
Object Detection(2):Fast R-CNN
這篇承接上一篇,FRCN是rbgirshick在R-CNN基礎上提出的改進,提出了一些創新式的做法,不僅提升了訓練和測試時的速度,而且提升了精度。

可以看出,FRCN不僅在精度上得到了提升,更重要的是,它在測試時比RCNN快了213倍,這讓實時處理成為可能(當然faster RCNN基本已經達到了實時的要求)。接下來我們首先分析一下這篇論文:https://arxiv.org/abs/1504.08083
寫在解讀之前:
通篇閱讀下來,實在敬服rbgirshick大神。有理有據,對比實驗,實現,思路都十分清晰。尤其是第五部分,對那幾個問題的探討和對比實驗,更是讓人茅塞頓開。RBG大神的學術態度真是高山仰止!
一.論文解讀
1.Introduction
detection有兩方面的挑戰。第一,大量的候選區域需要被處理;第二,候選區域只能提供大致的定位,所以必須被細調來達到精確的定位。這兩個挑戰讓眾多解決方案只能犧牲速度和精度。
RCNN是一個多級的過程,首先提取約2k個候選區域,然後使用log loss微調一個卷積網路,最後,訓練SVMs作為檢測器。RCNN在測試時很慢(在GPU上大約47s/image),因為每一個候選區域都需要在卷積網路中做一遍前向傳播,沒有共享計算。
SPPnet改進了這一點,它將整張圖片作為輸入得到一張特徵圖,然後再用特徵圖中提取到的特徵向量分類每一個候選區域,但SPPnet同樣是一個多級過程。
rbgirshick認為FRCN有以下幾個貢獻:
1.更高的檢測質量(mAP)相比於RCNN和SPPnet
2.使用一個多工的loss,訓練時單級的
3.訓練可以更新所有網路層
4.不需要為特徵快取提供磁碟儲存
2.Architecture和training
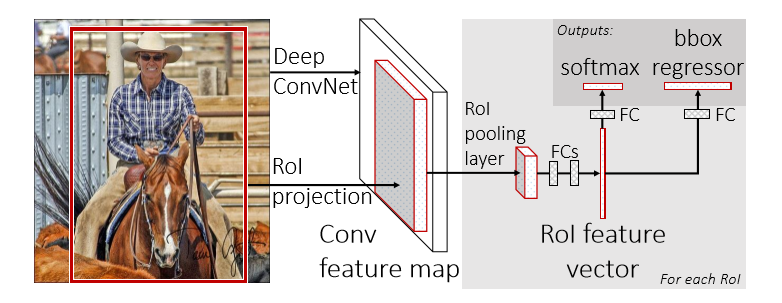
這張圖就是FRCN的架構圖。一個FRCN網路使用整張圖片和候選區域集做為輸入,網路首先處理整張圖片得到一個卷積特徵圖,然後,為每個候選區域的ROI(region of interest)池化層從特徵圖中提取一個固定長度的特徵向量,每個特徵向量被送入全連線層,最終分成兩個兄弟輸出層:一個產生softmax概率評估K個物體類別外加一個"背景"類,另一個為每一個物體類輸出4個實數值,每個4個值的集合都是K個類別的位置細調的結果。
2.1 ROI pooling layer
ROI池化層是SPP(spatial pyramid pooling)層的特殊情況,這裡等看完SPPnet那篇文章再來詳細解釋
2.2 Initializing from pre-trained networks
一個預訓練的網路初始化一個FRCN網路,需要三個轉換:
1.最後一層最大池化層被一個ROI層替代來和網路的第一個全連線層相容
2.最後一個全連線層和softmax層被前文所述的兄弟層替代
3.網路需要被修改成採用兩個輸入:一個影象列表和這些影象中的ROIs列表
2.3 Fine-tuning for detection
使用反向傳播方法來訓練所有網路層的引數是FRCN的一個重要能力。首先,文中闡釋了為什麼SPPnet不能更新SPP層以下的層的引數的原因。根本原因是因為RCNN和SPPnet訓練時的樣本來自不同的影象,導致SPP層的反向傳播非常低效。這種低效性來源於每個ROI基本都有一個非常大的感受野,經常就是整張圖片。
文中提出了一個有效的方法。在FRCN訓練過程中,SGD mini-batches是分層抽樣的,首先採樣N張圖片,然後採用對每一張圖片取樣R/N個ROIs。關鍵是在前向和反向計算時,來自同一張圖片的ROIs共享計算和記憶體,這大大減少了一個mini-batch的計算。例如,當N=2,R=128時,這種方法比從128個不同的影象中提取一個ROI的方法要快64倍。這種策略的一個缺點在於其可能會減慢訓練的收斂因為來自同一張圖片的ROIs是相關的。但是在實踐中這種擔憂並沒有出現,當N=2,R=128時,比RCNN使用更少的SGD迭代得到了更好的結果。
Multi-task loss FRCN網路有兩個子輸出。第一個輸出一個離散的概率分佈(每一個ROI),p=,對應於K+1個類別。第二個輸出邊界框的迴歸偏移,
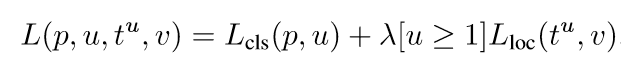
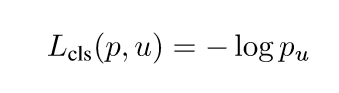
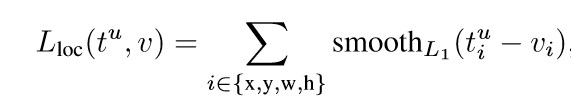
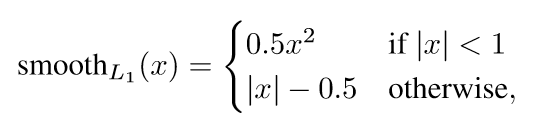
這是文中用於多分類任務的損失函式,u是具體的物體類別,而v則代表邊界框的迴歸目標。
Mini-batch sampling 每個mini-batch來自於N=2張圖片,mini-batch size取R=128,也就是從每張圖片中取64個ROIs。25%的ROIs來自候選區域中和標註邊界框有至少0.5(IoU)重疊,這些ROIs包含標記有前景物件類的示例,也就是u>=1的那些具體物體,剩下75%的ROIs取自最大IoU在[0.1,0.5)之間的候選區域,代表u=0的背景樣例。訓練時,圖片以0.5的概率採用水平翻轉,不採用其他的資料增強技術。
Back-propagation through RoI pooling layers 這一部分是推導ROI層的前向和反向傳播函式
SGD hyper-parameters 分類和迴歸的全連線層分別被初始化為0均值的高斯分佈,標準差分別是0.01和0.001.偏置項被初始化為0.所有層的learning rate初始化為0.001,30k次迭代後,lr降至0.0001,再訓練10k次。但訓練大資料集時,迭代更多次。momentum初始化為0.9,weight_decay初始化為0.0005
2.4 Scale invariance
文中探索了兩種實現尺度不變性的物體檢測的方法:一種通過蠻力學習,另一種是用影象金字塔。
3.Fast R-CNN detection
一旦FRCN網路微調完成,檢測任務只需要前向傳播這一個簡單的步驟就可以完成(假設候選區域已經被提前計算好了)。網路用一張圖片(或一個影象金字塔)和用於評分的R個候選區域列表作為輸入。
3.1 Truncated SVD for faster detection
對於整張圖片分類,花在全連線層的時間要遠小於卷積層。而對於檢測任務,當ROIs的數量較大時,大約一半的時間都用於計算全連線層。這時,我們可以對全連線層採用SVD(奇異值分解)的方法,減少其引數,從而加速運算速度。
4.Main Results
接下來就是實驗結果了,主要有三個貢獻:
1.在VOC07,2010和2012上均得到了state-of-the-art mAP結果
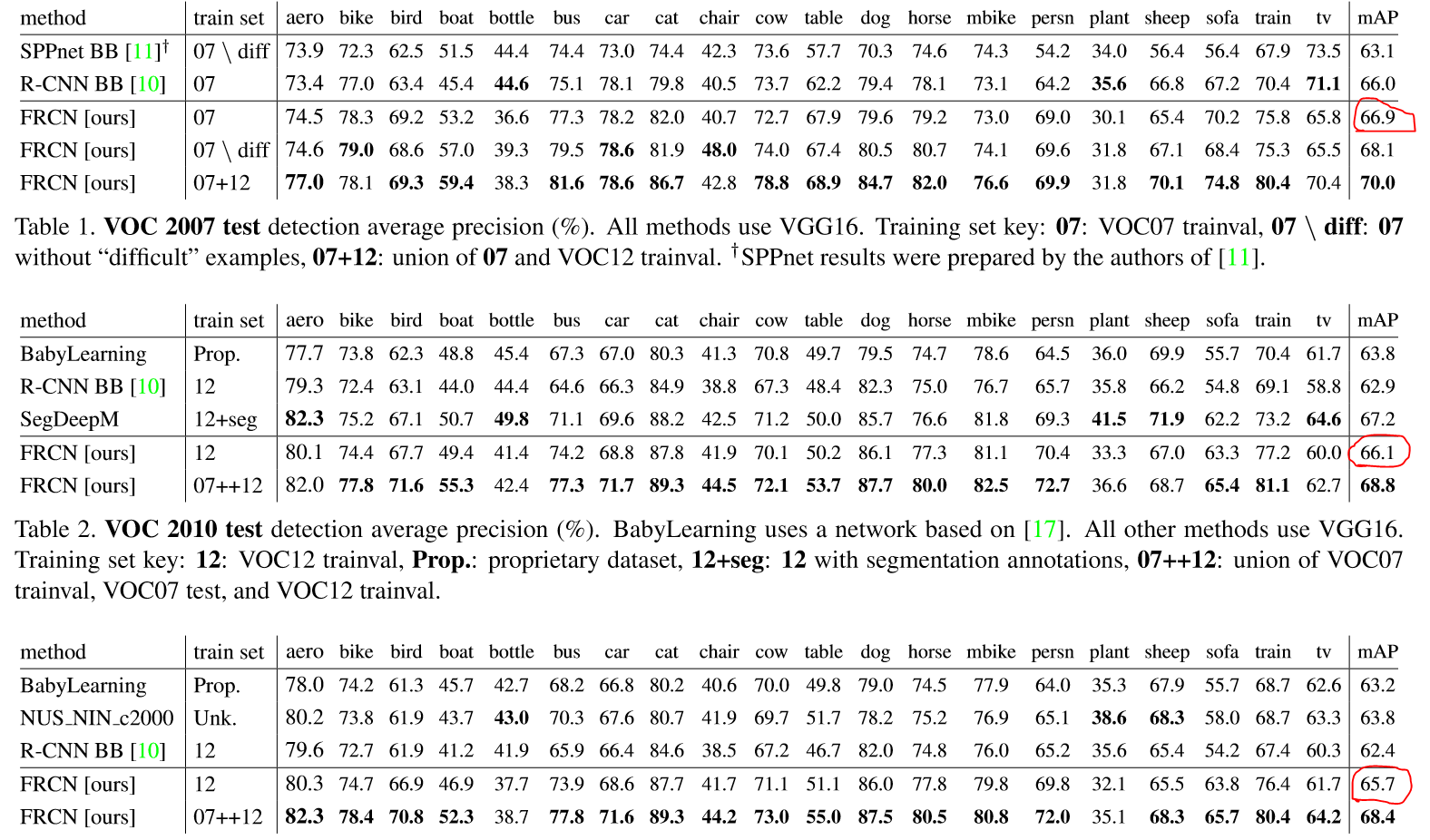
2.相比於RCNN和SPPnet更快的訓練和測試過程
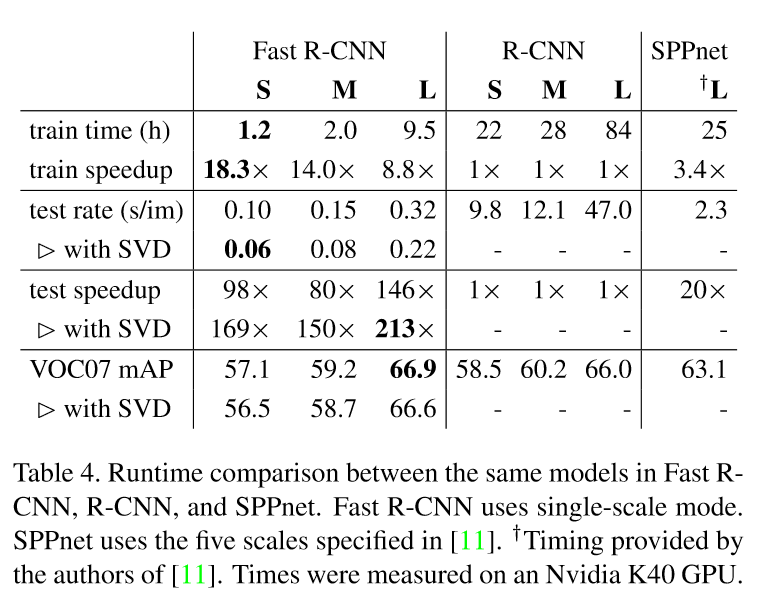
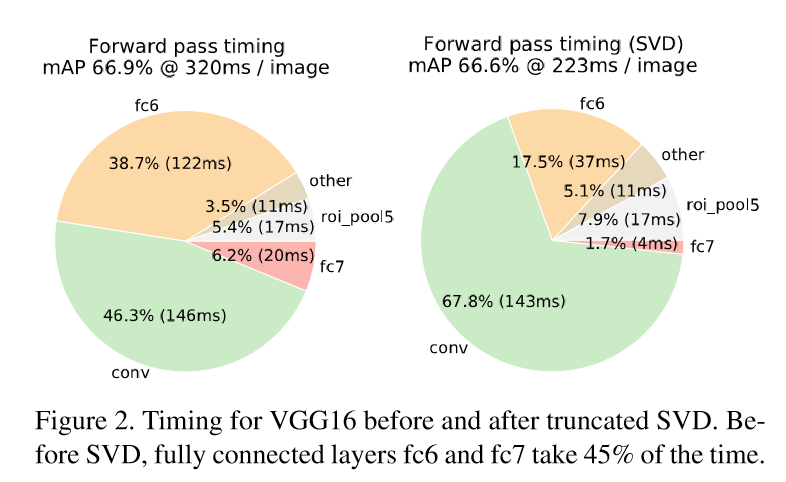
3.在VGG16上微調卷積層提高了mAP

但作者認為對於很深的網路(如VGG16),不是所有的卷積層都需要微調。因為conv1通常是一般性的,和任務無關的特徵(通過視覺化可以知道是顏色及邊緣資訊),所以微調conv1與否對最後的mAP影響不大,但會浪費許多時間。作者發現,微調conv3_1之後的層能得到最大的收益。
5.Design evalution
5.1 多工訓練是否有幫助?
通過對比實驗證明確實對提高performance有幫助
5.2 尺度不變性:蠻力還是靈巧?
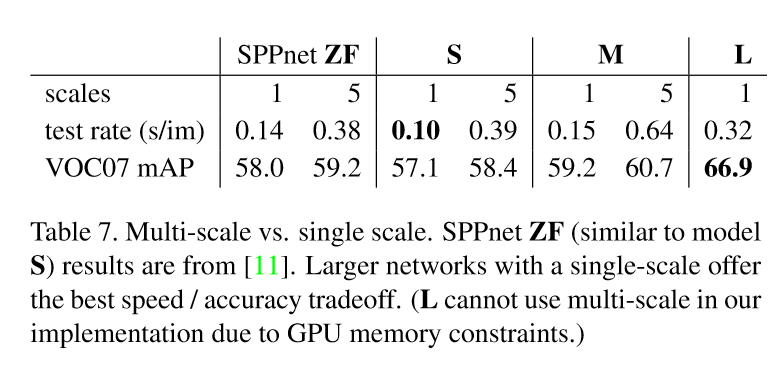
對比實驗表明,蠻力方法(single scale)更好,multi-scale只能帶來少量的mAP提升,卻造成了大量計算時間的增加。這也同時驗證了SPPnet中的結果:深度卷積網路善於直接學習尺度不變性
5.3 是否需要更多訓練資料?
顯然是的。通過將合併VOC07和VOC12,得到了明顯的mAP提升(66.9%提升到70.0%),同樣的結果在VOC10和VOC12上也觀察到了
5.4 SVMs是否比softmax更優秀?
事實說明並非如此
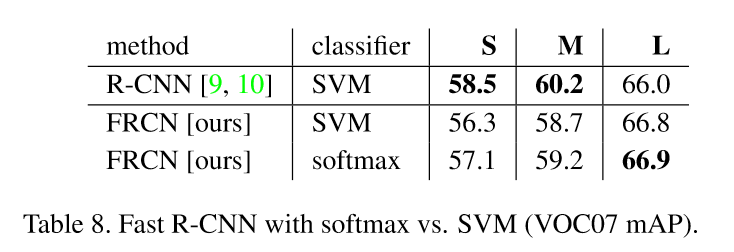
5.5 更多候選區域是否總是更好?
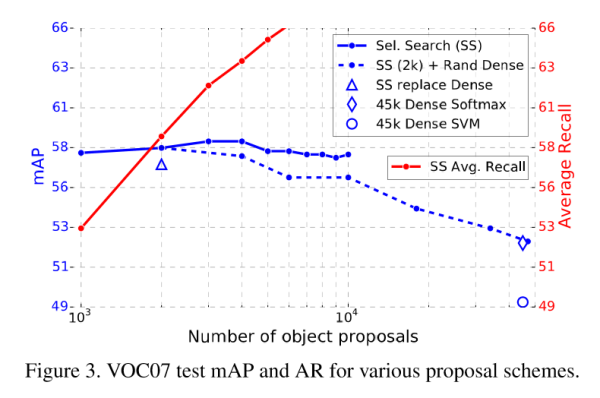
實驗結果說明並非如此。這一點不通過實驗恐怕很難解釋,但似乎稀疏的候選區域結果會更好
二.實踐
論文終於解讀完了~^_^
下面我們利用開原始碼實踐一下!
主要是python程式碼和c++版本的caffe。對程式碼結構瞭解之後,我們可以復現論文中的結果,稍微修改之後,我們也可以在自己的資料集上訓練模型。
在windows下配置過程:
1.首先編譯caffe.這裡我們需要新增roi_pooling_layer和smooth_L1_loss_layer,我們使用happynear的caffe版本中的這兩個層引數,首先
git clone https://github.com/happynear/caffe-windows.git
下載這個專案,我們遵循官方新增新層的過程:
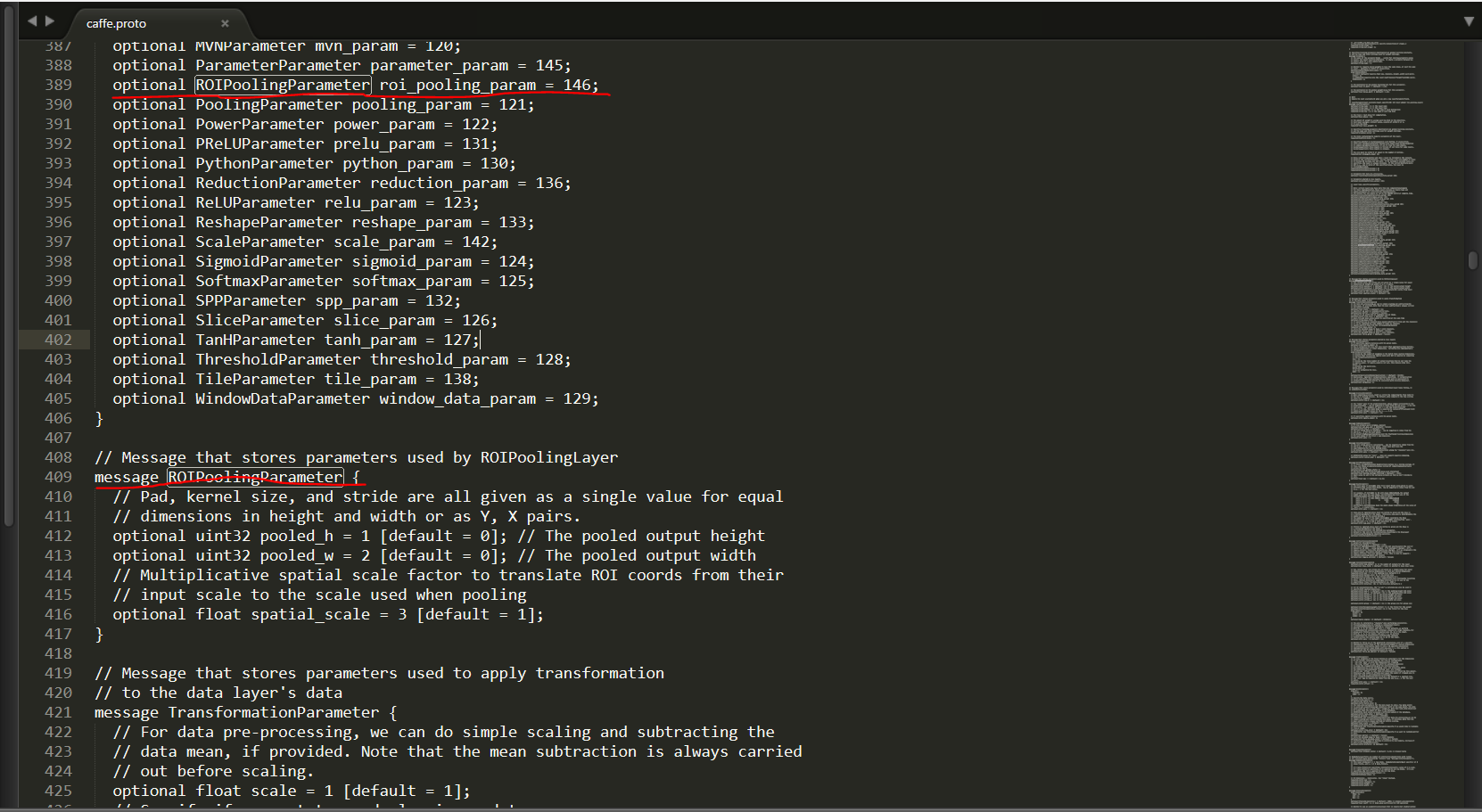
1)首先修改src/caffe/proto/caffe.proto檔案,新增roi_pooling_layer引數層
2)將happynear版本下的roi_pooling_layer.cpp(cu)和smooth_L1_loss_layer.cpp(cu)四個檔案拷貝到我們的caffe-windows中src/caffe/layers/下,並將include/caffe/下的custom_layers.hpp對應copy過來
3)在VS2013的libcaffe對應資料夾下新增這幾個檔案,然後編譯即可,請預先編譯pycaffe,因為馬上就會用到
2.然後使用
git clone --recursive https://github.com/rbgirshick/fast-rcnn.git
將fast-rcnn專案克隆到本地
3.為測試demo和我們自己的資料,我們需要下載已經預訓練好的fast-rcnn模型,可以直接使用<frcn-root>/data/scripts/fetch_fast_rcnn_models.sh,但需要在windows下配置wget,而且下載速度比較慢,所有我直接從happynear分享出的雲盤上下載的:frcn-models,下載完成後,將fast_rcnn_models資料夾拷貝到<frcn-root>/data資料夾下即可
4.我使用的是Anaconda2,cython已經預設裝好了,只需要安裝easydict即可
pip install easydict
5.將前面第一步編譯好的caffe python介面下的內容複製到<frcn-root>/caffe-fast-rcnn/python資料夾下,覆蓋原有的內容
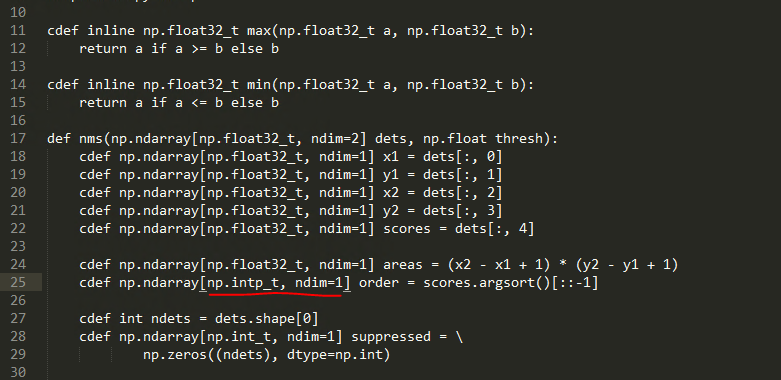
6.用文字編輯器開啟<frcn-root>/lib/utils/nms.pyx,將第25行的np.int_t修改為np.intp_t
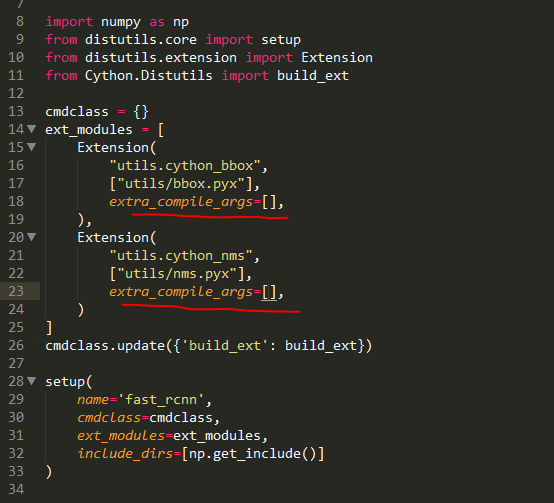
7.用文字編輯器開啟<frcn-root>/lib/setup.py,將第18行和23行的
"-Wno-cpp", "-Wno-unused-function"指令刪除,只留下空的中括號[]即可
8.開啟cmd,首先定位至<frcn-root>/lib目錄下,然後輸入
python setup.py install如果提示Unable to find vcvarsall.bat的話,請輸入以下指令:
SET VS90COMNTOOLS=%VS120COMNTOOLS%
setup.py安裝完成後,到python_root/Lib/site-packages/utils中可以找到兩個檔案cython_bbox.pyd和cython_nms.pyd,把這兩個檔案複製到<frcn-root>/lib/utils中

9.好了,接下來我們測試demo吧,在<frcn-root>下:
python tools/demo.py
首先看一下demo的結果圖:




執行結果可以看出,第一張圖片用時0.966s,第二張圖片用時0.408s,如果使用SVD壓縮的話,處理每張圖片大約只需要0.3s,基本上已經達到了實時的要求!
注:demo的配置部分已經補齊,後面會新增ROI層的解釋!
三.後續
faster-rcnn通過新增RPN(Region Proposal Network)來替代傳統的提取候選區域方法,並通過Anchor來解決尺度不變性問題!使得基於proposal的目標檢測方法幾乎已經發展到最好!