
hadoop壓縮演算法的總結
1. 壓縮成為必須
對資料的3個關鍵特徵描述 3V:volume、variety和value。
volume,資料量與日俱增,在於智慧手機、Internet和感知器等的使用。
variety,大資料的資料格式,音訊、視訊、影象等。
value,資料近乎實時的產生以使得有用資訊能夠服務需要。
大資料不僅僅帶來了新的資料型別和儲存機制,也帶來了新種類的資料分析。現在資料增長太快了,資料的處理和管理成為一種挑戰,傳統的資料儲存和分析是低效的。在傳統資料和大資料之間存在不同,大資料面臨的挑戰包括資料的隱私和安全、資料儲存、從大資料中創造商業價值等。
伴隨大資料的增長,壓縮成為必然。壓縮的優勢在於:
壓縮的資料使用較少的頻寬。
壓縮的資料使用較少的磁碟。
加速資料在磁碟和網路上的傳輸。
降低成本。
2. hadoop中的壓縮型別
大資料包含複雜的、非結構化的資料,因此資料壓縮很重要,codec表示資料壓縮和解壓縮演算法的實現。一些壓縮格式是可分割的,這樣的壓縮對大檔案在效能上是較好的。hadoop支援的一般壓縮演算法如下:
LZO
Gzip
Bzip2
LZ4
Snappy
2.1 LZO
壓縮格式由大量小塊壓縮資料組成,塊大小對壓縮和解壓資料是一樣的。它的壓縮和解壓縮速度是很快的而且是可分割的,LZO是一個用ANSI C編寫的很少丟失資料的壓縮庫。它的原始碼和壓縮資料格式使得它在平臺之間遷移是非常便攜的。LZO的特徵如下:
資料壓縮類似於其他普遍的壓縮技術,比如gzip、bzip
能夠非常快速的解壓縮
除去源和目的buffer外,解壓縮不需要額外的記憶體
對產生的預壓縮資料有多種壓縮level,因此帶來了有競爭力的壓縮比
還有一種壓縮level僅僅為8KB資料壓縮
演算法是執行緒安全的
演算法是資料無損的
LZO是便攜的
Lzop是使用LZO作為壓縮服務的檔案壓縮器,它是最快的壓縮和加壓縮器。
2.2 GZIP
GUN zip,基於DEFLATE演算法,LZ77和Huffman編碼的結合。它比LZO壓縮效能好但是慢。如果原生hadoop lib在CLASSPATH中不可用,那麼java將使用java自身的GZIP。
它在檔案中尋找相似的字串,臨時的替換這些字串以使得檔案變小,第二個字串用前一個字串的指標替換,形為(distance,length)。文字和匹配長度以Huffman樹壓縮,而匹配距離以另一棵樹壓縮,這些樹在每一塊的塊首以緊湊的格式儲存。
deflate是壓縮演算法而inflate是解壓縮演算法,Gzip檔案的字尾為.gz,各種可用的格式如下:
tar
shar
zip
tar.gz
tar.z
2.3 Bzip2
一種自由、可用的、高質量資料壓縮器。壓縮率一般在10%~15%,壓縮的資料塊大小在100~900KB。Bzip2的效能是不對稱的,解壓快。它支援儲存媒介錯誤有限恢復,如果你試圖從備份的磁帶或者磁碟中修復資料且資料存在錯誤,bzip2依然能夠解壓檔案的這些部分如果硬體沒有收到損害。它也是便攜的,以塊來壓縮大檔案,塊的大小影響壓縮率和壓縮、解壓縮需要的記憶體。
2.4 LZ4
無丟失資料的壓縮演算法,強調壓縮解壓縮速度,壓縮速度為每core 400MB/S~GB/s
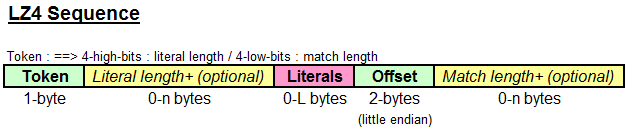
Token為1位元組的值,Field為Literal長度,其值為0 則沒有後面的Literal,其值為15則更多地Byte被新增,每一額外欄位代表0~255之間的一個數字以計算總長。Literals為未壓縮的文字,Offset代表匹配副本的位置,1 意味著當前位置-1 欄位,最大值為65535 。
2.5 Snappy
非常高速、合理的壓縮器。
3 總結
gzip是普通的壓縮器,bzip壓縮效能好於gzip但速度慢,LZO由很多小塊組成。
LZO和Snappy的壓縮速度好但壓縮效率低,解壓是gzip的兩倍。Snappy解壓縮好於LZO
| Compresssion format | Tool | Algorithm | File extention | Splitable |
| Gzip | gzip | DEFLATE | .gz | No |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | Yes if indexed |
| Snappy | N/A | Snappy | .snappy | No |
相關推薦
hadoop壓縮演算法的總結
1. 壓縮成為必須 對資料的3個關鍵特徵描述 3V:volume、variety和value。 volume,資料量與日俱增,在於智慧手機、Internet和感知器等的使用。 variety,大資料的資料格式,音訊、視訊、影象等。 value,資料近乎實時的產生以使得有用資
hadoop常用的壓縮演算法總結和實驗驗證
壓縮格式總表 壓縮格式 工具 演算法 副檔名 是否可切分 DEFLATE N/A DEFLATE .deflate No gzip gzip DEFLATE .gz No bzip2 bzip2 bz
Hadoop壓縮演算法snappy
Snappy的前身是Zippy。雖然只是一個數據壓縮庫,它卻被Google用於許多內部專案程,其中就包括BigTable,MapReduce和RPC。Google宣稱它在這個庫本身及其演算法做了資料處理速度上的優化,作為代價,並沒有考慮輸出大小以及和其他類似工具的相容性問
hadoop +streaming 排序總結
.lib fields 排序 1.4 stream 想要 output 廣泛 sep 參考http://blog.csdn.net/baidu_zhongce/article/details/49210787 hadoop用於對key的排序和分桶的設置選項比較多,在公司中
初步認識hadoop的一些總結
hadoop<iframe id="embed_dom" name="embed_dom" frameborder="0" style="display:block;width:525px; height:245px;" src="https://www.processon.com/embed/mind
linux壓縮打包總結
tar1 壓縮打包介紹linux 下壓縮文件有Linux .zip,.gz,.bz2,.xz,.tar.gz,.tar.bz2,.tar.xz2 gzip壓縮工具 gzip 不能壓縮目錄小測試:壓縮前期工作: [root@chy tmp]# mkdir d6z [root@chy tmp]# cd d6z/
Hadoop常見異常總結
ont hadoop style 否則 創作 轉載 作品 pan 版權 Hadoop常見異常總結 作者:尹正傑 版權聲明:原創作品,謝絕轉載!否則將追究法律責任。
Hadoop常用命令總結
結構 換行 表示 hdf 幫助 需要 創建 data deny 一、前述 分享一篇hadoop的常用命令的總結,將常用的Hadoop命令總結如下。 二、具體 1、啟動hadoop所有進程start-all.sh等價於start-dfs.sh + start-yarn.
Java 常用排序演算法總結
氣泡排序: /*冒泡演算法*/ public class BubbleSort { public static void bubble_sort(int[] arr){ int temp; for(int i = 0; i < arr
2018.10.31 遞迴演算法總結
///十進位制轉二進位制 void dectobin( int n ) { if(n==0) return; dectobin(n/2); printf("%d",n%2); } ///遞迴求斐波那契數列 int fib(int n) { if(n==1 ||
匈牙利演算法總結
二分圖: 定義:如果一個圖的所有頂點可以被分為X和Y兩個集合,並且所有邊的兩個頂點恰好一個屬於集合X,另一個屬於集合Y,即每個集合內的頂點沒有邊相連,那麼此圖就是二分圖。 很多問題都可以轉化為二分圖匹配模型來計算。二分圖有如下幾種常見變形: (1)最小頂點覆蓋 選取最少的點(X或
博弈論的演算法總結
開頭先囉嗦一句:想學好博弈,必然要花費很多的時間,深入學習,不要存在一知半解,應該是一看到題目,就想到博弈的型別。 以及,想不斷重複不斷重複,做大量各大oj網站的題目,最後吃透它。 博弈: 博弈論又被稱為對策論(Game Theory),既是現代數學的一個新分支,也是運籌學的一個重要學科。 博
12、【演算法】查詢演算法總結
一、順序查詢 1、定義 順序查詢屬於無序查詢,從資料結構的一端開始,順序掃描,依次將掃描到的節點關鍵字與給定值K相比,若相等,則表示查詢成功,若掃描結束,仍未找到關鍵字與給定值K相等,則表示查詢失敗。 時間複雜度分析 查詢成功時:平均查詢長度為(N+1)/2
11、【演算法】排序演算法總結
常見排序演算法總結 一、氣泡排序 1、定義 氣泡排序是一種比較簡單的排序演算法,它會遍歷若干次要排序的數列,每次便利時,它都會從前往後依次的比較兩個相鄰的數的大小;如果前者比後者大,則交換它們的位置。 這樣一次遍歷之後,最大的元素就在數列的末尾了。採用相同的方法在
【極客時間】資料結構與演算法總結
【極客時間】資料結構與演算法總結: 02| 資料結構是為演算法服務的,演算法要作用在特定的資料結構之上。 20個最常用的最基礎的資料結構與演算法: 10個數據結構:陣列、連結串列、棧、佇列、散列表、二叉樹、堆、跳錶、圖、Trie樹 10個演算法:遞迴、排序、二分
演算法總結-二叉樹的深度優先搜尋
1 遍歷的問題 二叉樹的前序遍歷 http://www.lintcode.com/zh-cn/problem/binary-tree-preorder-traversal/ 二叉樹的中序遍歷 http://www.lintcode.com/zh-cn/problem/b
演算法總結-兩根指標
####Two Sum Two Sum http://www.lintcode.com/zh-cn/problem/two-sum-input-array-is-sorted/ Two Sum - Unique pairs http://www.jiuzhang.com/soluti
演算法總結-陣列和連結串列
1 連結串列 Dummy Node的應用 K組翻轉連結串列 http://www.lintcode.com/zh-cn/problem/reverse-nodes-in-k-group/ 連結串列劃分 http://www.lintcode.com/zh-cn/probl
演算法總結之深度優先搜尋
1 組合搜尋問題 子集 http://www.lintcode.com/zh-cn/problem/subsets/ 帶重複元素的子集 http://www.lintcode.com/zh-cn/problem/subsets-ii/ 數字組合 http://www
目標識別、目標跟蹤演算法總結
想自學影象處理的相關知識,正好實驗室師兄做過兩個關於紅外目標跟蹤的專案,因此從mean-shift 、SR、RP、PF開始學習。但是查閱資料的時候,發現對各種演算法理解非常 利用影象處理演算法,實現的功能一般包括: 目標的檢測、識別、跟蹤。常見的問題包括:人臉