
利用KD樹進行異常檢測
什麼是KD樹
要說KD樹,我們得先說一下什麼是KNN演算法。
KNN是k-NearestNeighbor的簡稱,原理很簡單:當你有一堆已經標註好的資料時,你知道哪些是正類,哪些是負類。當新拿到一個沒有標註的資料時,你想知道它是哪一類的。只要找到它的鄰居(離它距離短)的點是什麼類別的,所謂近朱者赤近墨者黑,KNN就是採用了類似的方法。
如上圖,當有新的點不知道是哪一類時,只要看看離它最近的幾個點是什麼類別,我們就判斷它是什麼類別。
舉個例子:我們將k取3(就是每次看看新來的資料點的三個住的最近的鄰居),那麼我們將所有資料點和新來的資料點計算一次距離,然後排序,取前三個資料點,讓它們舉手表決。兩票及以上的類別我們就認為是新的資料點的類別。
很簡單也很好的想法,但是,我們要注意到當測試集資料比較大時,由於每次未標註的資料點都要和全部的已標註的資料點進行一次距離計算,然後排序。可以說時間開銷非常大。我們在此基礎上,想到了一種儲存點與點之間關係的演算法來通過空間換時間。
有一篇博文寫KD樹還不錯
點選此處檢視
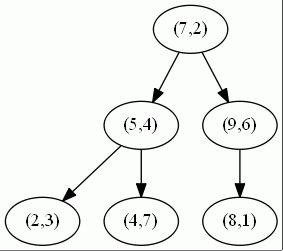
舉個例子:有一個二維的資料集: T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
通過你已經學習的KD樹的演算法,按照依次選擇維度,取各維中位數,是否得出和下面一樣的KD樹?
異常檢測
我們的資料來自於KDD Cup 1999 Data 點我下載資料
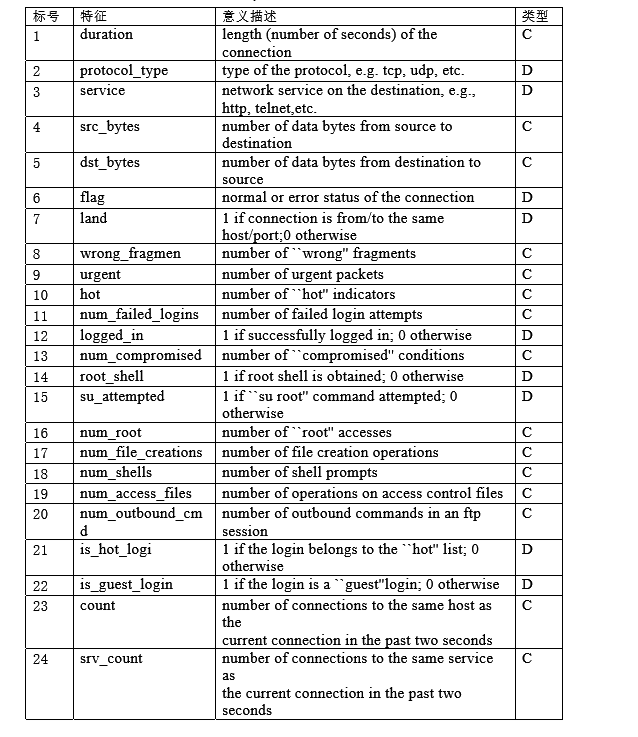
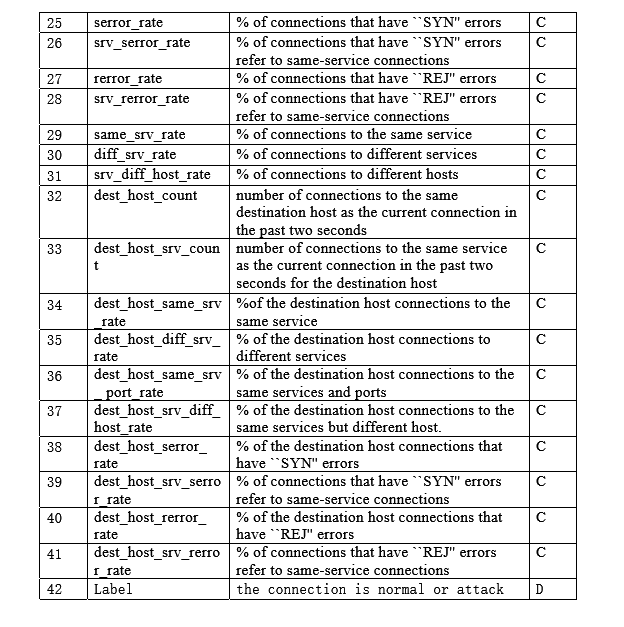
資料格式如下圖

資料的含義如下:
我們這次實驗針對正常和DDOS攻擊兩種情況進行檢測。
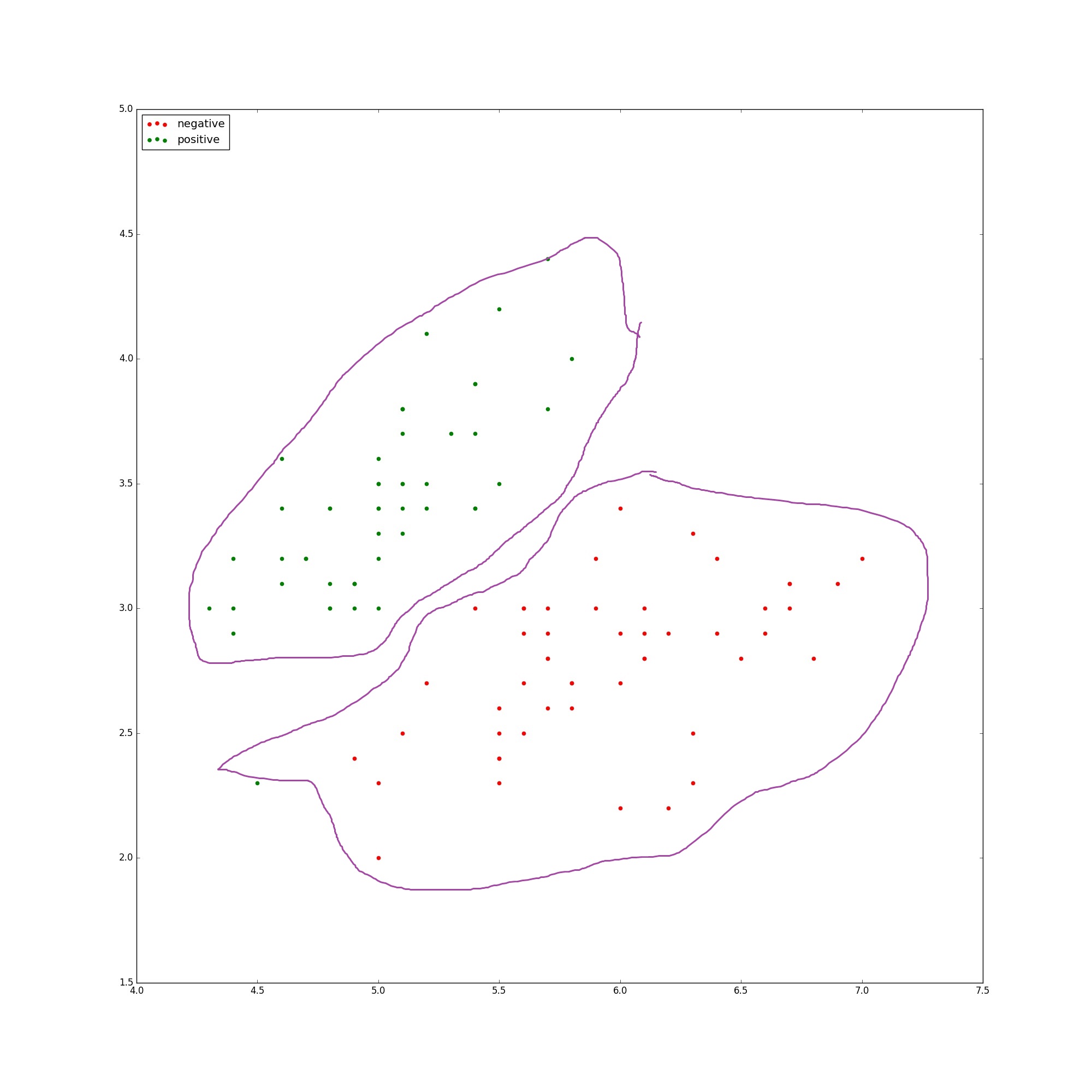
取特徵範圍為(1,9)U(22,31)的特徵中的數值型特徵,最終得到16維的特徵向量。將資料隨機化處理後按照7:3的比例分成訓練集和測試集。下面是我們組做好的訓練集和測試集
處理完的訓練集和測試集如下圖:

下面是具體實現:
# coding=utf8 import math import time import matplotlib.pyplot as plt import numpy as np old_settings = np.seterr(all='ignore') #定義節點型別 class KD_node: def __init__(self, point=None, split=None, left=None, right=None): ''' :param point: 資料點的特徵向量 :param split: 切分的維度 :param left: 左兒子 :param right: 右兒子 ''' self.point = point self.split = split self.left = left self.right = right
計算方差,以利用方差大小進行判斷在哪一維進行切分
def computeVariance(arrayList):
'''
:param arrayList: 所有資料某一維的向量
:return: 返回
'''
for ele in arrayList:
ele = float(ele)
LEN = float(len(arrayList))
array = np.array(arrayList)
sum1 = float(array.sum())
array2 = np.dot(array, array.T)
sum2 = float(array2.sum())
mean = sum1 / LEN
variance = sum2 / LEN - mean ** 2
return variance建樹
def createKDTree(root, data_list):
'''
:param root: 輸入一個根節點,以此建樹
:param data_list: 資料列表
:return: 返回根節點
'''
LEN = len(data_list)
if LEN == 0:
return
# 資料點的維度
dimension = len(data_list[0]) - 1 #去掉了最後一維標籤維
# 方差
max_var = 0
# 最後選擇的劃分域
split = 0
for i in range(dimension):
ll = []
for t in data_list:
ll.append(t[i])
var = computeVariance(ll) #計算出在這一維的方差大小
if var > max_var:
max_var = var
split = i
# 根據劃分域的資料對資料點進行排序
data_list = list(data_list)
data_list.sort(key=lambda x: x[split]) #按照在切分維度上的大小進行排序
data_list = np.array(data_list)
# 選擇下標為len / 2的點作為分割點
point = data_list[LEN / 2]
root = KD_node(point, split)
root.left = createKDTree(root.left, data_list[0:(LEN / 2)])#遞迴的對切分到左兒子和右兒子的資料再建樹
root.right = createKDTree(root.right, data_list[(LEN / 2 + 1):LEN])
return rootdef computeDist(pt1, pt2):
'''
:param pt1: 特徵向量1
:param pt2: 特徵向量2
:return: 兩個向量的歐氏距離
'''
sum_dis = 0.0
for i in range(len(pt1)):
sum_dis += (pt1[i] - pt2[i]) ** 2
#實現的歐氏距離計算,效率很低的版本,可以改成numpy的向量運算
return math.sqrt(sum_dis)
def findNN(root, query):
'''
:param root: 建立好的KD樹的樹根
:param query: 查詢資料
:return: 與這個資料最近的前三個節點
'''
# 初始化為root的節點
NN = root.point
min_dist = computeDist(query, NN)
nodeList = []
temp_root = root
dist_list = [temp_root.point, None, None] #用來儲存前三個節點
##二分查詢建立路徑
while temp_root:
nodeList.append(temp_root) #對向下走的路徑進行壓棧處理
dd = computeDist(query, temp_root.point) #計算當前最近節點和查詢點的距離大小
if min_dist > dd:
NN = temp_root.point
min_dist = dd
# 當前節點的劃分域
temp_split = temp_root.split
if query[temp_split] <= temp_root.point[temp_split]:
temp_root = temp_root.left
else:
temp_root = temp_root.right
##回溯查詢
while nodeList:
back_point = nodeList.pop()
back_split = back_point.split
if dist_list[1] is None:
dist_list[2] = dist_list[1]
dist_list[1] = back_point.point
elif dist_list[2] is None:
dist_list[2] = back_point.point
if abs(query[back_split] - back_point.point[back_split]) < min_dist:
#當查詢點和回溯點的距離小於當前最小距離時,另一個區域有希望存在更近的節點
#如果大於這個距離,可以理解為假設在二維空間上,直角三角形的直角邊已經不滿足要求了,那麼斜邊也一定不滿足要求
if query[back_split] < back_point.point[back_split]:
temp_root = back_point.right
else:
temp_root = back_point.left
if temp_root:
nodeList.append(temp_root)
curDist = computeDist(query, temp_root.point)
if min_dist > curDist:
min_dist = curDist
dist_list[2] = dist_list[1]
dist_list[1] = dist_list[0]
dist_list[0] = temp_root.point
elif dist_list[1] is None or curDist < computeDist(dist_list[1], query):
dist_list[2] = dist_list[1]
dist_list[1] = temp_root.point
elif dist_list[2] is None or curDist < computeDist(dist_list[1], query):
dist_list[2] = temp_root.point
return dist_list進行判斷
def judge_if_normal(dist_list):
'''
:param dist_list: 利用findNN查找出的最近三個節點進行投票表決
:return:
'''
normal_times = 0
except_times = 0
for i in dist_list:
if abs(i[-1] - 0.0) < 1e-7: #浮點數的比較
normal_times += 1
else:
except_times += 1
if normal_times > except_times: #判斷是normal
return True
else:
return False資料預處理
def pre_data(path):
f = open(path)
lines = f.readlines()
f.close()
lstall = []
for line in lines:
lstn = []
lst = line.split(",")
u = 0
y = 0
for i in range(0, 9):
if lst[i].isdigit():
lstn.append(float(lst[i]))
u += 1
else:
pass
for j in range(21, 31):
try:
lstn.append(float(lst[j]))
y += 1
except:
pass
if lst[len(lst) - 1] == "smurf.\n" or lst[len(lst) - 1] == "teardrop.\n":
lstn.append(int("1"))
else:
lstn.append(int("0"))
lstall.append(lstn)
nplst = np.array(lstall, dtype=np.float16)
return nplst下面就是個人的測試程式碼了,大概運行了40分鐘才全跑完
def my_test(all_train_data, all_test_data, train_data_num):
train_data = all_train_data[:train_data_num]
train_time_start = time.time()
root = KD_node()
root = createKDTree(root, train_data)
train_time_end = time.time()
train_time = train_time_end - train_time_start
right = 0
error = 0
test_time_start = time.time()
for i in range(len(all_test_data)):
if judge_if_normal(findNN(root, all_test_data[i])) is True and abs(all_test_data[i][-1] - 0.0) < 1e-7:
right += 1
elif judge_if_normal(findNN(root, all_test_data[i])) is False and abs(all_test_data[i][-1] - 1.0) < 1e-7:
right += 1
else:
error += 1
test_time_end = time.time()
test_time = test_time_end - test_time_start
right_ratio = float(right) / (right + error)
return right_ratio, train_time, test_time
def draw(train_num_list=[10, 100, 1000, 10000], train_data=[], test_data=[]):
train_time_list = []
test_time_list = []
right_ratio_list = []
for i in train_num_list:
print 'start run ' + i.__str__()
temp = my_test(train_data, test_data, i)
right_ratio_list.append(temp[0])
train_time_list.append(temp[1])
test_time_list.append(temp[2])
plt.title('train data num from ' + train_num_list[0].__str__() + ' to ' + train_num_list[:-1].__str__())
plt.subplot(311)
plt.plot(train_num_list, right_ratio_list, c='b')
plt.xlabel('train data num')
plt.ylabel('right ratio')
plt.grid(True)
plt.subplot(312)
plt.plot(train_num_list, train_time_list, c='r')
plt.xlabel('train data num')
plt.ylabel('time of train data (s)')
plt.grid(True)
plt.subplot(313)
plt.plot(train_num_list, test_time_list, c='g')
plt.xlabel('train data num')
plt.ylabel('time of test data (s)')
plt.grid(True)
plt.show()
data = pre_data('KDD-test\ddos+normal_70.txt')
data2 = pre_data('KDD-test\ddos+normal_30.txt')
'''
建議開始將測試資料調小點,因為時間很長,下面這是全部訓練集和全部測試集,共花費了40分鐘才跑完。我是第六代i7 6700HQ+16G記憶體+1070+win10
'''
draw(train_num_list=[10, 100, 500, 1000, 2000, 3000, 5000, 10000, 15000, 20000, 50000, 100000, 265300],
train_data=data[:], test_data=data2[:])
跑完的效果如圖所示:
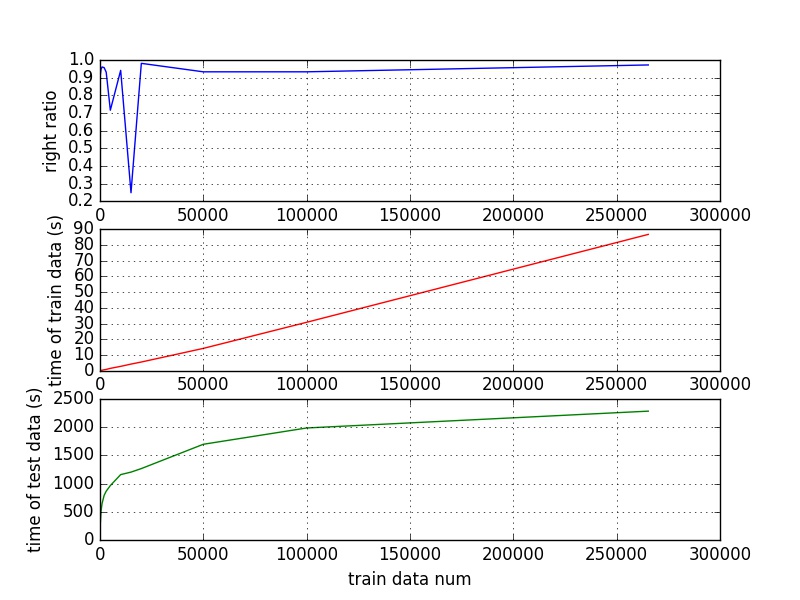
正確率最終達到95%以上。開始出現的波動我們懷疑是資料在開始沒有達到良好的隨機效果。
訓練時間與訓練資料量明顯成線性關係
測試時間確實和理論一致,是Nlog(M)的時間複雜度。應該說這種時間複雜度的降低是我們使用KD樹而不是原版的KNN最重要的地方。在原來的KNN演算法下,假設訓練集大小為M,測試集大小為N,則查詢時間複雜度可以達到O(MN),但是我們降低到O(Nlog(M)),還是挺合算的。
本次實驗可以優化的地方很多,但是時間匆忙,沒有做更深的擴充套件。歡迎大家提出更多建議。
相關推薦
利用KD樹進行異常檢測
什麼是KD樹 要說KD樹,我們得先說一下什麼是KNN演算法。 KNN是k-NearestNeighbor的簡稱,原理很簡單:當你有一堆已經標註好的資料時,你知道哪些是正類,哪些是負類。當新拿到一個沒有標註的資料時,你想知道它是哪一類的。只要找到它的鄰居(離它距離短)的點是什麼類別的,所謂近朱者赤近墨者黑,K
異常檢測: 應用多元高斯分布進行異常檢測
ron 適用於 fff 可能性 方差 評估 估計 變量 strong 多元高斯(正態)分布 多元高斯分布有兩個參數u和Σ,u是一個n維向量,Σ協方差矩陣是一個n*n維矩陣。改變u與Σ的值可以得到不同的高斯分布。 參數估計(參數擬合),估計u和Σ的公式如上圖所示,u為平均值
[吳恩達機器學習筆記]15非監督學習異常檢測7-8使用多元高斯分布進行異常檢測
進行 平均值 info 錯誤 blog 占用 ron 關系 http 15.異常檢測 Anomaly detection 覺得有用的話,歡迎一起討論相互學習~Follow Me 15.7-8 多變量高斯分布/使用多元高斯分布進行異常檢測 -Multivariate Gaus
CNN autoencoder 進行異常檢測——TODO,使用keras進行測試
mov ons pure exc gen fine rman ras note https://sefiks.com/2018/03/23/convolutional-autoencoder-clustering-images-with-neural-networks/ h
RPLIDAR雷達如何在到貨及返修前進行異常檢測?
為了防止因為操作流程失誤造成雷達失效及無用返修的這種情況,小編專門出一篇雷達自檢教程,供大家在雷達到貨及返修前進行初步檢測~ 首先,需要安裝檢測工具 —— RoboStudio。 RoboStudio下載連結 : http://www.slamtec.com/
2D空間中使用Quadtree四叉樹進行碰撞檢測優化
很多遊戲中都需要使用碰撞檢測演算法檢測兩個物體的碰撞,但通常這些碰撞檢測演算法都很耗時很容易拖慢遊戲的速度。這裡我們學習一下使用四叉樹來對碰撞檢測進行優化,優化的根本是碰撞檢測時跳過那些明顯離得很遠的物體,加快檢測速度。 【注:這裡演算法的實現使用的J
使用R語言進行異常檢測
本文結合R語言,展示了異常檢測的案例,主要內容如下: (1)單變數的異常檢測 (2)使用LOF(local outlier factor,區域性異常因子)進行異常檢測 (3)通過聚類進行異常檢測 (4)對時間序列進行異常檢測 單變數異常檢測 本部分展示了一個單變
利用OpenCV-python進行直線檢測
最近需要利用攝像頭對細小的偏移做矯正,由於之前的介面工具是用 PyQT 所寫,在當前的工具中加入攝像頭矯正程式,也打算用 python 直接完成。OpenCV 簡介:Python 處理影象有 OpenCV 庫。OpenCV 可以執行在 Linux,windows,macOS
利用Jenkins和SonarQube集成對代碼進行持續檢測
jenkins和sonarqubeJenkins與SonarQube 集成插件的安裝與配置Jenkins 是一個支持自動化框架的服務器,我們這裏不做詳細介紹。Jenkins 提供了相關的插件,使得 SonarQube 可以很容易地集成 ,登陸 jenkins,點擊"Manage Jenkins&qu
tensorflow利用預訓練模型進行目標檢測(一):預訓練模型的使用
err sync numpy sna sta porting trac git int32 一、運行樣例 官網鏈接:https://github.com/tensorflow/models/blob/master/research/object_detection/obje
【轉】Python+opencv利用sobel進行邊緣檢測(細節講解)
#! usr/bin/env python # coding:utf-8 # 2018年7月2日06:48:35 # 2018年7月2日23:11:59 import cv2 import numpy as np import matplotlib.pyplot as plt img = cv2
tensorflow利用預訓練模型進行目標檢測
一、安裝 首先系統中已經安裝了兩個版本的tensorflow,一個是通過keras安裝的, 一個是按照官網教程https://www.tensorflow.org/install/install_linux#InstallingNativePip使用Virtualenv 進行安裝的,第二個在根目錄下,做標記
利用Hog特徵和SVM分類器進行行人檢測
https://blog.csdn.net/qianqing13579/article/details/46509037 梯度直方圖特徵(HOG) 是一種對影象區域性重疊區域的密集型描述符, 它通過計算區域性區域的梯度方向直方圖來構成特徵。Hog特徵結合SVM分類器已經被廣
tensorflow利用預訓練模型進行目標檢測(二):將檢測結果存入mysql資料庫
mysql版本:5.7 ; 資料庫:rdshare;表captain_america3_sd用來記錄某幀是否被檢測。表captain_america3_d用來記錄檢測到的資料。 python模組,包部分內容參考http://www.runoob.com/python/python-modules.html&
tensorflow利用預訓練模型進行目標檢測(四):檢測中的精度問題以及evaluation
一、tensorflow提供的evaluation Inference and evaluation on the Open Images dataset:https://github.com/tensorflow/models/blob/master/research/object_detection/g
利用caffe和mxnet 開啟攝像頭,進行人臉檢測
# -*- coding:utf-8 -*- import random import mxnet as mx import numpy as np from sklearn import preprocessing import base64 import cv2 impo
【react】利用prop-types第三方庫對元件的props中的變數進行型別檢測
1.安裝:npm install prop-types --save 2.使用 import React, { Component } from 'react'; import PropTypes
利用迴歸樹對Boston房價進行預測,並對結果進行評估
from sklearn.cross_validation import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.tree import DecisionT
利用RGB-D資料進行人體檢測 People detection in RGB-D data
利用RGB-D資料進行人體檢測 LucianoSpinello, Kai O. Arras 摘要 人體檢測是機器人和智慧系統中的重要問題。之前的研究工作使用攝像機和2D或3D測距器。本文中我們提出一種新的使用RGB-D的人體檢測方法。我們從HOG( His
利用哈夫曼樹進行檔案壓縮
專案描述: 專案簡介:利用哈夫曼編碼的方式對檔案進行壓縮,並且對壓縮檔案可以解壓 開發環境:windows vs2013 專案概述: 1.壓縮 a.讀取檔案,將每個字元,該字元出現的次數和權值構成哈夫曼樹 b