
大資料Spark+Kafka實時資料分析案例
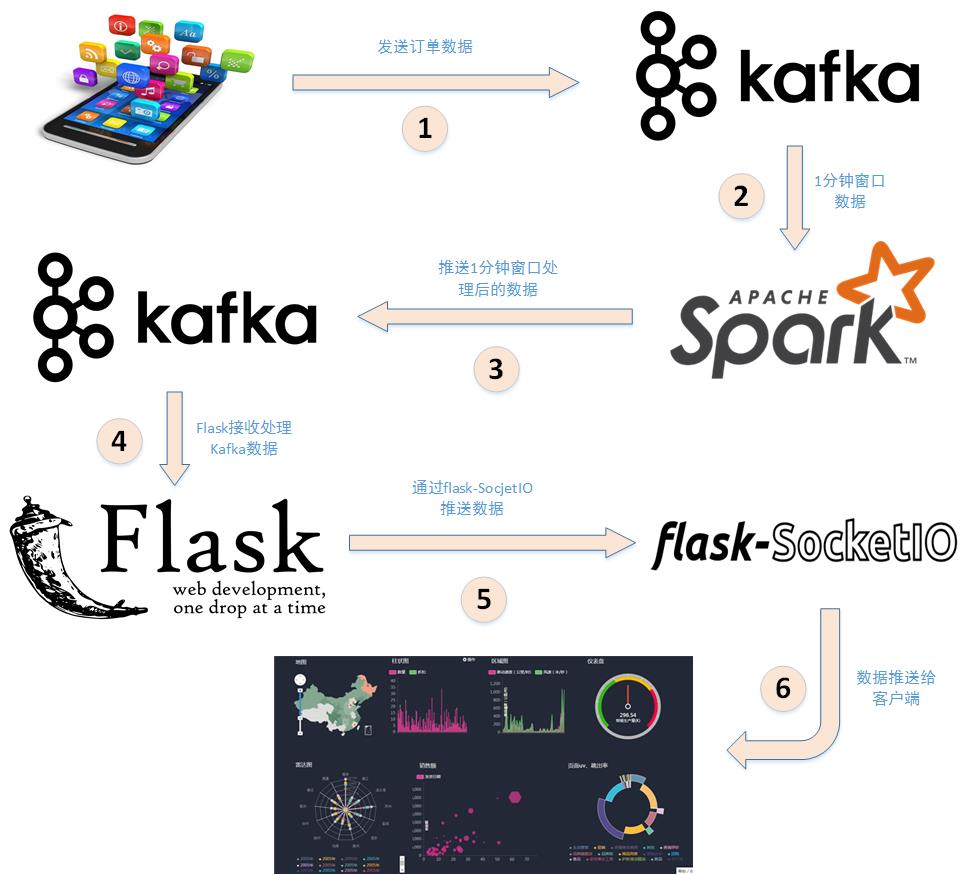
下面分析詳細分析下上述步驟:
- 應用程式將購物日誌傳送給Kafka,topic為”sex”,因為這裡只是統計購物男女生人數,所以只需要傳送購物日誌中性別屬性即可。這裡採用模擬的方式傳送購物日誌,即讀取購物日誌資料,每間隔相同的時間傳送給Kafka。
- 接著利用Spark Streaming從Kafka主題”sex”讀取並處理訊息。這裡按滑動視窗的大小按順序讀取資料,例如可以按每5秒作為視窗大小讀取一次資料,然後再處理資料。
- Spark將處理後的資料傳送給Kafka,topic為”result”。
- 然後利用Flask搭建一個web應用程式,接收Kafka主題為”result”的訊息。
- 利用Flask-SocketIO將資料實時推送給客戶端。
- 客戶端瀏覽器利用js框架socketio實時接收資料,然後利用js視覺化庫hightlights.js庫動態展示。
至此,本案例的整體架構已介紹完畢。
一、實驗環境準備
實驗系統和軟體要求
Ubuntu: 16.04
Spark: 2.1.0
Scala: 2.11.8
kafka: 0.8.2.2
Python: 3.x(3.0以上版本)
Flask: 0.12.1
Flask-SocketIO: 2.8.6
kafka-python: 1.3.3
系統和軟體的安裝
Kafka安裝
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。Kafka的目的是通過Hadoop的並行載入機制來統一線上和離線的訊息處理,也是為了通過叢集機來提供實時的消費。下面介紹有關Kafka的簡單安裝和使用, 簡單介紹參考
我選擇的是kafka_2.11-0.10.1.0.tgz(注意,此處版本號,在後面spark使用時是有要求的,見整合指南)版本。
sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka
sudo chown -R hadoop ./kafka接下來在Ubuntu系統環境下測試簡單的例項。Mac系統請自己按照安裝的位置,切換到相應的指令。按順序執行如下命令:
cd /usr/local/kafka # 進入kafka所在的目錄
bin/zookeeper-server-start.sh config/zookeeper.properties 命令執行後不會返回Shell命令輸入狀態,zookeeper就會按照預設的配置檔案啟動服務,請千萬不要關閉當前終端.啟動新的終端,輸入如下命令:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.propertieskafka服務端就啟動了,請千萬不要關閉當前終端。啟動另外一個終端,輸入如下命令:
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblabtopic是釋出訊息釋出的category,以單節點的配置建立了一個叫dblab的topic.可以用list列出所有建立的topics,來檢視剛才建立的主題是否存在。
bin/kafka-topics.sh --list --zookeeper localhost:2181 可以在結果中檢視到dblab這個topic存在。接下來用producer生產點資料:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab並嘗試輸入如下資訊:
hello hadoop
hello xmu
hadoop world然後再次開啟新的終端或者直接按CTRL+C退出。然後使用consumer來接收資料,輸入如下命令:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning 便可以看到剛才產生的三條資訊。說明kafka安裝成功。
Python安裝
Ubuntu16.04系統自帶Python2.7和Python3.5,本案例直接使用Ubuntu16.04自帶Python3.5;
Python依賴庫
案例主要使用了兩個Python庫,Flask和Flask-SocketIO,這兩個庫的安裝非常簡單,請啟動進入Ubuntu系統,開啟一個命令列終端。
Python之所以強大,其中一個原因是其豐富的第三方庫。pip則是python第三方庫的包管理工具。Python3對應的包管理工具是pip3。因此,需要首先在Ubuntu系統中安裝pip3,命令如下:
sudo apt-get install python3-pip安裝完pip3以後,可以使用如下Shell命令完成Flask和Flask-SocketIO這兩個Python第三方庫的安裝以及與Kafka相關的Python庫的安裝:
pip3 install flask
pip3 install flask-socketio
pip3 install kafka-python這些安裝好的庫在我們的程式檔案的開頭可以直接用來引用。比如下面的例子。
from flask import Flask
from flask_socketio import SocketIO
from kafka import KafkaConsumerfrom import 跟直接import的區別舉個例子來說明。
import socket的話,要用socket.AF_INET,因為AF_INET這個值在socket的名稱空間下。
from socket import* 是把socket下的所有名字引入當前名稱空間。
二、資料處理和Python操作Kafka
本案例採用的資料集壓縮包為data_format.zip點選這裡下載data_format.zip資料集,該資料集壓縮包是淘寶2015年雙11前6個月(包含雙11)的交易資料(交易資料有偏移,但是不影響實驗的結果),裡面包含3個檔案,分別是使用者行為日誌檔案user_log.csv 、回頭客訓練集train.csv 、回頭客測試集test.csv. 在這個案例中只是用user_log.csv這個檔案,下面列出檔案user_log.csv的資料格式定義:
使用者行為日誌user_log.csv,日誌中的欄位定義如下:
- user_id | 買家id
- item_id | 商品id
- cat_id | 商品類別id
- merchant_id | 賣家id
- brand_id | 品牌id
- month | 交易時間:月
- day | 交易事件:日
- action | 行為,取值範圍{0,1,2,3},0表示點選,1表示加入購物車,2表示購買,3表示關注商品
- age_range | 買家年齡分段:1表示年齡<18,2表示年齡在[18,24],3表示年齡在[25,29],4表示年齡在[30,34],5表示年齡在[35,39],6表示年齡在[40,49],7和8表示年齡>=50,0和NULL則表示未知
- gender | 性別:0表示女性,1表示男性,2和NULL表示未知
- province| 收穫地址省份
資料具體格式如下:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,內蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,內蒙古
328862,1086186,1271,1253,1049,08,29,0,0,2,浙江
這個案例實時統計每秒中男女生購物人數,因此針對每條購物日誌,我們只需要獲取gender即可,然後傳送給Kafka,接下來Spark Streaming再接收gender進行處理。
資料預處理
接著可以寫如下Python程式碼,檔名為producer.py:(具體的工程檔案結構參照步驟一)
mkdir -p ~/kafka-exp/scripts
cd ~/kafka-exp/scripts
vim producer.py新增如入內容:
# coding: utf-8
import csv
import time
from kafka import KafkaProducer
# 例項化一個KafkaProducer示例,用於向Kafka投遞訊息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# 開啟資料檔案
csvfile = open("../data/user_log.csv","r")
# 生成一個可用於讀取csv檔案的reader
reader = csv.reader(csvfile)
for line in reader:
gender = line[9] # 性別在每行日誌程式碼的第9個元素
if gender == 'gender':
continue # 去除第一行表頭
time.sleep(0.1) # 每隔0.1秒傳送一行資料
# 傳送資料,topic為'sex'
producer.send('sex',line[9].encode('utf8'))上述程式碼很簡單,首先是先例項化一個Kafka生產者。然後讀取使用者日誌檔案,每次讀取一行,接著每隔0.1秒傳送給Kafka,這樣1秒傳送10條購物日誌。這裡傳送給Kafka的topic為’sex’。
Python操作Kafka
我們可以寫一個KafkaConsumer測試資料是否投遞成功,程式碼如下,檔名為consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer('sex')
for msg in consumer:
print((msg.value).decode('utf8'))在開啟上述KafkaProducer和KafkaConsumer之前,需要先開啟Kafka。然後再開兩個終端,分別用作釋出訊息與消費訊息,執行命令如下:
cd ~/kafka-exp/scripts
python3 producer.py #啟動生產者傳送訊息給Kafaka開啟另外一個命令列 終端視窗,消費訊息,執行如下命令:
cd ~/kafka-exp/scripts
python3 consumer.py #啟動消費者從Kafaka接收訊息執行上面這條命令以後,這時,你會看到螢幕上會輸出一行又一行的數字,類似下面的樣子:
2
1
1
1
.......三、Spark Streaming實時處理資料
本案例在於實時統計每秒中男女生購物人數,而Spark Streaming接收的資料為1,1,0,2…,其中0代表女性,1代表男性,所以對於2或者null值,則不考慮。其實通過分析,可以發現這個就是典型的wordcount問題,而且是基於Spark流計算。女生的數量,即為0的個數,男生的數量,即為1的個數。
因此利用Spark Streaming介面reduceByKeyAndWindow,設定視窗大小為1,滑動步長為1,這樣統計出的0和1的個數即為每秒男生女生的人數。
Spark準備工作
Kafka和Flume等高階輸入源,需要依賴獨立的庫(jar檔案)。按照我們前面安裝好的Spark版本,這些jar包都不在裡面,為了證明這一點,我們現在可以測試一下。請開啟一個新的終端,然後啟動spark-shell:
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7
./bin/spark-shell啟動成功後,在spark-shell中執行下面import語句:
scala> import org.apache.spark.streaming.kafka010._
<console>:25: error: object kafka is not a member of package org.apache.spark.streaming
import org.apache.spark.streaming.kafka010._
^你可以看到,馬上會報錯,因為找不到相關的jar包。然後我們退出spark-shell。
根據Spark官網的說明,對於Spark2.3.0版本,如果要使用Kafka,則需要下載spark-streaming-kafka-0-10_2.11相關jar包。
現在請在Linux系統中,開啟一個火狐瀏覽器,請點選這裡訪問Spark官網,裡面有提供spark-streaming-kafka-0-10_2.11-2.3.0.jar檔案的下載,其中,2.11表示scala的版本,2.3.0表示Spark版本號。下載後的檔案會被預設儲存在當前Linux登入使用者的下載目錄下,本教程統一使用hadoop使用者名稱登入Linux系統,所以,我們就把這個檔案複製到Spark目錄的jars目錄下。請新開啟一個終端,輸入下面命令:
mkdir /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka
cp ./spark-streaming-kafka-0-10_2.11-2.3.0.jar /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka下面還要繼續把Kafka安裝目錄的libs目錄下的所有jar檔案複製到“/usr/local/spark/jars/kafka”目錄下,請在終端中執行下面命令:
cd /usr/local/kafka/libs
ls
cp ./* /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka建立Spark專案
之前有很多教程都有說明如何建立Spark專案,這裡再次說明。首先在/usr/local/spark/mycode新建專案主目錄kafka,然後在kafka目錄下新建scala檔案存放目錄以及scala工程檔案
mkdir -p /usr/local/spark/mycode/kafka/src/main/scala接著在src/main/scala檔案下建立兩個檔案,一個是用於設定日誌,一個是專案工程主檔案,設定日誌檔案為StreamingExamples.scala
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}這個檔案不做過多解釋,因為這只是一個輔助檔案,下面著重介紹工程主檔案,檔名為KafkaTest.scala
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
import org.apache.spark.streaming.kafka010._
object KafkaWordCount {
implicit val formats = DefaultFormats//資料格式化時需要
def main(args: Array[String]): Unit={
if (args.length < 3) {
System.err.println("Usage: KafkaWordCount <brokers> <groupId> <topics>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint("checkpoint")
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))//將輸入的每行用空格分割成一個個word
// 對每一秒的輸入資料進行reduce,然後將reduce後的資料傳送給Kafka
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).foreachRDD(rdd => {
if(rdd.count !=0 ){
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
// 例項化一個Kafka生產者
val producer = new KafkaProducer[String, String](props)
// rdd.colect即將rdd中資料轉化為陣列,然後write函式將rdd內容轉化為json格式
val str = write(rdd.collect)
// 封裝成Kafka訊息,topic為"result"
val message = new ProducerRecord[String, String]("result", null, str)
// 給Kafka傳送訊息
producer.send(message)
}
})
ssc.start()
ssc.awaitTermination()
}
}上述程式碼註釋已經也很清楚了,下面在簡要說明下:
- 首先按每秒的頻率讀取Kafka訊息;
- 然後對每秒的資料執行wordcount演算法,統計出0的個數,1的個數,2的個數;
- 最後將上述結果封裝成json傳送給Kafka。
另外,需要注意,上面程式碼中有一行如下程式碼:
ssc.checkpoint(".") 這行程式碼表示把檢查點檔案寫入分散式檔案系統HDFS,所以一定要事先啟動Hadoop。如果沒有啟動Hadoop,則後面執行時會出現“拒絕連線”的錯誤提示。如果你還沒有啟動Hadoop,則可以現在在Ubuntu終端中,使用如下Shell命令啟動Hadoop:
cd /usr/local/hadoop #這是hadoop的安裝目錄
./sbin/start-dfs.sh另外,如果不想把檢查點寫入HDFS,而是直接把檢查點寫入本地磁碟檔案(這樣就不用啟動Hadoop),則可以對ssc.checkpoint()方法中的檔案路徑進行指定,比如下面這個例子:
ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint")checkpoint的意思就是建立檢查點,類似於快照,例如在spark計算裡面 計算流程DAG特別長,伺服器需要將整個DAG計算完成得出結果,但是如果在這很長的計算流程中突然中間算出的資料丟失了,spark又會根據RDD的依賴關係從頭到尾計算一遍,這樣子就很費效能,當然我們可以將中間的計算結果通過cache或者persist放到記憶體或者磁碟中,但是這樣也不能保證資料完全不會丟失,儲存的這個記憶體出問題了或者磁碟壞了,也會導致spark從頭再根據RDD計算一遍,所以就有了checkpoint,其中checkpoint的作用就是將DAG中比較重要的中間資料做一個檢查點將結果儲存到一個高可用的地方(通常這個地方就是HDFS裡面)
執行專案
編寫好程式之後,下面介紹下如何打包執行程式。在/usr/local/spark/mycode/kafka目錄下新建檔案simple.sbt,輸入如下內容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.3.0"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.2.11"然後,即可編譯打包程式,輸入如下命令
/usr/local/sbt/sbt package打包成功之後,接下來編寫執行指令碼,在/usr/local/spark/mycode/kafka目錄下新建startup.sh檔案,輸入如下內容:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --driver-class-path /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/*:/usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.11/simple-project_2.11-1.0.jar 127.0.0.1:9092 1 sex 其中最後四個為輸入引數,含義如下
- 127.0.0.1:9092為brokerer地址
- 1 為consumer group標籤
- sex為消費者接收的topic
最後在/usr/local/spark/mycode/kafka目錄下,執行如下命令即可執行剛編寫好的Spark Streaming程式
sh startup.sh程式執行成功之後,下面通過之前的KafkaProducer和KafkaConsumer來檢測程式。
測試程式
下面開啟之前編寫的KafkaProducer投遞訊息,然後將KafkaConsumer中接收的topic改為result,驗證是否能接收topic為result的訊息,更改之後的KafkaConsumer為
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))在同時開啟Spark Streaming專案,KafkaProducer以及KafkaConsumer之後,可以在KafkaConsumer執行視窗,出現以下類似資料:
[{"0":1},{"2":3},{"1":6}]
[{"0":5},{"2":2},{"1":3}]
[{"0":3},{"2":3},{"1":4}]
.......
四、結果展示
接下來做的事是,利用Flask-SocketIO實時推送資料,socket.io.js實時獲取資料,highlights.js展示資料。
Flask-SocketIO實時推送資料
將介紹如何利用Flask-SocketIO將結果實時推送到瀏覽器。
下載程式碼,用python3.5 執行 app.py即可:
python app.py相關推薦
大資料Spark+Kafka實時資料分析案例
下面分析詳細分析下上述步驟: 應用程式將購物日誌傳送給Kafka,topic為”sex”,因為這裡只是統計購物男女生人數,所以只需要傳送購物日誌中性別屬性即可。這裡採用模擬的方式傳送購物日誌,即讀取購物日誌資料,每間隔相同的時間傳送給Kafka。 接著利用Spark Streaming從Kafka主題”s
騰訊雲EMR大資料實時OLAP分析案例解析
OLAP(On-Line Analytical Processing),是資料倉庫系統的主要應用形式,幫助分析人員多角度分析資料,挖掘資料價值。本文基於QQ音樂海量大資料實時分析場景,通過QQ音樂與騰訊雲EMR產品深度合作的案例解讀,還原一個不一樣的大資料雲端解決方案。 一、背景介紹 QQ音樂是騰
【備忘】大資料spark SQL專案實戰分析視訊
一. 大資料初識 二. Spark以及生態圈概況 三. 專案開發環境搭建 四. Spark SQL概要 五. 從Hive平滑過渡到Spark 六. DateFrame與Dataset 七. External Data Source 八. SparkSQL願景 九. 大型網站日誌實戰 十.
大資料 hive 15--hive日誌分析案例
1.1 專案來源 本次實踐的目的就在於通過對該技術論壇網站的tomcat access log日誌進行分析,計算該論壇的一些關鍵指標,供運營者進行決策時參考。 PS:開發該系統的目的是為了獲取一些業務相關的指標,這些指標在第三方工具中無法獲得的; 1.2 資料情況 該論壇資料有兩部分
Debezium SQL Server Source Connector+Kafka+Spark+MySQL 實時資料處理
寫在前面 前段時間在實時獲取SQLServer資料庫變化時候,整個過程可謂是坎坷。然後就想在這裡記錄一下。 本文的技術棧: Debezium SQL Server Source Connector+Kafka+Spark+MySQL ps:後面應該會將資料放到Kudu上。 然後主要記錄一下,整個元件使用和元
Spark+Kafka實時監控Oracle資料預警
**目標:** 監控Oracle某張記錄表,有新增資料則獲取表資料,並推送到微信企業。 **流程:** Kafka實時監控Oracle指定表,獲取該表操作資訊(日誌),使用Spark Structured Streaming消費Kafka,獲取資料後清洗後存入指定目錄,Python實時監控該目錄,提取文本里
大資料開發:實時資料平臺和流計算
大資料開發 1、實時資料平臺整體架構 實時資料平臺的支撐技術主要包含四個方面:實時資料採集(如Flume),訊息中介軟體(如Kafka), 流計算框架(如Storm, Spark, Flink和Beam),以及資料實時儲存(如列
大資料之Storm/實時資料處理視訊教程-李強強-專題視訊課程
大資料之Storm/實時資料處理視訊教程—28人已學習 課程介紹 大資料Storm實時資料處理視訊培訓課程:Strom是一個老牌的實時資料處理框架,在Spark Streaming流行前,Storm統治者整個流式計算的江湖。更詳細的說,Storm是一個實時資料處
分類資料之列聯表分析案例with sas
*表一,隨機設計四格表; options validvarname=any; data test1; input 用藥 $ 敏感性 $ 計數; datalines; 服藥 不敏感 180 服藥 敏感 215 未服藥 不敏感 73 未服藥 敏感 106 ; p
大資料——如何設計實時資料平臺(設計篇)
導讀:本文將會分上下兩篇對一個重要且常見的大資料基礎設施平臺展開討論,即“實時資料平臺”。 在上篇設計篇中,我們首先從兩個維度介紹實時資料平臺:從現代數倉架構角度看待實時資料平臺,從典型資料處理角度看待實時資料處理;接著我們會探討實時資料平臺整體設計架構、對具體問題的考量以及解決思路。
歷年滬深A股、香港H股票資料匯入和實時資料更新展示
<?php defined('IN_HEAVEN') or die('Hacking Attempt!'); /** * 股票資料匯入 * * PHP version 5 * * @category 4SWeb * @package Admin * @subpackage C
websocket+springboot+vue+element ui完成資料表格的實時資料
java部分: import org.springframework.stereotype.Component; impo
Spark SQL一步步分析Wifi探針商業大資料案例
該專案主要實現的主要功能: 一是通過探針裝置採集可監測範圍內的手機MAC地址、與探針距離、時間、地理位置等資訊: 二是探針採集的資料可以定時傳送到服務端儲存: 三是利用大資料技術對資料進行人流量等指標的分析。最終以合理的方式展示資料處理結果。 資料收集 資料收集由伺服器和探針裝置
大資料學習筆記(spark日誌分析案例)
前提:500w條記錄環境下(可以更多,視計算機效能而定),統計每天最熱門的top3板塊。 1、PV和UV 我們要統計的是最熱門的top3板塊,而熱門如果只是簡單地通過頁面瀏覽量(PV)或者使用者瀏覽量(UV)來決定都顯得比較片面,這裡我們綜合這兩者(0.3PV+
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰 一、實時流處理 1.1 實時計算 跟實時系統類似(能在嚴格的時間限制內響應請求的系統),例如在股票交易中,市場資料瞬息萬變,決策通常需要秒級甚至毫秒級。通俗來
Kafka+zookeeper+flume+spark實時資料分析
一、模擬產生日誌 在IDEA的resource資料夾下面新建log4j.properties定義日誌格式,其中flume和log4j的整合配置可以檢視Log4j Appender #設定日誌格式 log4j.rootCategory=ERROR,console,flume log4j.app
首頁 Hadoop Spark Hive Kafka Flume 大資料平臺 Kylin 專題文章 Spark運算元 一起學Hive Hive儲存過程 Hive分析函式 Spark On Yarn 資料
關鍵字: orc、index、row group index、bloom filter index之前的文章《更高的壓縮比,更好的效能–使用ORC檔案格式優化Hive》中介紹了Hive的ORC檔案格式,它不但有著很高的壓縮比,節省儲存和計算資源之外,還通過一個內建的輕量級索引
基於Kafka與Spark的實時大資料質量監控平臺
微軟的ASG (應用與服務集團)包含Bing,、Office,、Skype。每天產生多達5 PB以上資料,如何構建一個高擴充套件性的data audit服務來保證這樣量級的資料完整性和實時性非常具有挑戰性。本文將介紹微軟ASG大資料團隊如何利用Kafka、Spark以及Elasticsear
Spark流式處理框架案例網站流量分析&大資料生態圈介紹
一, 大資料框架(處理海量/流式資料) 1. 以HADOOP 2.x為體系的大資料生態系統處理框架 MapReduce:中間結果儲存在磁碟。Shuffle過程:map將資料寫入到本地磁碟,reduce通過網路的方式到各個map task所執行的機器中拷貝自己要處理的資料。
TOP100summit:【分享實錄-Microsoft】基於Kafka與Spark的實時大資料質量監控平臺
本篇文章內容來自2016年TOP100summit Microsoft資深產品經理邢國冬的案例分享。 編輯:Cynthia 邢國冬(Tony Xing):Microsoft資深產品經理、負責微軟應用與服務集團的大資料平臺構建,資料產品與服務. 導讀:微軟的