
Spark+Kafka實時監控Oracle資料預警
阿新 • • 發佈:2021-02-03
**目標:** 監控Oracle某張記錄表,有新增資料則獲取表資料,並推送到微信企業。
**流程:** Kafka實時監控Oracle指定表,獲取該表操作資訊(日誌),使用Spark Structured Streaming消費Kafka,獲取資料後清洗後存入指定目錄,Python實時監控該目錄,提取文本里面數據並推送到微信。(Oracle一臺伺服器,Kafka及Spark在另外一臺伺服器)
**架構:** Oracle+Kafka+Spark Structured Streaming+Python
 > centos7
> oracle 11g
> apache-maven-3.6.3-bin.tar.gz
> kafka-connect-oracle-master.zip
> hadoop-2.7.1.tar.gz
> kafka_2.11-2.4.1.tgz (scala版本必須與系統及連線spark的jar包一致,這裡是2.11)
> spark-2.4.0-bin-without-hadoop.tgz
> spark-streaming-kafka-0-8_2.11-2.4.0.jar
> Java 1.8
> python 3.6
**一、Oracle側**
這邊設定比較簡單,使用SYS或者SYSTEM賬戶開啟歸檔日誌及附加日誌即可,一般實際工作出於資料安全考慮日誌都會開啟狀態,故不再多贅述,有搭建及開啟問題可以隨時私信。
**二、Kafka側**
①配置maven,並新增進環境變數
```bash
#下載地址:http://maven.apache.org/download.cgi
#解壓 所有配置檔案預設放在/usr/local路徑
tar xvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
#修改環境變數
vi /etc/profile
#加入下面內容
export MAVEN_HOME=/usr/local/apache-maven
export PATH=$PATH:${MAVEN_HOME}/bin
#重新整理配置
source /ect/profile
```
②配置kafka-connect-oracle-master,config檔案按oracle側資訊配置,然後使用maven工具編譯。
```bash
#壓縮包下載地址:https://github.com/erdemcer/kafka-connect-oracle
#解壓
unzip kafka-connect-oracle-master.zip
#修改config下的配置檔案
vi kafka-connect-oracle-master/config/OracleSourceConnector.properties
#修改內容如下:
db.name.alias=dbserver #oracle例項名稱:select instance_name from v$instance
tasks.max=1
topic=cdczztar #kafka主體名稱
db.name=DBSERVER #oracle伺服器:select name from v$database;
db.hostname=192.168.81.159 #oracle伺服器地址
db.port=1521 #oracle埠,一般預設1521
db.user=test #資料庫使用者名稱
db.user.password=123456 #資料庫密碼
db.fetch.size=1
table.whitelist=LINHL.LHL_TEST #需要監控的表名,可以使用*號監控所有,必須大寫
table.blacklist= #不監控的表名,沒有為空,缺少該行會報錯
parse.dml.data=true
reset.offset=true
start.scn=
multitenant=false
#編譯 ,成功會有提示,並生成target資料夾
cd /usr/local/kafka-connect-oracle-master
mvn clean package
```
③解壓kafka,並放入前面master資料夾下的幾個jar包及配置檔案
```bash
#解壓 下載地址:http://kafka.apache.org/downloads
tar xvf kafka_2.11-2.4.1.tgz -C /usr/local/
#改名
mv ./kafka_2.11-2.4.1 ./kafka
#複製配置檔案
cp /usr/local/kafka-connect-oracle-master/target/kafka-connect-oracle-1.0.71.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/lib/ojdbc7.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/config/OracleSourceConnector.properties /usr/local/kafka/config/
```
④開啟Kafka
```bash
#進入Kafka資料夾
cd /usr/local/kafka/bin/
#下面全都在單獨的視窗開啟服務,勿關閉視窗,測試狀態,故沒有在後臺執行
#啟動zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#啟動kafka服務
./kafka-server-start.sh ../config/server.properties
#建立topic-cdczztar
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cdczztar
#檢視所有topic
./kafka-topics.sh --zookeeper localhost:2181 --list
#啟動連線oracle
./connect-standalone.sh ../config/connect-standalone.properties ../config/OracleSourceConnector.properties
#啟動消費端
#消費端此處只是為了展示用,後續使用spark做消費端
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic cdczztar
```
**三、Spark側**
Structured Streaming需要啟用HDFS,這裡都在本地測試環境實現,因此關於java及hadoop的安裝,可以參考這篇的偽分散式配置dblab.xmu.edu.cn/blog/install-hadoop
①配置
```bash
#解壓 #官網可以下載,沒有資源請私信
tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
#重新命名
mv ./spark-2.4.0-bin-without-hadoop ./spark
#修改配置檔案
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vi ./conf/spark-env.sh
#加入下面內容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
#修改系統環境變數
vi /etc/profile
#加入下面內容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_HOME=/opt/java/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:/usr/local/hbase/bin
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:/usr/local/python3/lib/python3.6/site-packages/:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
#更新配置
source /etc/profile
#在jars目錄建立kafka資料夾,把kafka所有jar包放到該目錄
cp /usr/local/spark-streaming-kafka-0-8_2.11-2.4.0.jar /usr/local/spark/jars/kafka
cp /usr/local/kafka/libs/* /usr/local/spark/jars/kafka
```
②Structured Streaming指令碼建立
```python
#!/usr/bin/env python3
import re
from functools import partial
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredKafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN') #只提示警示資訊
lines = spark \ #使用spark streaming則是基於KakfkaUtils包使用createDirectStream
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", 'cdczztar') \ #要消費的topic
.load().selectExpr("CAST(value AS STRING)")
#lines.printSchema()
#正則處理,根據實際資料處理,kafka獲取後是oracle日誌,在這隻提取表插入的值
pattern = 'data":(.+)}'
fields = partial(regexp_extract, str="value", pattern=pattern)
words = lines.select(fields(idx=1).alias("values"))
#輸出模式:存入檔案
query = words \
.writeStream \
.outputMode("append") \
.format("csv") \
.option("path","file:///tmp/filesink") \ #存到伺服器地址
.option("checkpointLocation","file:///tmp/file-sink-cp") \
.trigger(processingTime="10 seconds") \
.start()
query.awaitTermination()
#新開一個伺服器視窗執行,這邊已經在程式碼目錄下
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 spark.py
```
③執行python實時開啟寫入的檔案,提取資訊並推送到微信端
```python
import csv
import pyinotify #這個包只支援linux,如果是window系統可以使用watchdog,一個原理及寫法
import time
import requests
import json
import datetime
import pandas as pd
CORPID = "******" #企業微信id
SECRET = "*******" #企業微信金鑰
AGENTID = 1000041 #企業微信埠
multi_event = pyinotify.IN_CREATE #只對create這個動作做監控
wm = pyinotify.WatchManager()
#繼承ProcessEvent後,對process_IN_CREATE方法重寫
class MyHandler(pyinotify.ProcessEvent):
def send_msg_to_wechat(self, content):
record = '{}\n'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
s = requests.session()
url1 = "https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={0}&corpsecret={1}".format(CORPID, SECRET)
rep = s.get(url1)
record += "{}\n".format(json.loads(rep.content))
if rep.status_code == 200:
token = json.loads(rep.content)['access_token']
record += "獲取token成功\n"
else:
record += "獲取token失敗\n"
token = None
url2 = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={}".format(token)
header = {
"Content-Type": "application/json"
}
form_data = {
"touser": "@all",
"toparty": " PartyID1 | PartyID2 ",
"totag": " TagID1 | TagID2 ",
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
rep = s.post(url2, data=json.dumps(form_data).encode('utf-8'), headers=header)
if rep.status_code == 200:
res = json.loads(rep.content)
record += "傳送成功\n"
else:
record += "傳送失敗\n"
res = None
return res
def process_IN_CREATE(self, event):
try:
if '_spark_metadata' in event.pathname or '.crc' in event.pathname:
pass
else:
print(event.pathname)
f_path = event.pathname
#此處坑,streaming那邊生成檔案還沒寫入資料就會觸發該任務,不sleep開啟的是空白檔案
time.sleep(5)
df = pd.read_csv(r'' + f_path, encoding='utf8', names=['value'], sep='/')
send_str = df.iloc[0, 0].replace('\\', '').replace(',"before":null}', '').replace('"','')
print(send_str)
self.send_msg_to_wechat('中間庫預警:' + send_str)
except:
pass
handler = MyHandler()
notifier = pyinotify.Notifier(wm,handler)
wm.add_watch('/tmp/filesink/',multi_event)
notifier.loop()
```
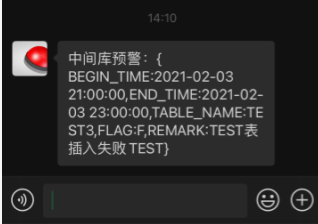
微信端訊息如下:
**四、問題點**
還有下面幾個問題還沒實現,有思路還請隨時評論私信交流,感謝
- 在structured streaming消費了kafka資訊後,是否可以直接把訊息推送到微信埠?
- python監控檔案有新增檔案路徑可以即時獲取,但是要獲取內容需要等待資料寫入,sleep的方式不穩定,是否有方法可以判斷資料已經寫完就讀取該檔案?
***
學習交流,有任何問題還請隨時評論指出
> centos7
> oracle 11g
> apache-maven-3.6.3-bin.tar.gz
> kafka-connect-oracle-master.zip
> hadoop-2.7.1.tar.gz
> kafka_2.11-2.4.1.tgz (scala版本必須與系統及連線spark的jar包一致,這裡是2.11)
> spark-2.4.0-bin-without-hadoop.tgz
> spark-streaming-kafka-0-8_2.11-2.4.0.jar
> Java 1.8
> python 3.6
**一、Oracle側**
這邊設定比較簡單,使用SYS或者SYSTEM賬戶開啟歸檔日誌及附加日誌即可,一般實際工作出於資料安全考慮日誌都會開啟狀態,故不再多贅述,有搭建及開啟問題可以隨時私信。
**二、Kafka側**
①配置maven,並新增進環境變數
```bash
#下載地址:http://maven.apache.org/download.cgi
#解壓 所有配置檔案預設放在/usr/local路徑
tar xvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
#修改環境變數
vi /etc/profile
#加入下面內容
export MAVEN_HOME=/usr/local/apache-maven
export PATH=$PATH:${MAVEN_HOME}/bin
#重新整理配置
source /ect/profile
```
②配置kafka-connect-oracle-master,config檔案按oracle側資訊配置,然後使用maven工具編譯。
```bash
#壓縮包下載地址:https://github.com/erdemcer/kafka-connect-oracle
#解壓
unzip kafka-connect-oracle-master.zip
#修改config下的配置檔案
vi kafka-connect-oracle-master/config/OracleSourceConnector.properties
#修改內容如下:
db.name.alias=dbserver #oracle例項名稱:select instance_name from v$instance
tasks.max=1
topic=cdczztar #kafka主體名稱
db.name=DBSERVER #oracle伺服器:select name from v$database;
db.hostname=192.168.81.159 #oracle伺服器地址
db.port=1521 #oracle埠,一般預設1521
db.user=test #資料庫使用者名稱
db.user.password=123456 #資料庫密碼
db.fetch.size=1
table.whitelist=LINHL.LHL_TEST #需要監控的表名,可以使用*號監控所有,必須大寫
table.blacklist= #不監控的表名,沒有為空,缺少該行會報錯
parse.dml.data=true
reset.offset=true
start.scn=
multitenant=false
#編譯 ,成功會有提示,並生成target資料夾
cd /usr/local/kafka-connect-oracle-master
mvn clean package
```
③解壓kafka,並放入前面master資料夾下的幾個jar包及配置檔案
```bash
#解壓 下載地址:http://kafka.apache.org/downloads
tar xvf kafka_2.11-2.4.1.tgz -C /usr/local/
#改名
mv ./kafka_2.11-2.4.1 ./kafka
#複製配置檔案
cp /usr/local/kafka-connect-oracle-master/target/kafka-connect-oracle-1.0.71.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/lib/ojdbc7.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/config/OracleSourceConnector.properties /usr/local/kafka/config/
```
④開啟Kafka
```bash
#進入Kafka資料夾
cd /usr/local/kafka/bin/
#下面全都在單獨的視窗開啟服務,勿關閉視窗,測試狀態,故沒有在後臺執行
#啟動zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#啟動kafka服務
./kafka-server-start.sh ../config/server.properties
#建立topic-cdczztar
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cdczztar
#檢視所有topic
./kafka-topics.sh --zookeeper localhost:2181 --list
#啟動連線oracle
./connect-standalone.sh ../config/connect-standalone.properties ../config/OracleSourceConnector.properties
#啟動消費端
#消費端此處只是為了展示用,後續使用spark做消費端
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic cdczztar
```
**三、Spark側**
Structured Streaming需要啟用HDFS,這裡都在本地測試環境實現,因此關於java及hadoop的安裝,可以參考這篇的偽分散式配置dblab.xmu.edu.cn/blog/install-hadoop
①配置
```bash
#解壓 #官網可以下載,沒有資源請私信
tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
#重新命名
mv ./spark-2.4.0-bin-without-hadoop ./spark
#修改配置檔案
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vi ./conf/spark-env.sh
#加入下面內容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
#修改系統環境變數
vi /etc/profile
#加入下面內容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_HOME=/opt/java/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:/usr/local/hbase/bin
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:/usr/local/python3/lib/python3.6/site-packages/:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
#更新配置
source /etc/profile
#在jars目錄建立kafka資料夾,把kafka所有jar包放到該目錄
cp /usr/local/spark-streaming-kafka-0-8_2.11-2.4.0.jar /usr/local/spark/jars/kafka
cp /usr/local/kafka/libs/* /usr/local/spark/jars/kafka
```
②Structured Streaming指令碼建立
```python
#!/usr/bin/env python3
import re
from functools import partial
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredKafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN') #只提示警示資訊
lines = spark \ #使用spark streaming則是基於KakfkaUtils包使用createDirectStream
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", 'cdczztar') \ #要消費的topic
.load().selectExpr("CAST(value AS STRING)")
#lines.printSchema()
#正則處理,根據實際資料處理,kafka獲取後是oracle日誌,在這隻提取表插入的值
pattern = 'data":(.+)}'
fields = partial(regexp_extract, str="value", pattern=pattern)
words = lines.select(fields(idx=1).alias("values"))
#輸出模式:存入檔案
query = words \
.writeStream \
.outputMode("append") \
.format("csv") \
.option("path","file:///tmp/filesink") \ #存到伺服器地址
.option("checkpointLocation","file:///tmp/file-sink-cp") \
.trigger(processingTime="10 seconds") \
.start()
query.awaitTermination()
#新開一個伺服器視窗執行,這邊已經在程式碼目錄下
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 spark.py
```
③執行python實時開啟寫入的檔案,提取資訊並推送到微信端
```python
import csv
import pyinotify #這個包只支援linux,如果是window系統可以使用watchdog,一個原理及寫法
import time
import requests
import json
import datetime
import pandas as pd
CORPID = "******" #企業微信id
SECRET = "*******" #企業微信金鑰
AGENTID = 1000041 #企業微信埠
multi_event = pyinotify.IN_CREATE #只對create這個動作做監控
wm = pyinotify.WatchManager()
#繼承ProcessEvent後,對process_IN_CREATE方法重寫
class MyHandler(pyinotify.ProcessEvent):
def send_msg_to_wechat(self, content):
record = '{}\n'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
s = requests.session()
url1 = "https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={0}&corpsecret={1}".format(CORPID, SECRET)
rep = s.get(url1)
record += "{}\n".format(json.loads(rep.content))
if rep.status_code == 200:
token = json.loads(rep.content)['access_token']
record += "獲取token成功\n"
else:
record += "獲取token失敗\n"
token = None
url2 = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={}".format(token)
header = {
"Content-Type": "application/json"
}
form_data = {
"touser": "@all",
"toparty": " PartyID1 | PartyID2 ",
"totag": " TagID1 | TagID2 ",
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
rep = s.post(url2, data=json.dumps(form_data).encode('utf-8'), headers=header)
if rep.status_code == 200:
res = json.loads(rep.content)
record += "傳送成功\n"
else:
record += "傳送失敗\n"
res = None
return res
def process_IN_CREATE(self, event):
try:
if '_spark_metadata' in event.pathname or '.crc' in event.pathname:
pass
else:
print(event.pathname)
f_path = event.pathname
#此處坑,streaming那邊生成檔案還沒寫入資料就會觸發該任務,不sleep開啟的是空白檔案
time.sleep(5)
df = pd.read_csv(r'' + f_path, encoding='utf8', names=['value'], sep='/')
send_str = df.iloc[0, 0].replace('\\', '').replace(',"before":null}', '').replace('"','')
print(send_str)
self.send_msg_to_wechat('中間庫預警:' + send_str)
except:
pass
handler = MyHandler()
notifier = pyinotify.Notifier(wm,handler)
wm.add_watch('/tmp/filesink/',multi_event)
notifier.loop()
```
微信端訊息如下:

**四、問題點**
還有下面幾個問題還沒實現,有思路還請隨時評論私信交流,感謝
- 在structured streaming消費了kafka資訊後,是否可以直接把訊息推送到微信埠?
- python監控檔案有新增檔案路徑可以即時獲取,但是要獲取內容需要等待資料寫入,sleep的方式不穩定,是否有方法可以判斷資料已經寫完就讀取該檔案?
***
學習交流,有任何問題還請隨時評論指出
> centos7
> oracle 11g
> apache-maven-3.6.3-bin.tar.gz
> kafka-connect-oracle-master.zip
> hadoop-2.7.1.tar.gz
> kafka_2.11-2.4.1.tgz (scala版本必須與系統及連線spark的jar包一致,這裡是2.11)
> spark-2.4.0-bin-without-hadoop.tgz
> spark-streaming-kafka-0-8_2.11-2.4.0.jar
> Java 1.8
> python 3.6
**一、Oracle側**
這邊設定比較簡單,使用SYS或者SYSTEM賬戶開啟歸檔日誌及附加日誌即可,一般實際工作出於資料安全考慮日誌都會開啟狀態,故不再多贅述,有搭建及開啟問題可以隨時私信。
**二、Kafka側**
①配置maven,並新增進環境變數
```bash
#下載地址:http://maven.apache.org/download.cgi
#解壓 所有配置檔案預設放在/usr/local路徑
tar xvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
#修改環境變數
vi /etc/profile
#加入下面內容
export MAVEN_HOME=/usr/local/apache-maven
export PATH=$PATH:${MAVEN_HOME}/bin
#重新整理配置
source /ect/profile
```
②配置kafka-connect-oracle-master,config檔案按oracle側資訊配置,然後使用maven工具編譯。
```bash
#壓縮包下載地址:https://github.com/erdemcer/kafka-connect-oracle
#解壓
unzip kafka-connect-oracle-master.zip
#修改config下的配置檔案
vi kafka-connect-oracle-master/config/OracleSourceConnector.properties
#修改內容如下:
db.name.alias=dbserver #oracle例項名稱:select instance_name from v$instance
tasks.max=1
topic=cdczztar #kafka主體名稱
db.name=DBSERVER #oracle伺服器:select name from v$database;
db.hostname=192.168.81.159 #oracle伺服器地址
db.port=1521 #oracle埠,一般預設1521
db.user=test #資料庫使用者名稱
db.user.password=123456 #資料庫密碼
db.fetch.size=1
table.whitelist=LINHL.LHL_TEST #需要監控的表名,可以使用*號監控所有,必須大寫
table.blacklist= #不監控的表名,沒有為空,缺少該行會報錯
parse.dml.data=true
reset.offset=true
start.scn=
multitenant=false
#編譯 ,成功會有提示,並生成target資料夾
cd /usr/local/kafka-connect-oracle-master
mvn clean package
```
③解壓kafka,並放入前面master資料夾下的幾個jar包及配置檔案
```bash
#解壓 下載地址:http://kafka.apache.org/downloads
tar xvf kafka_2.11-2.4.1.tgz -C /usr/local/
#改名
mv ./kafka_2.11-2.4.1 ./kafka
#複製配置檔案
cp /usr/local/kafka-connect-oracle-master/target/kafka-connect-oracle-1.0.71.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/lib/ojdbc7.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/config/OracleSourceConnector.properties /usr/local/kafka/config/
```
④開啟Kafka
```bash
#進入Kafka資料夾
cd /usr/local/kafka/bin/
#下面全都在單獨的視窗開啟服務,勿關閉視窗,測試狀態,故沒有在後臺執行
#啟動zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#啟動kafka服務
./kafka-server-start.sh ../config/server.properties
#建立topic-cdczztar
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cdczztar
#檢視所有topic
./kafka-topics.sh --zookeeper localhost:2181 --list
#啟動連線oracle
./connect-standalone.sh ../config/connect-standalone.properties ../config/OracleSourceConnector.properties
#啟動消費端
#消費端此處只是為了展示用,後續使用spark做消費端
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic cdczztar
```
**三、Spark側**
Structured Streaming需要啟用HDFS,這裡都在本地測試環境實現,因此關於java及hadoop的安裝,可以參考這篇的偽分散式配置dblab.xmu.edu.cn/blog/install-hadoop
①配置
```bash
#解壓 #官網可以下載,沒有資源請私信
tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
#重新命名
mv ./spark-2.4.0-bin-without-hadoop ./spark
#修改配置檔案
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vi ./conf/spark-env.sh
#加入下面內容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
#修改系統環境變數
vi /etc/profile
#加入下面內容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_HOME=/opt/java/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:/usr/local/hbase/bin
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:/usr/local/python3/lib/python3.6/site-packages/:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
#更新配置
source /etc/profile
#在jars目錄建立kafka資料夾,把kafka所有jar包放到該目錄
cp /usr/local/spark-streaming-kafka-0-8_2.11-2.4.0.jar /usr/local/spark/jars/kafka
cp /usr/local/kafka/libs/* /usr/local/spark/jars/kafka
```
②Structured Streaming指令碼建立
```python
#!/usr/bin/env python3
import re
from functools import partial
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredKafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN') #只提示警示資訊
lines = spark \ #使用spark streaming則是基於KakfkaUtils包使用createDirectStream
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", 'cdczztar') \ #要消費的topic
.load().selectExpr("CAST(value AS STRING)")
#lines.printSchema()
#正則處理,根據實際資料處理,kafka獲取後是oracle日誌,在這隻提取表插入的值
pattern = 'data":(.+)}'
fields = partial(regexp_extract, str="value", pattern=pattern)
words = lines.select(fields(idx=1).alias("values"))
#輸出模式:存入檔案
query = words \
.writeStream \
.outputMode("append") \
.format("csv") \
.option("path","file:///tmp/filesink") \ #存到伺服器地址
.option("checkpointLocation","file:///tmp/file-sink-cp") \
.trigger(processingTime="10 seconds") \
.start()
query.awaitTermination()
#新開一個伺服器視窗執行,這邊已經在程式碼目錄下
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 spark.py
```
③執行python實時開啟寫入的檔案,提取資訊並推送到微信端
```python
import csv
import pyinotify #這個包只支援linux,如果是window系統可以使用watchdog,一個原理及寫法
import time
import requests
import json
import datetime
import pandas as pd
CORPID = "******" #企業微信id
SECRET = "*******" #企業微信金鑰
AGENTID = 1000041 #企業微信埠
multi_event = pyinotify.IN_CREATE #只對create這個動作做監控
wm = pyinotify.WatchManager()
#繼承ProcessEvent後,對process_IN_CREATE方法重寫
class MyHandler(pyinotify.ProcessEvent):
def send_msg_to_wechat(self, content):
record = '{}\n'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
s = requests.session()
url1 = "https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={0}&corpsecret={1}".format(CORPID, SECRET)
rep = s.get(url1)
record += "{}\n".format(json.loads(rep.content))
if rep.status_code == 200:
token = json.loads(rep.content)['access_token']
record += "獲取token成功\n"
else:
record += "獲取token失敗\n"
token = None
url2 = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={}".format(token)
header = {
"Content-Type": "application/json"
}
form_data = {
"touser": "@all",
"toparty": " PartyID1 | PartyID2 ",
"totag": " TagID1 | TagID2 ",
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
rep = s.post(url2, data=json.dumps(form_data).encode('utf-8'), headers=header)
if rep.status_code == 200:
res = json.loads(rep.content)
record += "傳送成功\n"
else:
record += "傳送失敗\n"
res = None
return res
def process_IN_CREATE(self, event):
try:
if '_spark_metadata' in event.pathname or '.crc' in event.pathname:
pass
else:
print(event.pathname)
f_path = event.pathname
#此處坑,streaming那邊生成檔案還沒寫入資料就會觸發該任務,不sleep開啟的是空白檔案
time.sleep(5)
df = pd.read_csv(r'' + f_path, encoding='utf8', names=['value'], sep='/')
send_str = df.iloc[0, 0].replace('\\', '').replace(',"before":null}', '').replace('"','')
print(send_str)
self.send_msg_to_wechat('中間庫預警:' + send_str)
except:
pass
handler = MyHandler()
notifier = pyinotify.Notifier(wm,handler)
wm.add_watch('/tmp/filesink/',multi_event)
notifier.loop()
```
微信端訊息如下:

**四、問題點**
還有下面幾個問題還沒實現,有思路還請隨時評論私信交流,感謝
- 在structured streaming消費了kafka資訊後,是否可以直接把訊息推送到微信埠?
- python監控檔案有新增檔案路徑可以即時獲取,但是要獲取內容需要等待資料寫入,sleep的方式不穩定,是否有方法可以判斷資料已經寫完就讀取該檔案?
***
學習交流,有任何問題還請隨時評論指出