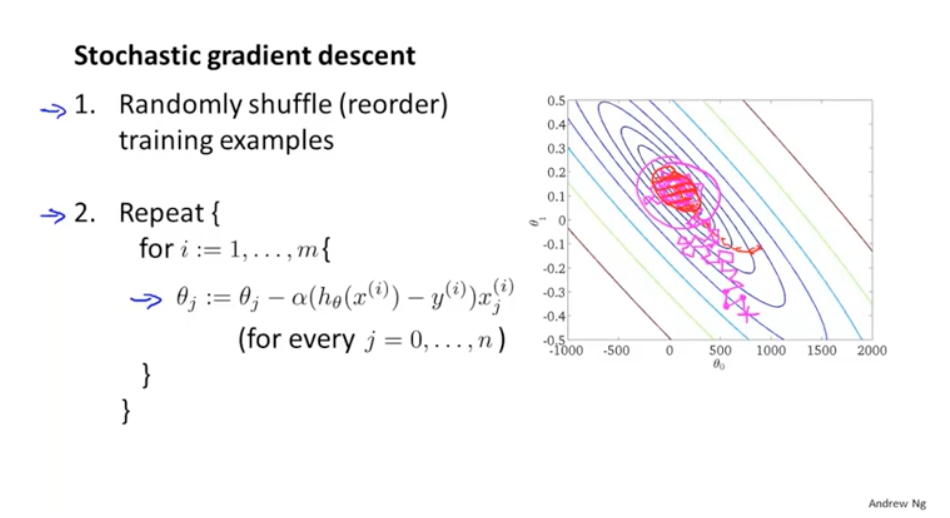
因此可以考慮縮小m的使用量,可以使用隨機梯度下降。隨機梯度下降的過程是:隨機打散所有的樣本,然後從第一個樣本開始計算誤差值,優化引數;遍歷所有的樣本。這樣雖然優化的方向比較散亂,但是最終還是會趨於最優解。
還有一種方式叫做小批量梯度下降,每次使用一小部分的資料進行驗證。比批量梯度下降更快,但是比隨機梯度下降更穩定。

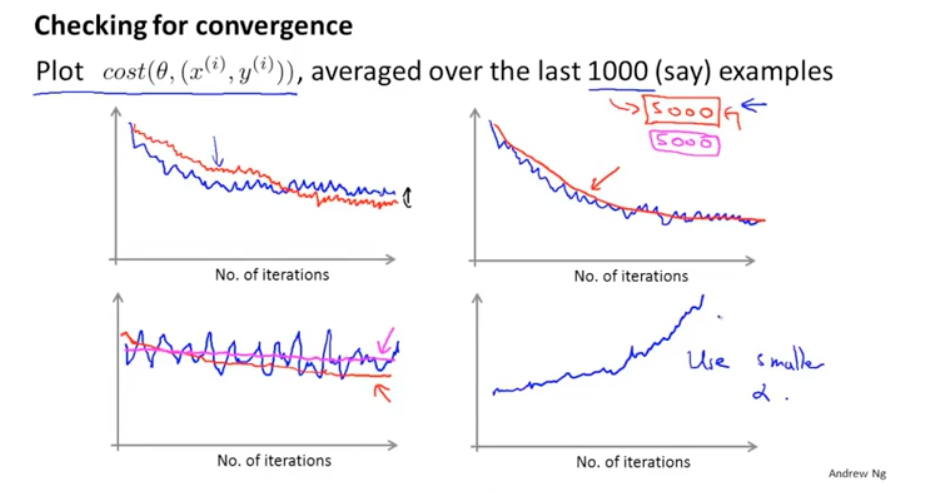
針對損失函式和batch的數量,可以畫出下面的圖:圖1的震盪曲線可以忽略,此時的震盪可能是由於區域性最小值造成的;圖2如果增加數量能使得曲線更平滑,那麼可以考慮增加batch的數量。圖3 可能是模型根本沒有在學習,可以考慮修改一下其他的引數。圖4可能是因為學習太高,可以使用更小的學習率。
線上學習就是隨著資料的獲取,增量的來當做每個batch進行訓練。
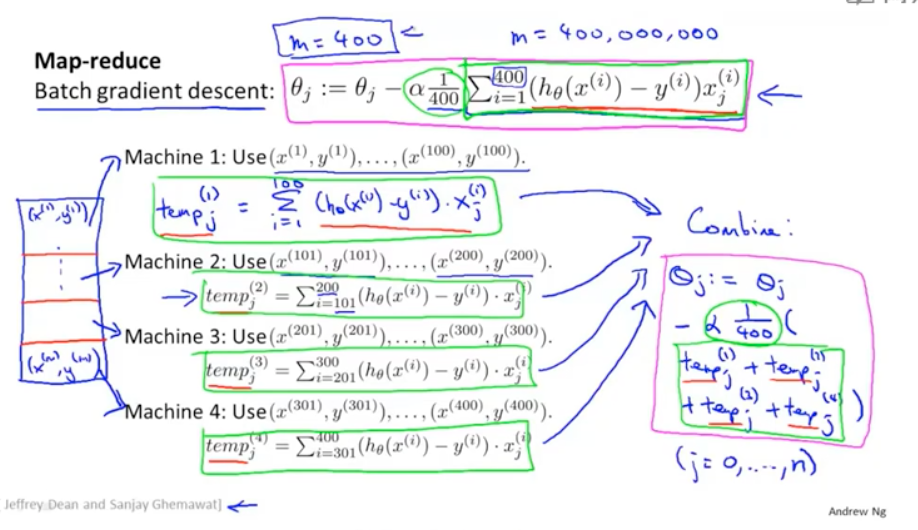
如果資料的樣本很大,其實也可以通過map reduce的方式來進行並行處理,比如把資料切分成很多塊,每個map執行完,統一在reduce端進行引數梯度下降學習。多CPU的情況下,也是同樣的道理。
相關推薦
吳恩達機器學習筆記 —— 18 大規模機器學習
本章講了梯度下降的幾種方式:batch梯度下降、mini-batch梯度下降、隨機梯度下降。也講解了如何利用mapreduce或者多cpu的思想加速模型的訓練。 有的時候資料量會影響演算法的結果,如果樣本資料量很大,使用梯度下降優化引數時,一次調整引數需要計算全量的樣本,非常耗時。 如果訓練集和驗證集
吳恩達(Andrew Ng)《機器學習》課程筆記(1)第1周——機器學習簡介,單變數線性迴歸
吳恩達(Andrew Ng)在 Coursera 上開設的機器學習入門課《Machine Learning》: 目錄 一、引言 一、引言 1.1、機器學習(Machine Learni
吳恩達(Andrew Ng)《機器學習》課程筆記(2)第2周——多變數線性迴歸
目錄 四、多變數線性迴歸(Linear Regression with multiple variables) 4.1. 多維特徵(Multiple features) 前面介紹的是單變數線性迴歸如下圖所示:
吳恩達第一門-神經網路和深度學習第二週6-10學習筆記
神經網路和深度學習第二週6-10學習筆記 6.更多導數的例子 在本節中,為上一節的導數學習提供更多的例子。在上一節中,我們複習了線性函式的求導方法,其導數值在各點中是相等的。本節以y=a^2這一二次函式為例,介紹了導數值在各點處發生變化時的求導方法。求導大家都會,y=x ^3的導數是
吳恩達第一門-神經網路和深度學習第三週6-10學習筆記
吳恩達第一門-神經網路和深度學習第三週6-10學習筆記 3.6啟用函式 啟用函式 圖中給出了前面課程中所學到的利用神經網路計算輸出值的具體步驟。其中的 σ
資源 | Hinton、LeCun、吳恩達......不容錯過的15大機器學習課程都在這兒了
翻譯 | AI科技大本營參與 | 劉暢編輯 | Donna連結:http://www.cs.to
吳恩達deepLearning.ai迴圈神經網路RNN學習筆記_看圖就懂了!!!(理論篇)
前言 目錄: RNN提出的背景 - 一個問題 - 為什
吳恩達deepLearning.ai迴圈神經網路RNN學習筆記_沒有複雜數學公式,看圖就懂了!!!(理論篇)
本篇文章被Google中國社群組織人轉發,評價: 條理清晰,寫的很詳細! 被阿里演算法工程師點在看! 所以很值得一看! 前言 目錄: RNN提出的背景 &nbs
吳恩達實驗(神經網絡和深度學習)第一課第三周,代碼和數據集,親測可運行
HR tps size nac www cond -c 自己 c-c 代碼和數據集已上傳到文件中 應該可以直接下載吧(第一次上傳文件,感覺是),解壓後把文件夾拷貝到jupyter工作空間即可 註:我對下載的代碼的格式稍作了修改,原來定義函數與調用函數在兩個單元格裏,我直
【機器學習--學習筆記】大規模機器學習
此處對比批量梯度下降、隨機梯度下降、小批量梯度下降演算法的優缺點 演算法 批量梯度下降(Batch Gradient Descent, BGD) 隨機梯度下降(Stochastic Gradient Descent, SGD)
吳恩達DeepLearning.ai筆記(5-1)-- 迴圈序列模型
吳恩達DeepLearning.ai筆記(5-1)– 迴圈序列模型 1.一些序列資料例子 2.數學符號 x<1>x<1>輸入序列X第一個單詞,TixTxi輸入序列X的單詞個數,X(i)<t>X(i)&l
吳恩達DeepLearning.ai筆記(1-4)-- 深層神經網路
神經網路和深度學習—深層神經網路1.深度網路中的前向傳播2. 核對矩陣的維度DNN結構示意圖如圖所示:對於第L層神經網路,單個樣本其各個引數的矩陣維度為:W[l]:(n[l],n[l−1])b[l]:(n[l],1)dW[l]:(n[l],n[l−1])db[l]:(n[l]
吳恩達deep learning筆記第二課 改善深層神經網路:超引數除錯、正則化以及優化
學習吳恩達DL.ai第二週視訊筆記。 1.深度學習實用層面 在訓練集和驗證集來自相同分佈的前提下,觀察訓練集的錯誤率和驗證集的錯誤率來判斷過擬合(high variance高方差)還是欠擬合(high bias高偏差). 比如訓練集錯誤率1%,驗證集11%則過擬合(
【吳恩達deeplearning.ai筆記二】通俗講解神經網路上
神經網路(Neural Network)的構築理念是受到生物神經網路功能的運作啟發而產生的。人工神經網路通常是通過一個基於數學統計學型別的學習方法得以優化,所以人工神經網路也是數學統計學方法的一種實際應用。和其他機器學習方法一樣,神經網路已經被用於解決各種各樣的問題,例如機器
Hadoop學習筆記—18.Sqoop框架學習
max lec sql數據庫 creat rec apt 成功 不同的 mysql數據庫 一、Sqoop基礎:連接關系型數據庫與Hadoop的橋梁 1.1 Sqoop的基本概念 Hadoop正成為企業用於大數據分析的最熱門選擇,但想將你的數據移植過去並不容易。Apa
吳恩達機器學習筆記18-多類別分類:一對多(Multiclass Classification_ One-vs-all)
預測 分類器 -s 多個 不同的 一對多 直線 問題 com 對於之前的一個,二元分類問題,我們的數據看起來可能是像這樣: 對於一個多類分類問題,我們的數據集或許看起來像這樣: 我用3 種不同的符號來代表3 個類別,問題就是給出3 個類型的數據集,我們如何得
Coursera 深度學習 吳恩達 deep learning.ai 筆記整理(3-2)——機器學習策略
新的 bsp 誤差 spa 歸納 空間 font 處理 整理 一、誤差分析 定義:有時我們希望算法能夠勝任人類能做的任務,但是當算法還沒達到人類所預期的性能時,人工檢查算法錯誤會讓你知道接下來做什麽,這也就是誤差分析 檢查,發現會把夠狗當恒,是否需要做一個項目專門處理狗
吳恩達“機器學習”——學習筆記二
最大似然 數據 learning 模型 ima 我們 回歸 eps 而是 定義一些名詞 欠擬合(underfitting):數據中的某些成分未被捕獲到,比如擬合結果是二次函數,結果才只擬合出了一次函數。 過擬合(overfitting):使用過量的特征集合,使模型過於復雜。
吳恩達“機器學習”——學習筆記八
包含 找到 trade 經驗 這也 ... info 算法 不等式 偏差方差權衡(bias variance trade off) 偏差:如果說一個模型欠擬合,也可以說它的偏差很大。 方差:如果說一個模型過擬合,也可以說它的方差很大。 訓練誤差 經驗風險最小化(ERM)
【吳恩達機器學習】學習筆記——1.5無監督學習
分類 哪些 rep epm 朋友 工作 style class 客戶 1 無監督學習:在不知道數據點的含義的情況下,從一個數據集中找出數據點的結構關系。 2 聚類算法:相同屬性的數據點會集中分布,聚集在一起,聚類算法將數據集分成不同的聚類。也就是說,機器不知道這些數據點具體