
資料結構——Huffman編碼及譯碼
Huffman編碼及譯碼
1.掌握二叉樹的二叉連結串列存貯結構。
2.掌握Huffman演算法。
要求:
使用檔案儲存初始的文字資料及最終的結果。
- 檔名為inputfile1.txt的檔案儲存的是一段英文短文;
- 檔名為inputfile2.txt的檔案儲存01形式的編碼段;
- 檔名為outputfile1.txt的檔案儲存各字元的出現次數和對應的編碼;
- 檔名為outputfile2.txt的檔案儲存對應於inputfile2.txt的譯碼結果。
統計inputfile1.txt中各字元的出現頻率,並據此構造Huffman樹,編制Huffman 碼;根據已經得到的編碼,對01形式的編碼段進行譯碼。
具體的要求:
1.將給定字元檔案編碼,生成編碼,輸出每個字元出現的次數和編碼;
2.將給定編碼檔案譯碼,生成字元,輸出編碼及其對應字元。
輸入資料格式:
詳見要求部分。
輸出資料格式:
outputfile1.txt檔案中:
字元 出現次數 對應的編碼
a 37 010
b 130 00
outputfile2.txt檔案中:
This is a example.
分析(如何構造哈夫曼樹):
假設有n個權值,則構造出的哈夫曼樹有n個葉子結點。 n個權值分別設為 w1、w2、…、wn,則哈夫曼樹的構造規則為:
(1) 將w1、w2、…,wn看成是有n 棵樹的森林(每棵樹僅有一個結點);
(2) 在森林中選出兩個根結點的權值最小的樹合併,作為一棵新樹的左、右子樹,且新樹的根結點權值為其左、右子樹根結點權值之和;
(3)從森林中刪除選取的兩棵樹,並將新樹加入森林;
(4)重複(2)、(3)步,直到森林中只剩一棵樹為止,該樹即為所求得的哈夫曼樹。
如:對 下圖中的六個帶權葉子結點來構造一棵哈夫曼樹,步驟如下(借用一下他人好看的圖):
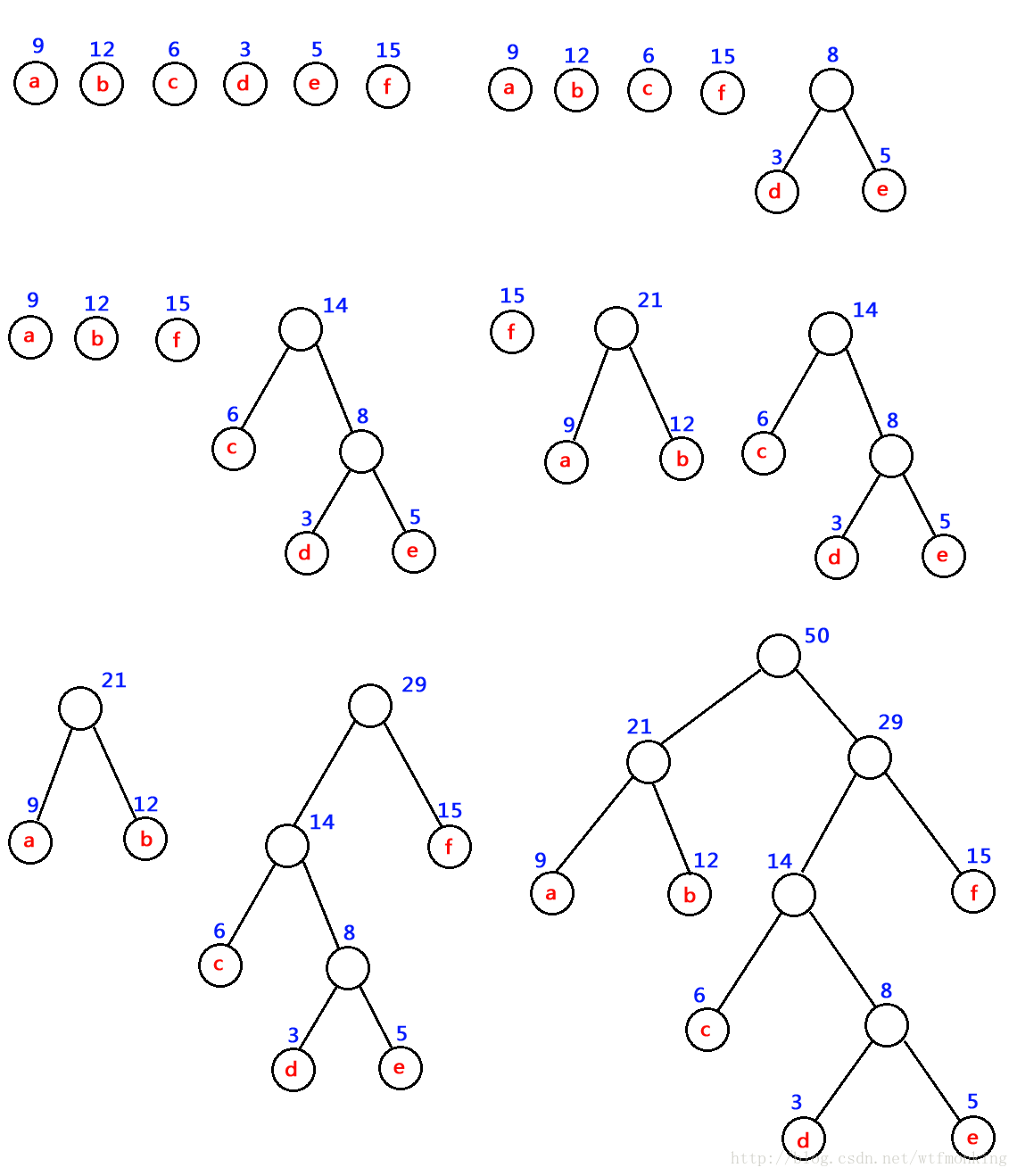
程式碼如下(vs2012):
#include<iostream> #include<fstream> #include<string> using namespace std; struct Huffmannode { int parent; int lc; int rc; int weight; }; class Huffmantree { private: Huffmannode*node; char* letter; int leafnum; public: Huffmantree(); ~Huffmantree(); Huffmannode*Initialization(int sum, char z[], int w[]); void Encord(Huffmannode*node, char tree[], int sum, char z[], int w[]); void Decord(Huffmannode*node, int sum, char z[]); }; Huffmantree::Huffmantree() { node = NULL; letter = NULL; leafnum = 0; } Huffmantree::~Huffmantree() { delete[]node; delete[]letter; } Huffmannode*Huffmantree::Initialization(int sum, char z[], int w[]) { int min1, min2; int loc1, loc2; node = new Huffmannode[2 * sum - 1]; letter = new char[2 * sum - 1]; for (int i = 0; i<sum; i++) { letter[i] = z[i]; node[i].weight = w[i]; node[i].parent = -1; node[i].lc = -1; node[i].rc = -1; } for (int i = sum; i<2 * sum - 1; i++) { loc1 = -1; loc2 = -1; min1 = 32767; min2 = 32767; for (int j = 0; j<i; j++) { if (node[j].parent == -1) { if (node[j].weight<min1) { min2 = min1; min1 = node[j].weight; loc2 = loc1; loc1 = j; } else { if (node[j].weight<min2) { min2 = node[j].weight; loc2 = j; } } } } node[loc1].parent = i; node[loc2].parent = i; node[i].lc = loc1; node[i].rc = loc2; node[i].parent = -1; node[i].weight = node[loc1].weight + node[loc2].weight; } return node; } void Huffmantree::Encord(Huffmannode*node, char t[], int sum, char z[], int w[]) { char* code; code = new char[sum]; int m = 0; int i, n = 0; ofstream shuchu; shuchu.open("outputfile1.txt", ios::app); while (z[n] != '\0') { int r, k = 0, q; r = n; q = n; shuchu << z[n] << " " << w[n] << " "; while (node[r].parent != -1) { r = node[r].parent; if (node[r].lc == q) { code[k] = '0'; k++; } else { code[k] = '1'; k++; } q = r; } code[k] = '\0'; k -= 1; while (k >= 0) { shuchu << code[k]; k--; } shuchu << '\n'; n++; } shuchu.close(); ofstream out; out.open("inputfile2.txt", ios::app); while (t[m] != '\0') { int j, s = 0; for (i = 0; i<sum; i++) { if (t[m] == z[i])break; } j = i; while (node[j].parent != -1) { j = node[j].parent; if (node[j].lc == i) { code[s] = '0'; s++; } else { code[s] = '1'; s++; } i = j; } code[s] = '\0'; s -= 1; while (s >= 0) { out << code[s]; s--; } m++; } out.close(); } void Huffmantree::Decord(Huffmannode *node, int sum, char z[]) { ifstream tree("inputfile2.txt"); int k = 0; char *code = new char[1000]; while (!tree.eof()) { tree >> code[k]; k++; } code[k] = '\0'; tree.close(); ofstream yima("outputfile2.txt", ios::app); k = 0; int j = 2 * sum - 1 - 1; while (code[k + 1] != '\0') { if (code[k] == '0') { j = node[j].lc; } if (code[k] == '1') { j = node[j].rc; } if (node[j].lc == -1) { yima << z[j]; j = 2 * sum - 1 - 1; } k++; } yima.close(); } int main() { ifstream in("inputfile1.txt", ios::app); char tree[1000] = { 0 }; char letter[100]; int count[100] = { 0 }; int i = 0, t = 0; while (!in.eof()) { tree[t] = in.get(); t++; } tree[t] = '\0'; int k = 0; in.close(); while (tree[i] != '\0') { int m = 0; for (int j = 0; j<k; j++) { if (tree[i] == letter[j]) { count[j]++; m = 1; } } if (m == 0) { letter[k] = tree[i]; count[k]++; k++; } i++; } count[k] = '\0'; letter[k] = '\0'; Huffmantree tree1; Huffmannode*node = tree1.Initialization(k, letter, count); tree1.Encord(node, tree, k, letter, count); tree1.Decord(node, k, letter); }
相關推薦
資料結構——Huffman編碼及譯碼
Huffman編碼及譯碼 1.掌握二叉樹的二叉連結串列存貯結構。 2.掌握Huffman演算法。 要求: 使用檔案儲存初始的文字資料及最終的結果。 檔名為inputfile1.txt的檔案儲存的是一段英文短文; 檔名為inputfile2.txt的檔案儲存01
【資料結構--Huffman編碼】優先佇列+棧實現
#include<bits/stdc++.h> using namespace std; typedef struct{ int weight; int id; int par,lchild,rchild; }HTNode,*HuffmanTr
資料結構與演算法內功修煉之——為什麼學習資料結構和演算法及如何高效的學習資料結構和演算法
什麼是資料結構和演算法 用一句話總結資料結構和演算法,資料結構和演算法是用來儲存資料和處理資料的;其中的儲存指的是通過怎樣的儲存結構來儲存資料,而處理就是通過怎樣的方式或者方法處理資料 為什麼學習資料結構和演算法 寫出更加高效能的程式碼 演算法,是一種解決問題的思路
[資料結構]Trie簡介及Python實現
Trie簡介及Python實現 Trie簡介 Python實現 Trie簡介 Trie即字首樹或字典樹,利用字串公共字首降低搜尋時間。速度為 O
SWUST資料結構--哈夫曼譯碼
const int maxvalue=100; const int maxbit=100; const int maxn=100; #include "iostream" #include "stdio.h" #include "stdlib.h" using namespace std; stru
資料結構:棧及應用
棧的定義: 棧是隻能在一端進行資料插入和刪除的線性表。 棧的性質: 後進先出(FILO),後面進去的元素,先出來,先進去的元素後出來 棧的操作: 棧的操作很簡單,就是
Java資料結構-陣列解析及類封裝自定義陣列實現
概念: 陣列是Java資料結構中最基本的資料,是儲存 一組長度固定的 同資料型別的集合。 優點: 插入快:對於無序陣列,只需要在陣列末尾增加資料即可。但對於有序陣列,需要查詢到固定的位置,再插入資料,相對無序陣列 結構簡單 缺點: 根據元素值查
Python資料結構——解析樹及樹的遍歷
解析樹 完成樹的實現之後,現在我們來看一個例子,告訴你怎麼樣利用樹去解決一些實際問題。在這個章節,我們來研究解析樹。解析樹常常用於真實世界的結構表示,例如句子或數學表示式。 圖 1:一個簡單句的解析樹 圖 1 顯示了一個簡單句的層級結構。將一個句子表示為一個樹,能使我們通過利用子樹來處理句子中的每個獨立的
重溫資料結構:樹 及 Java 實現
讀完本文你將瞭解到: 資料結構,指的是資料的儲存形式,常見的有線性結構(陣列、連結串列,佇列、棧),還有非線性結構(樹、圖等)。 今天我們來學習下資料結構中的 樹。 什麼是樹 線性結構中,一個節點至多隻有一個頭節點,至多隻有一個尾節點,彼此連線
《資料結構演算法實現及解析》電子書下載 -(百度網盤 高清版PDF格式)
作者:高一凡 副書名:配合嚴蔚敏、吳偉民編著的《資料結構》(C語言版) 出版日期:2002-10-1 出版社:其它 頁數:450 ISBN:7-5606-1176-1/TP*0608 檔案格式:PDF 檔案大小:8
縮短迴圈碼(26,16)的編碼及譯碼 -- BCH(26,16)
BCH(26,16)編碼與譯碼 我們知道BCH(26,16)的資訊位是前面16位,而校驗位是後面10位。可以修正2位或者1位的隨機錯誤。 其校驗方法與<a href="http://blog.csdn.net/woijal520/article/details/679
【資料結構】棧及棧的應用
棧 棧是一種先進後出的的特殊線性表,只允許在固定的一端進行插入和刪除元素操作,進行輸入插入和刪除操作的一端稱為棧頂,另一端稱為棧底 下面採用靜態順序表實現的方式簡單封裝一個棧 儲存方式 #define MAX_SIZE 100 typedef int DataT
C語言-資料結構-插入排序及優化-原始碼
1. 插入排序的定義及複雜度插入排序的基本思想是:每步將一個待排序的紀錄,按其關鍵碼值的大小插入前面已經排序的檔案中適當位置上,直到全部插入完為止。其時間複雜度為O(n^2)。2. 原始碼執行結果如下圖
線性表資料結構型別定義及相關操作總結
1、順序儲存結構(如陣列) 定義: #define MAXSIZE 20 typedef struct{ int data[MAXSIZE]; //假設這裡是整型 int length; //線性表長度 }; 讀取其中某個元素:假設線性順序表已存在,讀取其中第i個元素
資料結構之棧及Java實現
一、棧的基本介紹 棧是一種只允許在一端進行插入或刪除的線性表,也就是說先進後出。棧的操作端通常被稱為棧頂,另一端被稱為棧底,棧的插入操作稱為壓棧(push),棧刪除操作稱為出棧(pop)。壓棧是把新元素放到棧頂元素的上面,使之成為新的棧頂元素;出棧則是把棧頂元
資料結構--樹型別及樹的基本概念
資料結構中的幾種樹 序號 型別 具體型別 具體型別 具體型別 具體型別 具體型別 1 二叉樹 ⑴二叉樹 ⑵二叉查詢樹 ⑶笛卡爾樹 ⑷T樹
資料結構之一準備及預熱3
6.其他知識補充 資料結構: 資料結構是指相互之間存在一種或多種特定關係的資料元素的集合。 資料結構包括3個方面的內容:邏輯結構、儲存結構、對資料的運算 資料的邏輯結構 資料的邏輯結構是對資料之間關係的描述,它與資料的儲存結構
資料結構之一準備及預熱
1.介面 介面可以理解為使用者和函式打交道的地方,通過介面使用者輸入了自己的資料,得到了自己想要的結果 2.在進行演算法設計題中的程式碼書寫時,只需寫出一個或多個可以解決問題的有著清楚介面描述的函式即可。 3.資料型別 對於基本資料型別,
動圖+原始碼,演示Java中常用資料結構執行過程及原理
最近在整理資料結構方面的知識, 系統化看了下Java中常用資料結構, 突發奇想用動畫來繪製資料流轉過程. 主要基於jdk8, 可能會有些特性與jdk7之前不相同, 例如LinkedList LinkedHashMap中的雙向列表不再是迴環的. HashMap中的單鏈表是尾插, 而不是頭插入等等, 後文不再贅敘
【圖解資料結構】樹及樹的遍歷
當你第一次學習編碼時,大部分人都是將陣列作為主要資料結構來學習。 之後,你將會學習到雜湊表。如果你是計算機專業的,你肯定需要選修一門資料結構的課程。上課時,你又會學習到連結串列,佇列和棧等資料結構。這些都被統稱為線性的資料結構,因為它們在邏輯上都有起點和終點。 當你開始學習樹和圖的資料結構時,你會覺得它是