
RCNN系列(2):Fast R-CNN—用於精準目標檢測和語義分割的快速功能結構~
論文地址: Fast R-CNN
0. 摘要
該論文對上一篇R-CNN進行改進,在訓練速度,推斷速度和精度上都有了很大的提升。
1. 介紹
相比於分類,目標檢測的計算代價大幅提升,這是因為目標檢測除了分類還需要精準的定位,帶來了兩個方面的問題,涉及速度,精度和模型精簡度的問題:
- 一是需要處理大量的提議框
- 二是這些候選框的得到粗糙定位後需要進一步精細化
該論文中提出了一個一階段的訓練方法來聯合訓練提議方法和空間位置迴歸,在當時的方法中缺德了state-of-art效果。
1.1 R-CNN and SPPnet
R-CNN提出使用深度卷積伸進網路對候選區域進行分類,但有一些缺點:
- 多階段的訓練:首先使用對數損失函式微調作用於候選框卷積神經網路,接著訓練適用於卷積神經網路的SVM,然後進行邊界位置狂的迴歸。
- 訓練的時間和空間成本都很高:需要對每個圖片的每個候選框進行特徵提取且需要寫到磁碟上
- 目標檢測推斷階段速度慢:同理,每一張影象的每一個候選框都需要進行特徵提取
SPPnets能夠加速R-CNN,主要是通過共享一部分的計算,即它對於每一張影象只進行一次特徵提取然後從特徵圖中對每一個候選框提取一個特徵向量。
SPPnet也有一些缺點,它的訓練也是多階段的,提取特徵,微調網路,訓練SVM並且進行位置資訊的迴歸。這一過程特徵也需要寫到磁碟上,但是他的微調不會更新sppnet的卷積層,這會限制非常深的卷積神經網路的精確度。
1.2 論文貢獻
- 更高的目標檢測質量mAP
- 單階段的質量,使用多工損失
- 訓練能夠更新所有的網路層
- 獲取特徵的過程不需要寫入磁碟
2. Fast R-CNN架構和訓練
下圖是Fast R-CNN的模型架構,Fast R-CNN將整幅圖片和一系列目標候選區域作為輸入。首先網路處理影象產生一個特徵圖,然後對於每一個物體產生感興趣區域,接著將所有的特徵向量輸入到全連線層產生連個分支,分別是類別分數和位置座標。
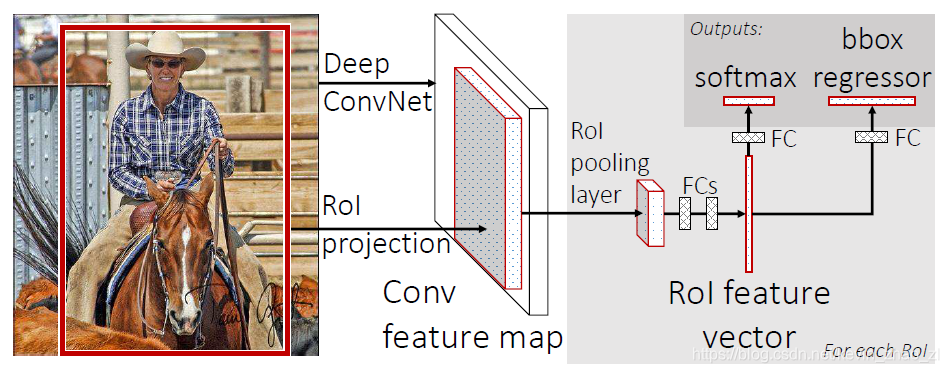
2.1 ROI(感興趣區域)池化層
ROI池化層使用最大池化將特徵圖中的感興趣區域轉化為小的固定大小(
)的特徵圖,其中H和W是網路層的超引數,與任何感興趣區域都無關。這篇論文中每一個ROI都是一個矩形視窗其具有,具有一個四元組的引數。
RoI最大池化
的RoI視窗劃分為
個網格區域,每個小格的尺寸大約是
,然後對每個子視窗的網格進行最大池化。池化操作獨立應用於每個特徵圖通道,池化層僅僅是空間金字塔池化層的一個特例,其只有一個金字塔層級,
2.2 從預訓練模型初始化
論文對三種具有五個最大池化層和5到13個卷積層的ImageNet預訓練的模型進行實驗,使用與訓練模型初始化Fast R-CNN後,這些網路會進行一下的修改:
- 最後一個最大池化層使用具有超引數H和W的RoI池化層來代替
- 網路最後的全連線層和softmax被能產生類別分數softmax和邊界框的迴歸器代替
- 修改網路使其能接受兩種資料輸出即一系列的原始i影象和一系列的感興趣區域
2.3 微調網路用於檢測
Fasr R-CNN一個重要的特性是在後向傳播的過程中會訓練更新所有的網路層權重,相反,SPPNet不會更新空間金字塔池化層之下的各層權重,根本原因是SPP層在訓練樣本來自不同影象時訓練代價極高,這是由於每一個RoI可能有很大的感受野,而前向傳導過程必須處理全部的感受野,訓練的輸入經常時整個圖片,過大。
論文提出的高效方法利用了特徵共享。訓練過程中,SGD的訓練批次是分層取樣的,首先是N張圖片,接著從每張圖片取R/N個RoIs。而且,來自同一張圖片的RoIs會共享計算和儲存。實際訓練的時候這種方法並沒有因為來自同一張圖象的RoI相關而造成收斂過慢。
除了分層取樣,Fast R-CNN還使用了流水線訓練方法,即只有一個微調階段來聯合訓練softmax分類器和邊界框迴歸器,而不是分別訓練softmax分類器,SVMs和迴歸器。具體的引數如下:
多工損失:Fast R-CNN網路的輸出包括兩個,一個是描述每個RoI在K+1類(+背景)上的可能的概率分佈,另一個是邊界框迴歸偏差,類別k的邊界框迴歸偏差可以定義為
。
對每一個待訓練的RoI的gt類別u和gt邊界框v,定義一個多工損失來聯合訓練分類器和迴歸器:
其中
,對於
,u=0即該類為背景,損失具體為:
其中:
是一個
損失,相比於
,對離群點不敏感。當迴歸目標無界,使用
損失需要進行謹慎地學習率的調整以避免梯度爆炸,
損失則消除了這種敏感性。
損失函式中的超引數
用來對分類損失和定位損失進行權衡,論文中實驗取1。
多批次取樣:微調期間,SGD每個最小批次都是隨機從兩張圖片(N=2)中構造的,取
,即從每張圖片中取64個RoIs。從中選區25%的IoU大於0.5的RoIs組成帶前景的樣本,u
。其餘的選擇最大IoU的RoIs作為負樣本,
。低於閾值0.1的樣本作為啟發式的難樣本挖掘,訓練時,圖片以0.5的概率及進行水平切分。
RoI池化層的後向傳導:RoI池化層後向傳導函式計算每一個輸入
的損失函式的偏導:
即對於每一個小批次中的RoI r和每個池化輸出單元的 ,偏導數 在i是由最大池化確定的對於